[論文メモ] Fine-tuning Image Transformers using Learnable Memory
Vision Transformer(ViT)の入力トークンに学習可能なメモリトークンを追加することで新規タスクにスケーラブルなfine tuning方法を提案。

ViTは大量のデータで学習することで高い精度を得られる。そしてそれをfine tuningすることで画像分類等のタスクに応用する。
しかしViTは大量のパラメータがあり、タスク毎にすべてのパラメータを保存するのは高コスト。またfine tuning時の学習率に対しての敏感さもある。
そしてタスク毎にモデルを作ると保存のコストや実行時のコスト(タスク分forwardする)が必要。
これらを解決したい。
手法
既存の学習済みViTにメモリとなるトークンを追加する。
ここではクラス分類について考える。
ViTの入力は画像を個のパッチ(トークン)化してPositional Encoding(PE)を追加したものと最終的なクラス分類に使われるクラストークン。
なので合計のトークン列が入力となる。

ははじめの画像パッチの変換(MLPとか)、
がPE、
がクラストークン。
ここにfine tuning用のメモリトークンをconcatする(
はトークンの次元数)。
ViTはのトークンを入力として受け取ることになる。
そしてこのメモリトークンは次のブロックに伝わらない。
つまりブロックの出力を
とすると
は
個のトークンに切り捨てられ、次のブロックに入力する際は再度メモリトークンをconcatする。

切り捨てないもの等も実験したがこれが良かったらしい。
ランダムに初期化したメモリとクラストークン、そしてクラス分類のヘッド部分のみをfine tuningすると良いパフォーマンスを得られるが、ヘッド等が変化するため元タスクの予測はできなくなる。
元タスクを予測する必要がないなら問題ないが、元タスクと新タスクの両方が必要なことも多い。両方保存するのは単純だが新タスクが増えていくと破綻する。また計算コストも新タスク分だけ増える。
すべてのタスクを1つのモデルで学習する方法もあるがこれは常に可能なわけではない。
そこでメモリトークン、クラストークン、ヘッド部分のみ付け替えAttention Maskで対応する。適切なAttention maskを利用すればトークンへの注意を制御出来る。
元の入力トークンとクラストークンに対するattentionを同じく入力トークンとクラストークンに依存するようにする。
そして新たなタスクのためのクラストークンが追加された場合、そのクラストークンは入力トークンとクラストークンに加え自身のクラストークンとメモリトークンに依存するようにする。言い換えると他のタスクに依存しないようにする。
表1がそのマスク。

このようなマスクを設計することで同時に複数のタスクをfowardすることが出来る。
入力に各タスクのメモリトークンをconcatしforwardする。マスクにより入力トークンや元のクラストークンはメモリトークンの影響を受けず、各タスクのクラストークンも互いに独立しているので問題ない。最後に各クラストークンを各々のタスクのヘッドにつなげれば各タスクの出力を得られる。

実験・結果
基本アーキテクチャはViT-B/32でImagenet-21Kで学習されたViTの論文元が公開している事前学習モデルを利用。
学習率のスケジューリングはコサインでその他の設定はViTの論文参照。
最適化手法としてMomentum SGD + Gradient Clipping、5step warmupあり。
各データセットについて試した結果が以下の図4と表2。
Fullはモデル全体のfine tuningで一番良いが一番コストが高い(モデルをすべて別々に保存する必要がある)。
ヘッドやクラストークンの学習に比べ提案手法のが良い(メモリトークンの分の多少のオーバーヘッドはあるが)。
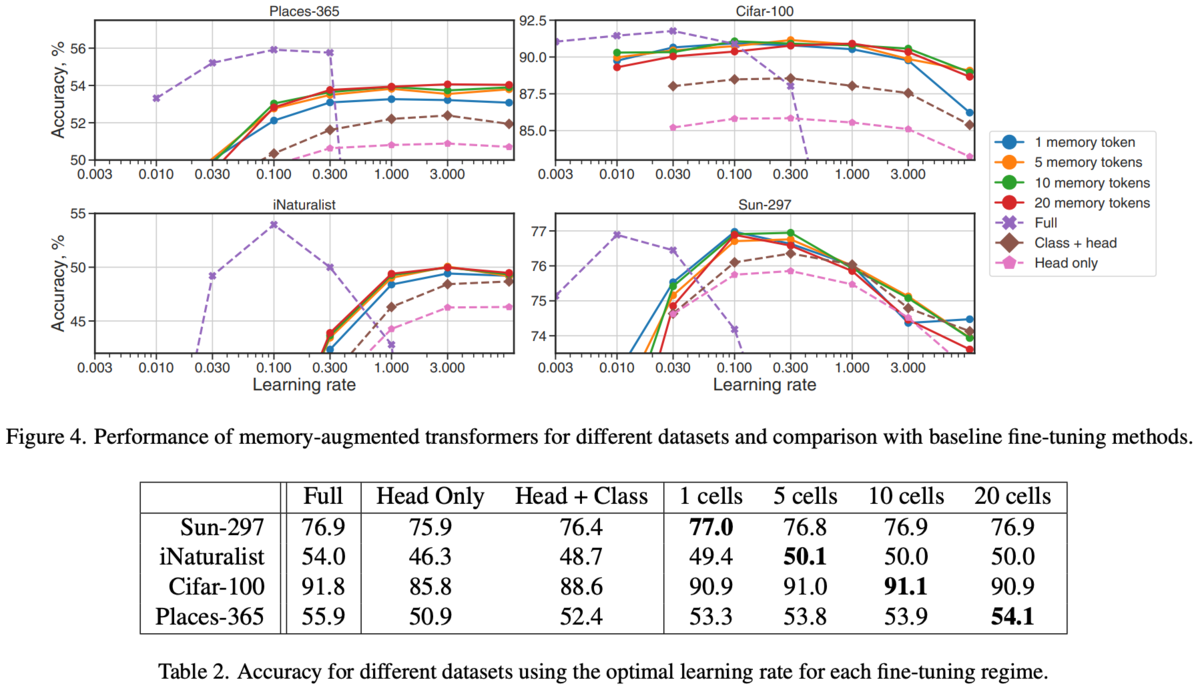
新規タスクのために増加したパラメータと計算コスト。もとのViTのパラメータが80MでFullは当然丸々1ViT分増える。

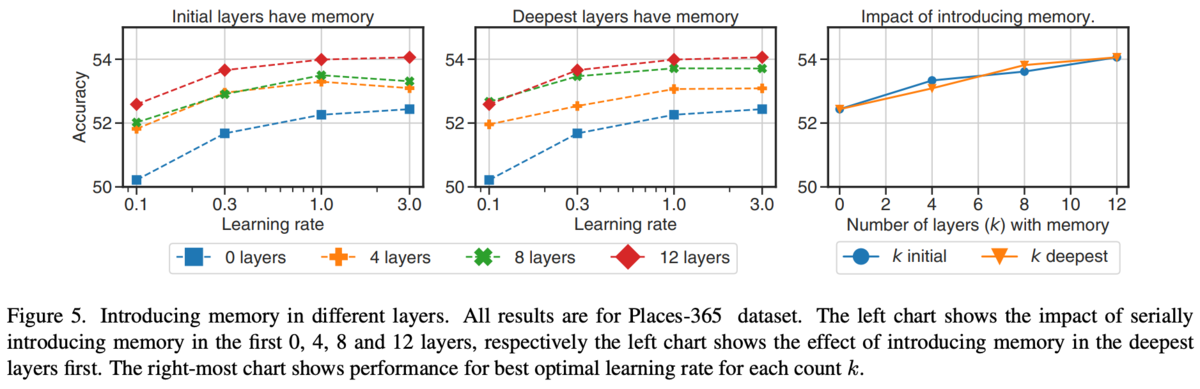
Ablations。
メモリトークンの扱いについて。
メモリトークンはブロックに入力する際に追加され、出力時に切り捨てているが他についても調査。
追加・切り捨ては図2の左から2番目。
ブロック毎に追加していく(切り捨てしない)パターン(図2左から3番目)とはじめのメモリトークンを伝播していく(図2右はし)を実験。
結果が図6。Full memory(追加・切り捨て)がよい。


どのブロックでメモリトークンを追加するといいのか。