[論文メモ] LEARNING TO MERGE TOKENS IN VISION TRANSFORMERS
Google Research
Vision Transformer(ViT)の内部でパッチを結合するPatch Margerを提案。
Transformerはアーキテクチャの大きさに(ある程度)比例してパフォーマンスが向上するがその分計算コストがかかる。
パッチを減らせれば計算コストを抑えられる。
手法
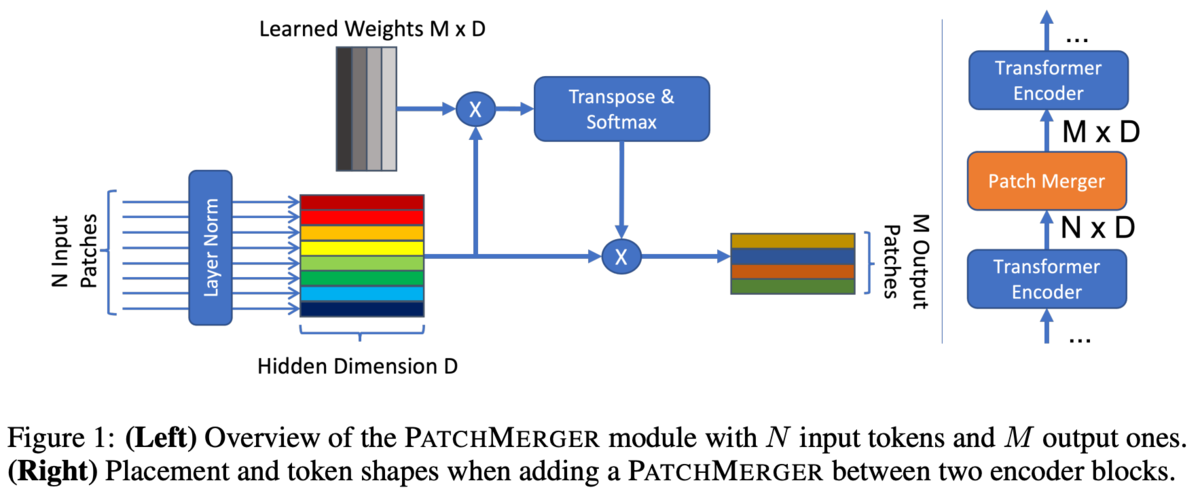
PatchMagerでは個のパッチを出力する。
あるパッチが入力されると、PatchMargerはそのパッチに対する
個のスコアを出力する(
)。これは線形変換で行われる。
スコアの合計が1になるようにSoftmax()で正規化する(
)。
このスコアは出力の個のパッチへのパッチ
の寄与度。
各パッチについて寄与度を計算し、寄与度で重み付けすることで新しいパッチとする。
考察
PatchMagerはパッチに対する線形変換でスコアを算出するため似たパッチは同じ寄与度になり、同じ背景から生まれた冗長なパッチはマージされパッチが減る(後の計算コストが減る)。
新しいパッチは古いパッチの線形結合で、もとの位置情報とは無関係。
入力パッチは可変長だが、学習時とあまりにもかけ離れたパッチ数だとスケールが壊れる恐れがある。そのために、PatchMargerの前にLayer Normを挟むことでその影響を軽減している。
PatchMagerはクエリ部分を学習可能パラメータにしスケーリングをなくしたAttentionと似ている。


なのでTransformer Blockの一部を置き換えようと思ったが不安定だったのでPatchMargerモジュールにした。
実験・結果
基本のアーキテクチャは偶数のTransformer Blockを持っているので、基本的にPatchMargerはその中間に設置し、出力するパッチは8。
Small、Base、Large、Hugeの4つの異なる設定で実験。
各設定のepoch数、パッチサイズ、トークン数は
Small : 5epoch、(32, 32)、49トークン
Base: 7epoch、(32, 32)、49トークン
Large: 14epoch、(16, 16)、196トークン
Huge: 14epoch、(14, 14)、256トークン
なお、CLSトークンは別。



12BlocksのモデルでPatchMargerの設置する位置の変化。基本後ろの方が良いが計算コストの問題がある。
10~11の間で落ちるのが面白い


所感
この間読んだのによく似ている。
ninhydrin.hatenablog.com
流行りなのか似たようなのが出たので急いで出したのかは不明。
あちらはAttentionを使い出力がある程度可変なのに対して、こちらは単純な重み付けで出力は固定長。どちらも一長一短な気がして、どちらが良いのかはわからない。
どのパッチがどれくらいの寄与度なのかの可視化とか見てみたい。あちらは出していた。
またこちらは寄与度からパッチ同士の類似度も計算できるはずなのでそれも見てみたかった。