[論文メモ] Masked Autoencoders that Listen
arxiv.org
FAIRのtechnical report
Masked Autoencoderを音声(スペクトログラム)に適用した
Transformerベースな音声タスク用の手法が提案されているがImageNetでの事前学習が行われていて、言うまでもなくこれは適切ではない。
音声データをBERT等で事前学習するにしても長いシーケンスを扱う場合、計算量が非常に多くなる。
Vision Transformer(ViT)は画像をパッチに分けシーケンスとして扱うが、パッチ化することでシーケンスサイズを抑えることができる。
ViTを使った自己教師あり学習の手法の1つであるMasked Autoencoder(MAE)は入力パッチをマスクし更に入力サイズを減らす事ができる。
このMAEを音声ドメインに適用できないかというお気持ち。
結果的にMAEは読むこと(BERT)、見ること、聞くことができることがわかった。
手法
全体像は図1の通り。

普通のMAEの様に入力の大半をマスクし、マスクしなかった部分のみをエンコード。
マスクした部分をマスクトークンで埋めてデコードし、元のデータとのMSEをとる。
正直既存のMAEをスペクトログラムドメインに適用しただけ。
マスク戦略
スペクトログラムを時間軸と周波数軸の2D画像として扱うが、実際の画像と異なり構造に意味がある。
そこでマスクする際にそこに注目し、いくつかの戦略を試す。
大きく2つの戦略を試す。
1つ目は構造に無関係(Unstructured)な方法で、ランダムにパッチをマスクする(図2(b))。
2つ目は構造に注目した(Structured)方法で一定の時間、周波数、もしくは両方をマスクする(図2(c)~(d))。
マスクレートは80%と画像に対するMAEのマスクレート(75%)に近い大きさで問題なかった。
高いマスクレートでのUnstructuredで事前学習の後、低いマスクレートでのStructured(time + frequency)でfine-tuningするのが最も良かった。
Encoder
EncoderはViTの論文のViT-Bを利用。TransformerのEncoder Block12個のシンプルなモデル
Decoder
Decoderも同じくTransformer Blockを積んだシンプルなものを利用する。
マスクされた部分を学習可能なマスクトークンで埋めて、Positional encodingを追加後、Decoderに通す。
Decoderの出力に線形層を追加してスペクトログラムを復元する。
ただ、self-attention(SA)についてはドメインに合わせ工夫を行う。
Transformerはglobal sAを使っているが、単純な画像の場合それは問題ない(位置、スケール等が画像としてのセマンティクスに影響しない)。
それに対してスペクトログラムの場合、位置やスケール等が音声に影響を与えるのでglobal SAは必ずしも適切ではない。
画像に比べ位置が非常に重要。
そこでlocal SAを導入した2パターンを調査。
1つ目はShifted window location。
Swin Transformerのlocal windowを採用し、localな領域でのSAを行う。
1つのTransformer Blockには2つのSAが含まれており、2つ目のSAのときはwindowを50%移動する(図3参照)。
2つ目はHybridで最後の数レイヤー以外にlocal SAを適用する。最後の方ではglobal SAがあるので再構成のときにはglobalな情報も含まれる。
Objective
目的関数は入力されたスペクトログラムの各パッチの再構成loss(MSE)。
再構成lossのみで十分で、contrastive objectives等を追加しても改善はしなかった。
Fine-tuning for Downstream Tasks
タスクに合わせるためのfine-tuning時はdecoderを取り除きencoderのみを利用する。
fine-tuning時もレートは下げるがマスクを行う(オリジナルのMAEはマスクしない)。
マスクすることで正則化の効果が得られる(計算コストも少し下がる)。
実験・結果
6つのタスクについて実験
音声分類:AudioSet (AS-2M, AS-20K)、Environmental Sound Classification (ESC-50)
スピーチ分類: Speech Commands (SPC-1 and SPC-2)、VoxCeleb (SID)
ablationではAudioSetを利用
音声はKaldiにより128のメルスペクトログラムに変換。
16x16のオーバーラップなしのパッチ化をし、埋め込みはconvolutionを利用。
事前学習時はAS-2Mを利用し32epoch。バッチサイズは512。
64個のV100GPUを使って36時間程度かかったそう。
入力音声はスタート位置をランダムに選択し約10秒程度切り出して利用。augmentationは利用しない。
Ablations
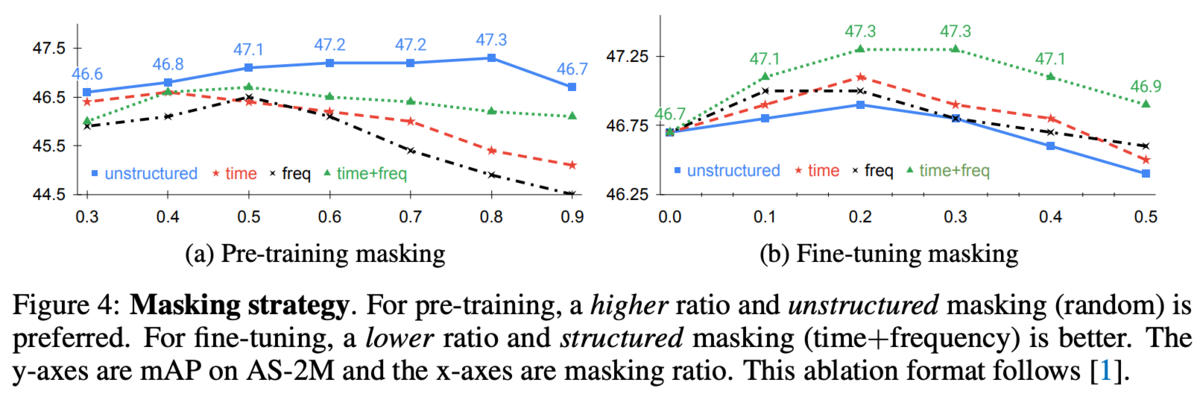
マスク戦略についての調査。マスクの方法とその割合について事前学習とfine-tuningでそれぞれ。
マスクの方法で大きく差が出ている。
事前学習ではマスクレート0.8のUnstructuredな方法が、fine-tuningではマスクレート0.2~0.3のStructured(time+freq)が最も良かった。
各マスク戦略について再構成したときの結果が図6。
Unstructuredな方法のほうが近くのパッチからうまく外挿しやすそう。

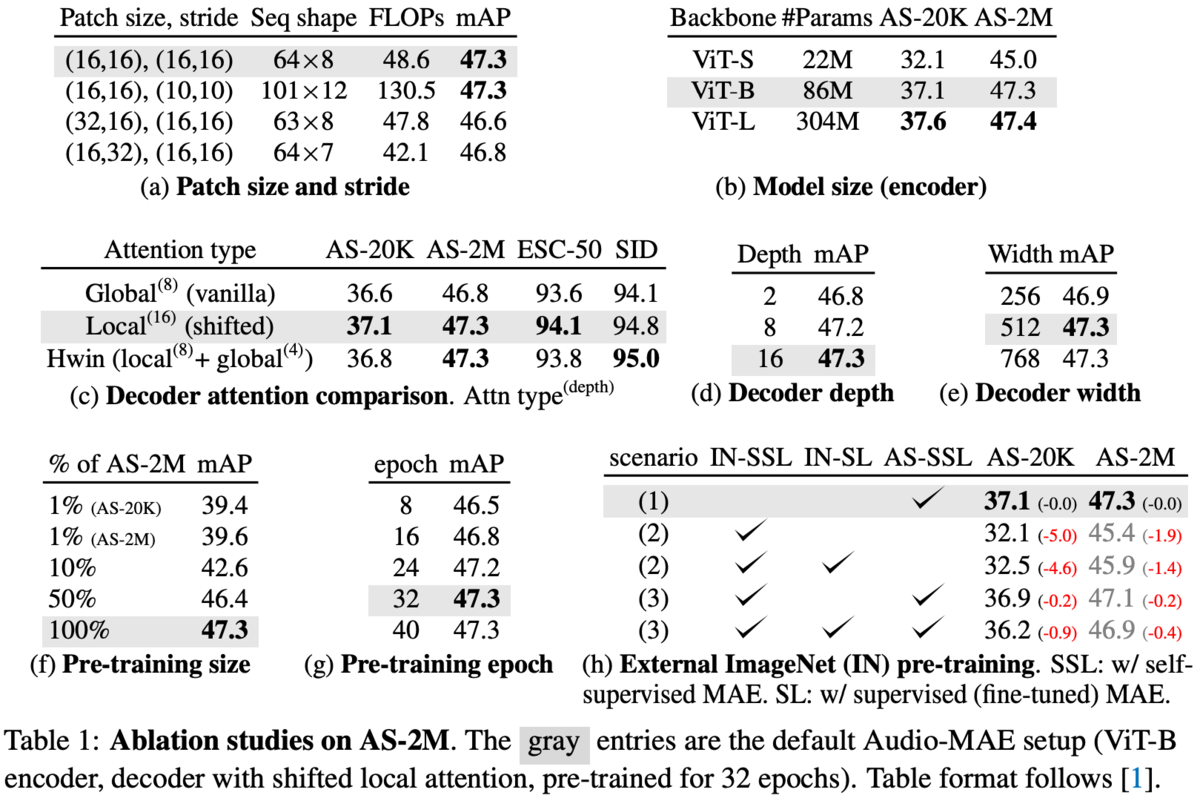
パッチサイズやストライドの大きさ、EncoderとDecoderのサイズ等のablationは表1。
表1(h)はOODデータであるImageNetを使った事前学習の効果についての実験だが、AS-SSLが音声のみの学習で、それが一番良かった。
Decoderのattentionについてはlocalが入ったほうが良さそう(図5)。

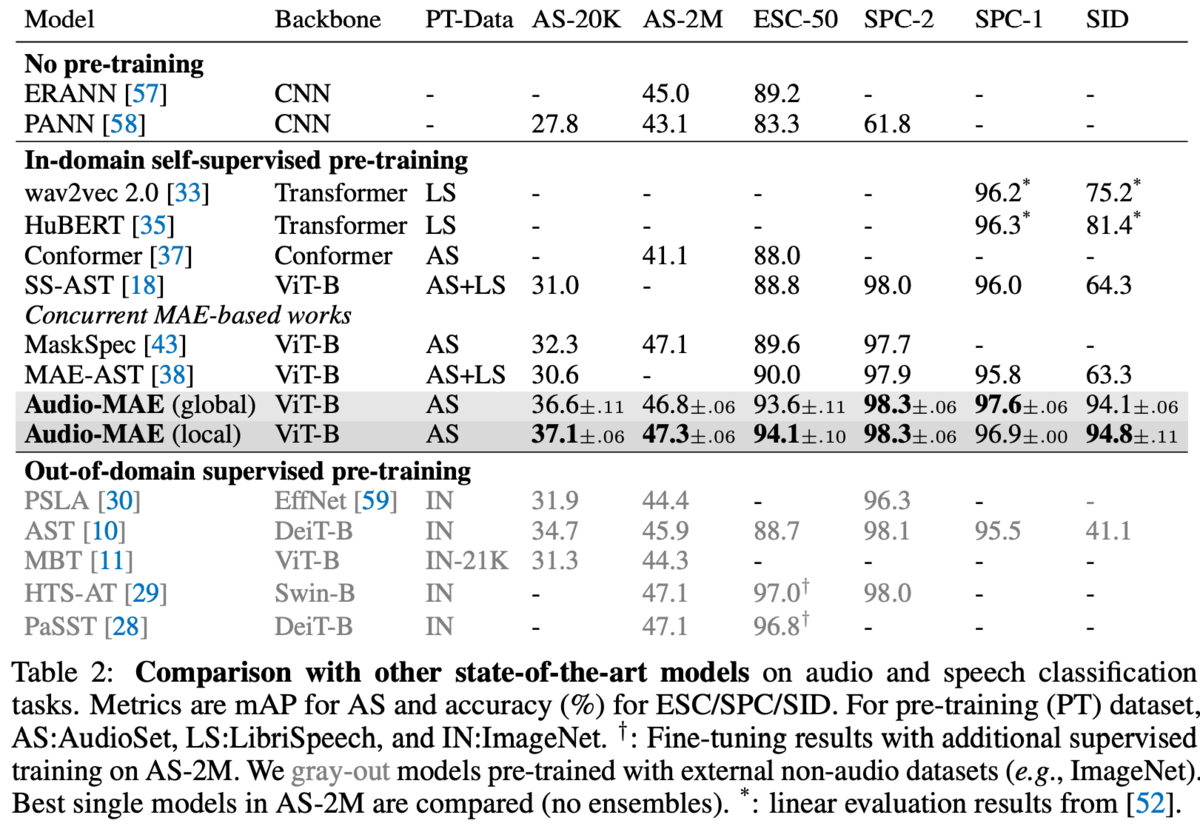
他手法との比較
全体的にMAEが優勢。
所感
音声としての構造に関してほぼほぼ関係なし(Decoderのfine-tuningは多少関係あり)にMAEを適用するだけで良いのは少々意外。
他手法に比べ学習時間等がどうなのか気になるところ。
特別なlossや工夫が無いのは利用者としては嬉しい(特別なものは概して学習が不安定だったりうまくいかなったりする)。
Unstructuredなマスク戦略は単純なランダムっぽいが本当にそれでいいのか?(単位時間あたりに関して80%削るとか気になる)。