[論文メモ] DaViT: Dual Attention Vision Transformers
空間方向だけでなくチャンネル方向のself-attentionも導入することでglobal contextを扱えるようにした。
Vision Transformer(ViT)は画像をオーバーラップなしのパッチに切り出して、それをシーケンスとみなしてself-attention(SA)を行うが計算コストが高く解像度が高いと厳しい。
Swin Transformerなどで導入されたlocal attentionは切り出したパッチをグループにまとめそのグループ内でSAすることでコストを抑えたがグループ同士のインタラクションが必要になる。
これらのピクセルレベル・パッチレベルSAの手法とは違った、計算コストもそれほど多くなくglobal contextを扱える画像レベルSAを作れないか?というお気持ち。
手法
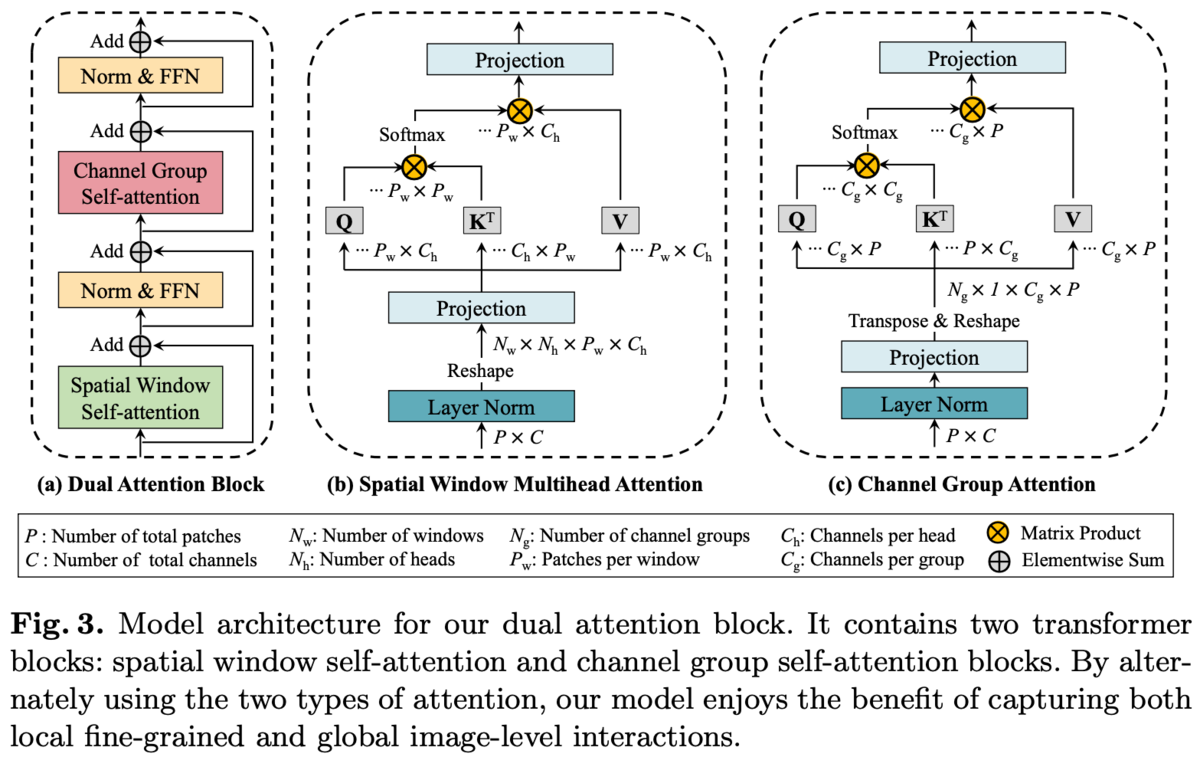
空間方向だけではなく、チャンネル方向のSAも導入したDual Attention Blockを提案
Dual Attention Blockの構造を図3(a)に示す。
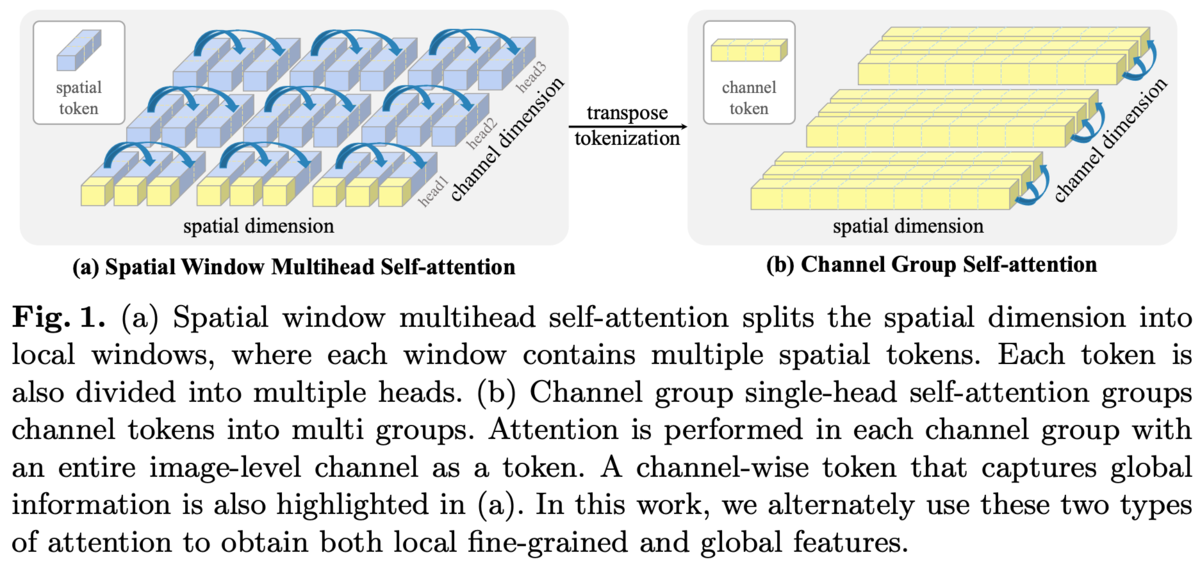
Spatial Window SAはSwin Transformerのものと同じ。
local window内でSAするのでグローバルな情報を扱えない。
そこでChannel Attention(CA)を導入する。
チャンネル数、画像の縦横を
としたとき、空間方向のSAは長さ
の
次元特徴ベクトルのシーケンスとみなしてSAを行うのに対して、チャンネル方向のSAは長さ
の
次元特徴ベクトルのシーケンスとみなしてSAを行う。
各パッチは画像の局所的な情報を持っているのに対して、各チャンネルはすべてのパッチを横断して画像全体における特徴を持っており、CAによりグローバルな情報を扱うことが出来る。
ただ、チャンネル次元が512とかになると計算コストが大きいのでチャンネルをGroup Normのようにグループ化し、そのグループ内でチャンネル方向にSAを行う(Channel Group Attention(CGA))。空間方向でのlocal windowと同じ。
local window SAと同じ制限、つまりグループ同士でのインタラクションが必要になるがそれは空間方向のSAが担ってくれる。
計算量については省略。詳しくは論文参照。
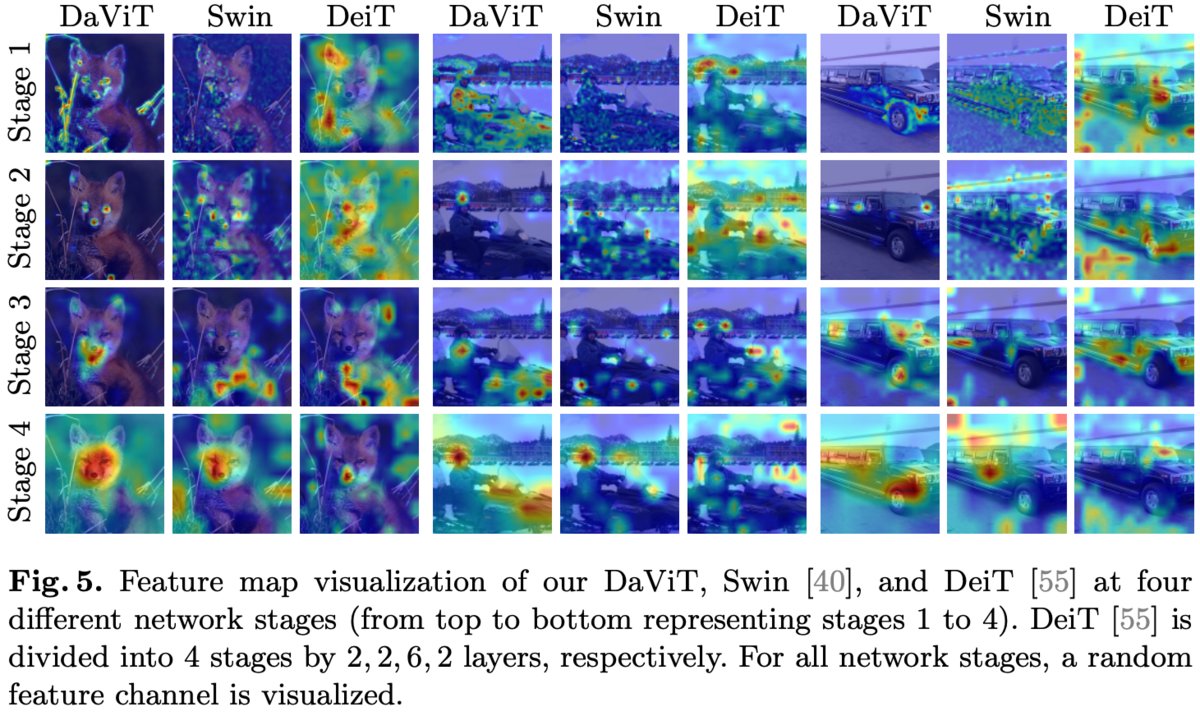
特徴マップの可視化比較。
このDual Attention Blockを使ったアーキテクチャをDual Attention Vision Transformers (DaViT)とする。
よくあるViTと同じアーキテクチャ構造でパッチ埋め込みのレイヤーの後に4つのブロックがスタックされる階層構造。
ViTでお決まりのサイズ毎の複数アーキテクチャ。
が層の数、
がチャンネル方向SAのグループ数、
が空間方向SAのヘッド数。
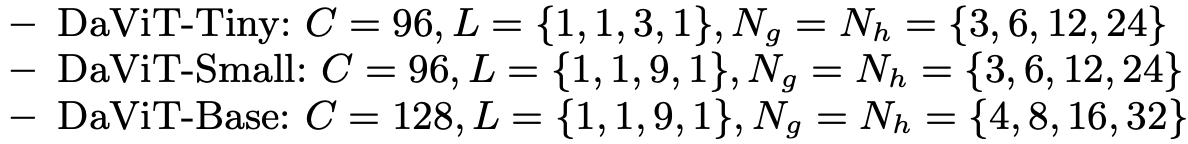
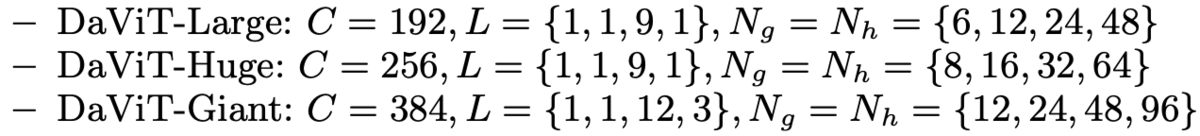

実験・結果
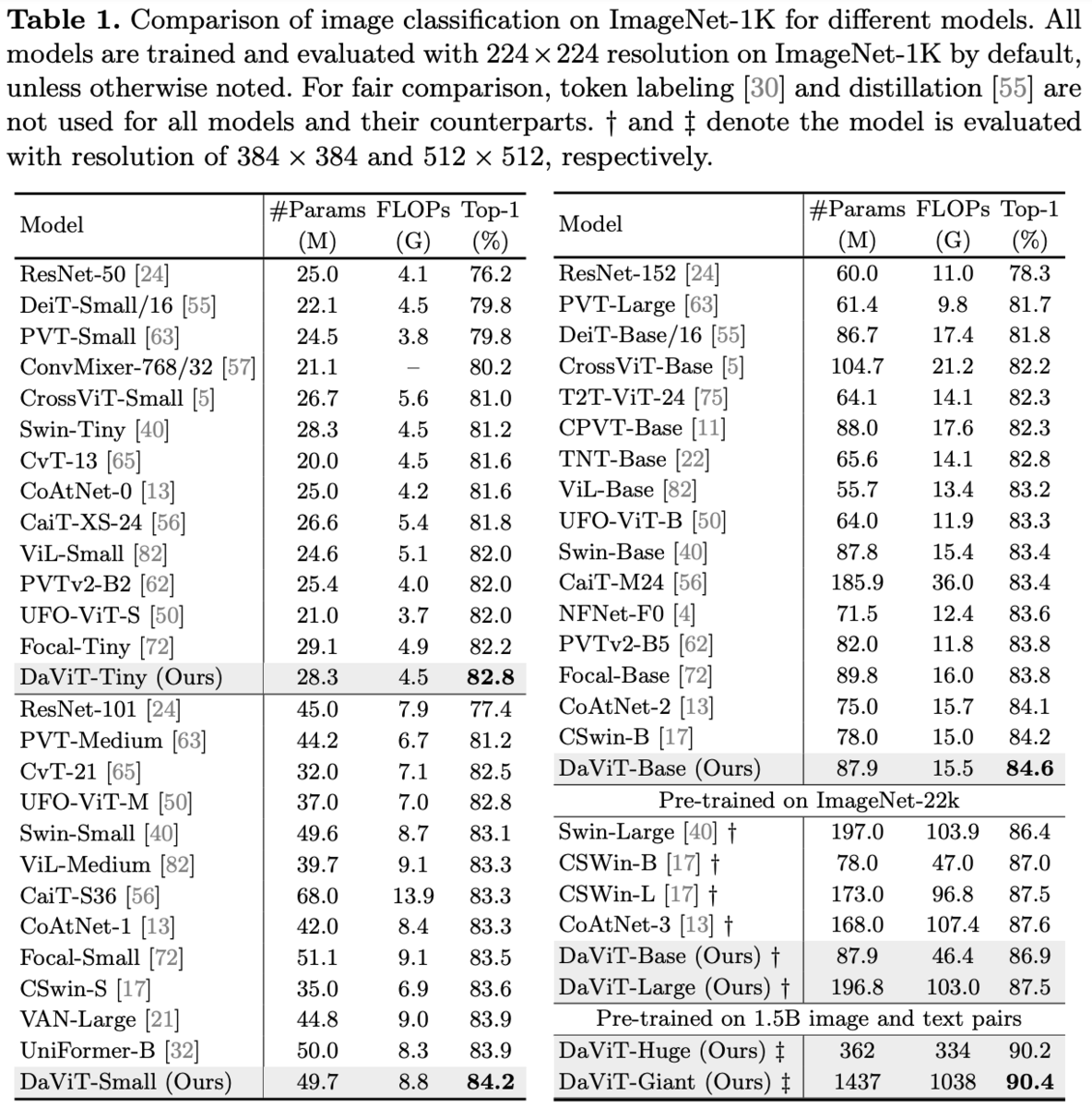
ImageNet-1Kのクラス分類、COCOの物体検出、ADE20kのセマンティックセグメンテーション。
バッチサイズ2048、AdamW、300エポック。
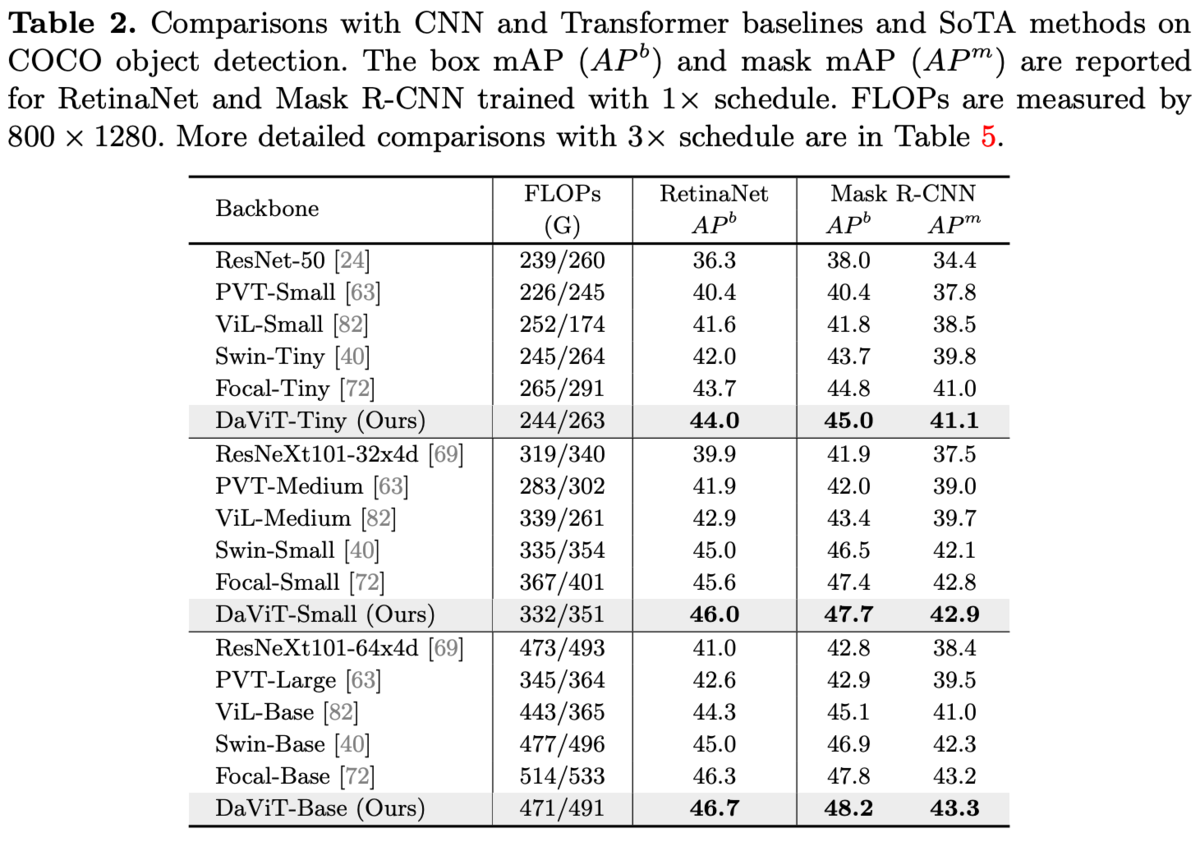
COCO。
ADE20k
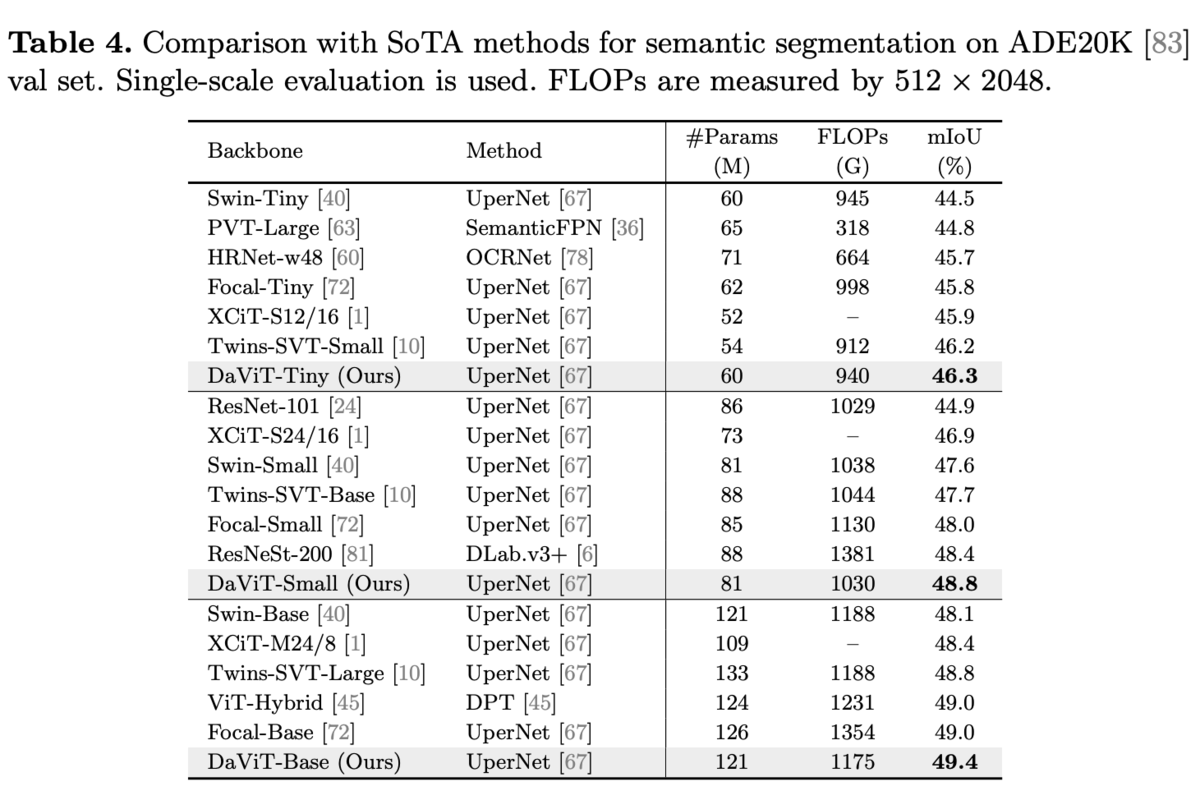
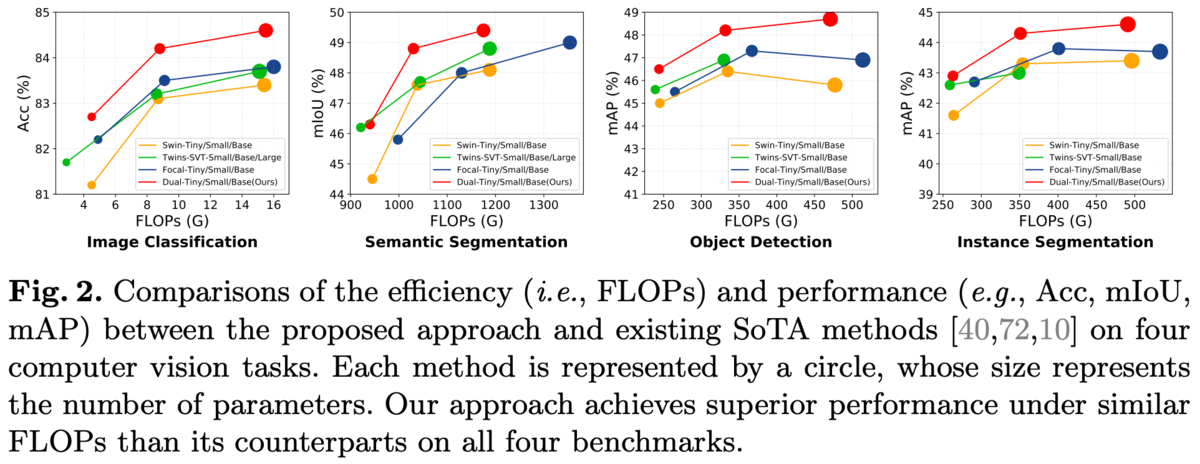
同じレベルのFLOPsで比較しても優位。
Ablations。
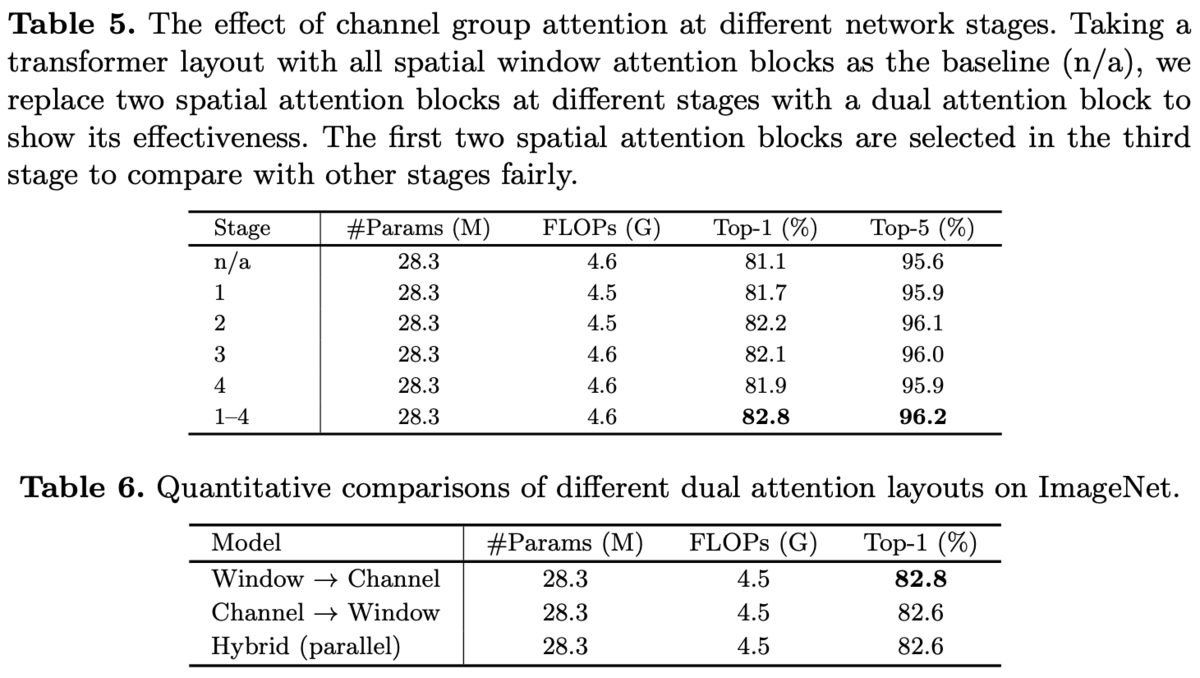
CGAをどのブロックで採用するか(表5)と各SAの順番比較(表6)。
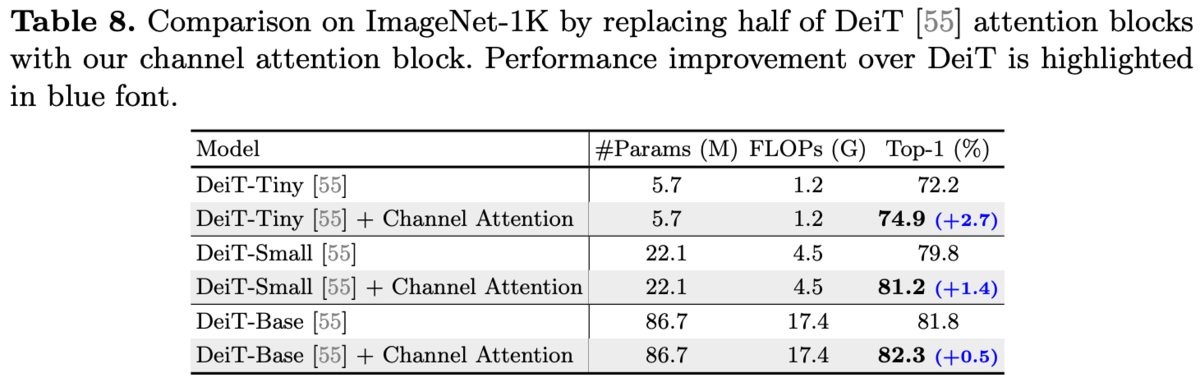
DeiTの各Blockの半分をChannel Attentionに置き換えた。
所感
チャンネル方向のattentionで、Group Normのようにチャンネルをグループにするというシンプルな解決策。
グループに分けると計算コストは減るがグループ同士のインタラクションが必要になる。
それを直交する方向(空間方向とチャンネル方向)でattentionすることで解決しているのは良い。