[論文メモ] Screentone-Preserved Manga Retargeting
スクリーントーンの見た目を保存したまま画像をリサイズする。

bilinearやbicubicでリサンプリングするとスクリーントーン部分にブラーやアーティファクトが起きる(特に縮小)。
スクリーントーンは漫画の見た目に大きく影響する。
全体の構造を保ったままリサイズしつつ、スクリーントーンの解像度や細かさは元のまま保存したい。
手法
サイズのターゲット画像
をスクリーントーンの解像度を保ったまま、サイズ
の画像
にしたい。
既存手法のScreentoneVAEを使ってスクリーントーン部分を検出する。
ScreentoneVAEは漫画画像と潜在空間との双方向マップで、潜在空間からスクリーントーンの復元ができる。ただし、元のスクリーントーンから少し変化してしまうことがあるらしい(特に大きいパターンのスクリーントーン)。
なのであくまでScreentoneVAEスクリーントーン部分の検出のみに使い、元画像のスクリーントーンを流用する手法をとる。
提案手法の全体の流れは図6の通り。

元画像から既存手法を使って線画構造のマップとスクリーントーン画像
を抽出しスクリーントーン画像はさらにScreentoneVAEマップ
に変換される。
と
をそれぞれターゲットの画像サイズにリサイズし
と
を得る。
これらをEncoder-Decoder型のscreentone reconstruction network に入力して目的の画像を得るがボトルネックの部分に領域毎のスクリーントーン特徴
を注入する。
は特徴抽出のためのネットワーク
に
と
を入力して得られる(
)。
とボトルネック部分は解像度が異なるので後述する階層化したアンカーを用いて解像度をあわせる。
Hierarchical anchor-based proposal sampling
screentone reconstruction network のエンコーダ部分を
としてボトルネック部分の特徴を
とする。
の解像度とスクリーントーン特徴
の解像度は異なるので合わせる必要があるが、単純にリサンプリングとかするとスクリーントーンのパターン情報等が壊れる。
そこでのグリッドのアンカー
を用意する。
そして各アンカーを中心としてクロップする。クロップ関数をとして
。
図8に2x2グリッドの例を示す。
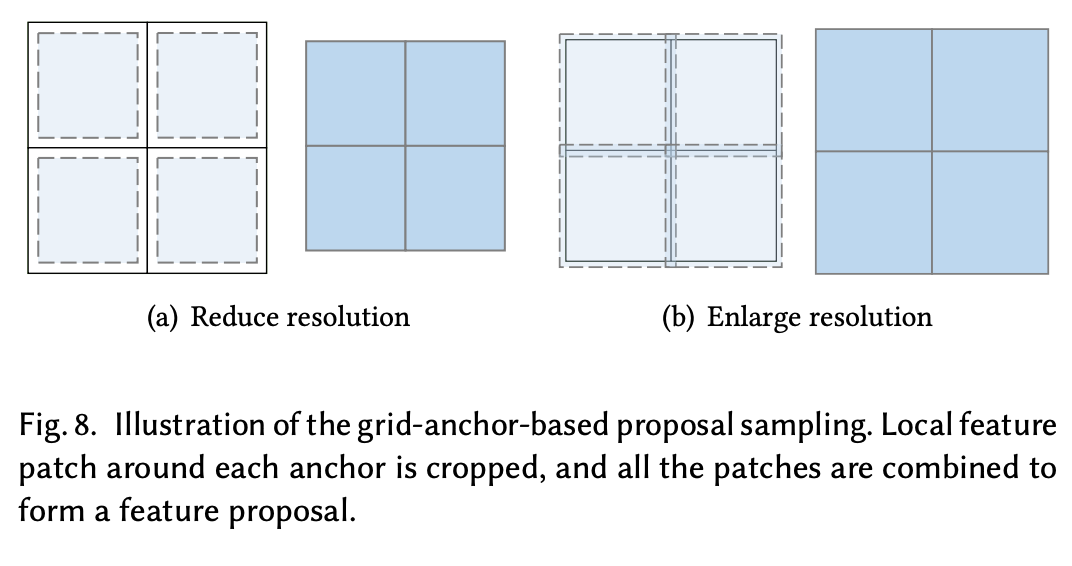
グリッドが1x1の場合アンカーは1つでクロップサイズはターゲットの解像度と同じ。グリッドが2x2の場合、アンカー1つあたりのクロップサイズは1x1のときの半分といった感じ。
必ずしも縮小ではなく拡大のときもあり、そのときは逆にアンカー毎にパディングをして拡張する。
リサンプリングと違って不整合が起きており、1x1のアンカーによるクロップでは端の方は明らかにもとの特徴と一致しない。だからといってたくさんのアンカーを使ってクロップしたものでは局所的な断裂が大量に発生している。
複数のグリッドサイズでクロップした特徴マップを利用することでそのあたりの不整合を解消するガイドを作る。
このクロップした特徴マップを候補特徴と呼ぶことにする。
Recurrent selection of hierarchical proposals
同じ解像度のボトルネック部分の特徴とスクリーントーン特徴
をクロップした
個の候補特徴集合
が手に入ったのでこれらをconcatしてデコードして終わり、というわけにはいかない。
デコーダネットワークはconcatした候補特徴集合の内どれを採用すればいいかわからず元のスクリーントーンと異なるものになる(図9(b)参照)。

そこで各特徴マップを再帰的に選択するRecurrent Proposal Selection Module (RPSM)を採用する。
RPSMモジュールのアルゴリズムは以下。
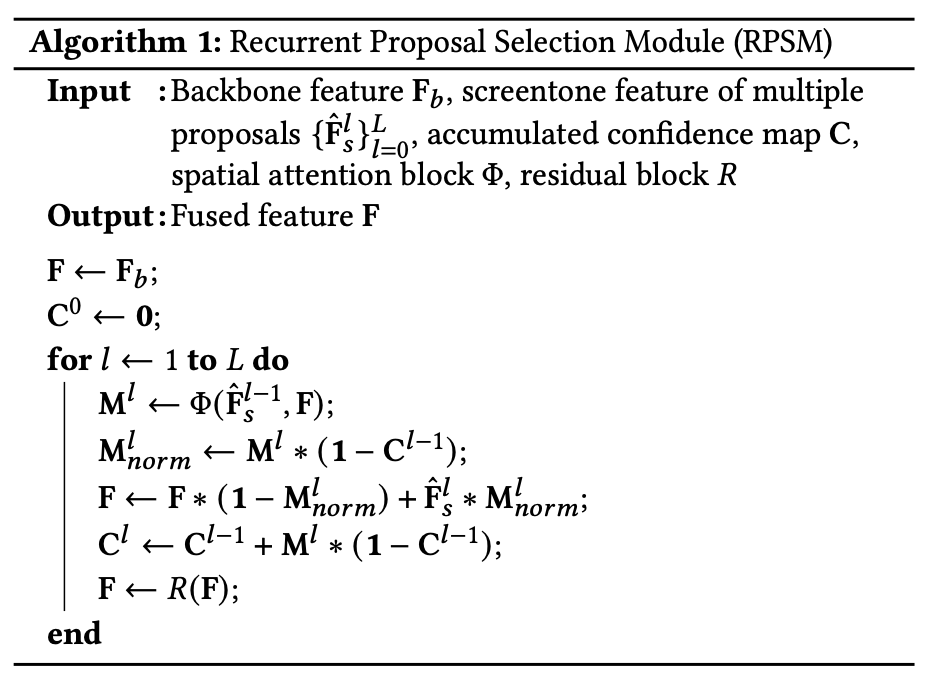
画像の各領域は候補特徴の集合からなるべく1つを採用するように強制する。
が確信度マップの累積。
アルゴリズムを上から見ていくと
forで候補特徴を一つずつに注目していく。
現在のベースとなる特徴マップ(最初はエンコーダ後のボトルネック特徴)と注目している候補特徴からマスク
を作る。
から累積確信度マップを引いたもの、つまりまだ候補を採用していない領域に絞り込む(
)。
絞り込んだマスクを使って候補マップをブレンドしベースの特徴マップを更新する()。
確信度マップを更新(累積)()
ResBlockでfoward()
という感じ。
Loss function
lossは
- translationinvariant screentone loss
- ScreenVAE map loss
- attention loss
- adversarial loss
Translation-invariant screentone loss
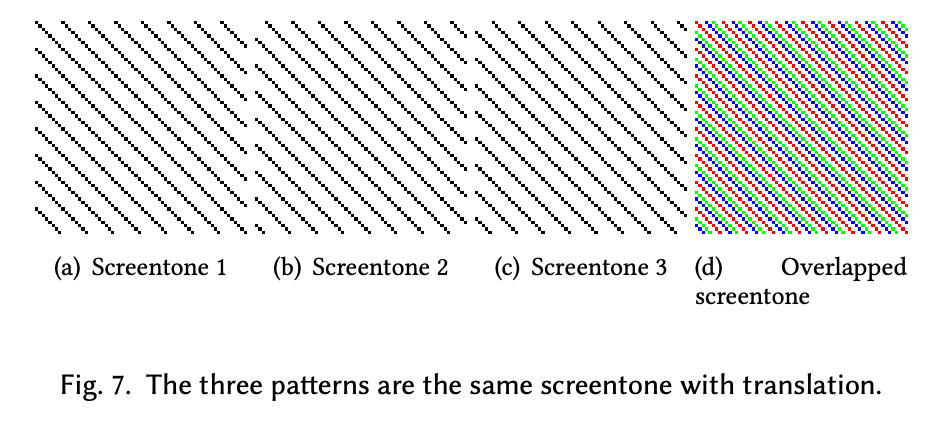
スクリーントーンのズレは人間にとって影響せず、正解は一つではない。図7の(a)が正解だとしても(a)(b)(c)のどれでもさほど問題ではない。
生成した画像をとしてTranslation-invariant screentone lossは以下の式(1)。
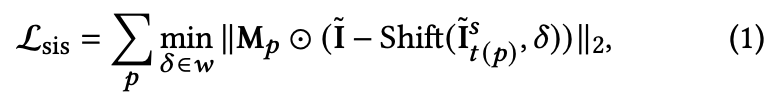
は領域、
は領域
の正解のスクリーントーンの種類、
は正解のスクリーントーン画像、
は(たぶん)領域
のマスク、
はオフセット、
は11 x 11のウィンドウでオフセットの探索範囲、Shift
は
だけシフトする演算子。
図7で示した通りスクリーントーンのパターンのズレはさほど問題ないので、正解のスクリーントーンのパターンで最も誤差の少ない移動を見つけて誤差を取る。
ただ、で繰り返しが見つけられないようなスクリーントーンに対応できない。
そこで生成画像と正解のスクリーントーン画像を半分のサイズにしてを探索し、それによって移動したものを新たな正解のスクリーントーン画像にする。
ScreenVAE map loss
Translation-invariant screentone lossは視覚的に似ていても空間的に一貫性のないパターンを持つスクリーントーンを生成することがある。
そこでもとの画像と同じスクリーントーンで埋めるようにScreenVAE map lossを追加。
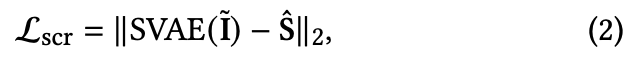
は正解のScreenVAE map。
Attention loss
複数の候補特徴があるが同じ領域でも各候補特徴同士に一貫性はないため、1つの領域は複数の候補特徴の中から1つを選ぶようにさせる。

[tesx: |\cdot|]は絶対値で、0.5引いた絶対値から更に0.5引いたものをlossとしてるので、lossが最小になるのはマスクの各値が1か0のときになる。
ただ、正解がわかっている場合はそのラベルを直接正解に用いる。


Adversarial loss
実際の漫画の分布に近づけるため。
適当に漫画っぽい画像を生成しても困るので、線画構造のマップとScreentoneVAEマップをConditionとする。

最終的なlossは以下。

各係数は。かなり職人的だ。
実験・結果
まずはデータセット。手作業で100枚の線画と125枚のスクリーントーンを用意し既存手法でスクリーントーンを貼って6000枚の漫画画像を用意した。
これらはと
用で、これとは別に20,000枚の漫画画像も用意した。
既存手法との比較


各lossの影響


小さい領域や、不規則なパターンに弱い

所感
確かに、スクリーントーンをリサイズすると雰囲気が変わり、作者の意図したものが変わってしまう。元のスクリーントーンの解像度を維持するのは大事。面白いタスク。
複数の候補があったときに、単純にconcatするのではなく、選択的に1つを採用するという仕組みは面白い。
ただReccurrentにやる必要があるのか少々疑問。バイナリなAttention Mapさえ生成できれば再帰的にやる必要はなさそうな気もする。
スクリーントーンの種類がある程度有限なら、わざわざ本家から持ってこなくてもスクリーントーンのサンプルから引っ張ってきても良さそうだが、多分そうでは無いのだろう。似たようなスクリーントーンでは作者の意図は反映できないだろうし。それに不規則なスクリーントーンはどこを切り出すかの問題がありそう。
スクリーントーン同士の視覚的効果が似ている判定とかはできないのかな?