[論文メモ] VITS-Based Singing Voice Conversion Leveraging Whisper and multi-scale F0 Modeling
VITSベースのSinging Voice Conversion(SVC)モデルの提案
4回目となる Voice Conversion ChallengeはSinging Voice Conversion Challenge(SVCC)となりより難しい歌声変換タスクとなって開催された。
SVCC2023についてはこちらの記事にまとめた。
ninhydrin.hatenablog.com
このSVCC2023に参加した番号、T23の手法についての論文。
手法
アーキテクチャ全体像は図1を参照。
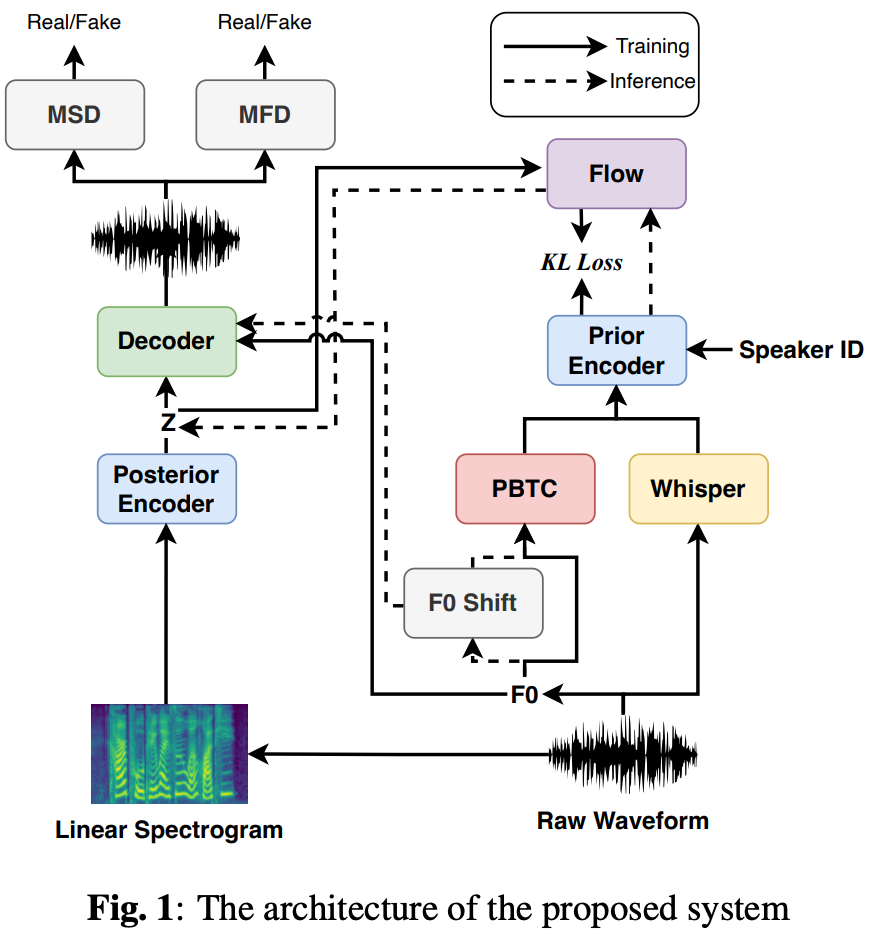
見てわかる通りVITSベースで細かいところに変更が入っている。
Posterior Encoder
特に変更なし
Decoder
中間特徴から音声波形を生成する部分でvocoderに該当する。
本家VITSでは入力を調整したHiFi-GANだったが、提案手法では歌声変換に対応するためにf0から生成したサイン波を入力に追加するsource filterタイプに変更した。

ただし、、
、
はサンプリングレート。
discriminatorはVITSと同じくMPDとMSD。
Prior Encoder
本家VITSではテキスト(音素)と話者IDが入力になっていたが、提案手法ではテキストのかわりにWhisperのボトルネック特徴と元の音声から抽出したF0得た特徴量
を入力とする。
つまりから
になった。
SVCCはnon-parallelなSVCで言語についても発話と歌で異なる場合がある。なのでマルチリンガルに対応できる必要がある。
whisperは多言語対応の音声認識なのでこれのボトルネック特徴ならそれを解決できると考えた。
whisperのエンコーダのいくつかの層で実験をした結果、浅めの特徴を利用することになった。浅い層には言語特徴、歌唱スタイルが含まれているらしい。
ただし、不要な話者も含まれているためランダムピッチシフトした音声を入力にすることで話者情報をぼかした。
歌声変換のためにF0特徴は重要だが単純にF0を入力するとF0抽出アルゴリズムのミスで変換が失敗することがあった。
そこでparallel bank of transposed convolutions (PBTC) moduleを使ってF0をエンコードする。
PBTC moduleについては図2参照。
ベクトル量子化したF0をone-hot化し、線形変換する。それを複数のdilate rateのTransConvに掛けて合流させる。

Training Strategy
普通なら他話者の歌唱データで事前学習するところだが、SVCCではデータが限られておりそれができない。
そこで3段階に分けての学習を行う。
1) Warm-up: 発話データでの学習
2) Pre-training: 歌唱データでの学習
3) Adaptation: ターゲット歌手のデータで学習
ターゲット歌手のデータが非常に少なく過学習してしまうのでaugmentationを行う。
行ったaugmentationはe formant shifting, pitch randomization, random frequency, speed adjustment。random frequencyってなんだ?
これらのaugmetationはボトルネック特徴に話者情報が漏れるのも防ぐ。
実験・結果
データセットは表1の通り。サンプリングレートは一律24kHzに。

SVCC2023のタスク1はin-domain、タスク2はcross-domain。
提案手法のチーム番号はT23。
SVCC2023の自然性についての結果が図3。
両タスク高いスコア。自然性は高そう。

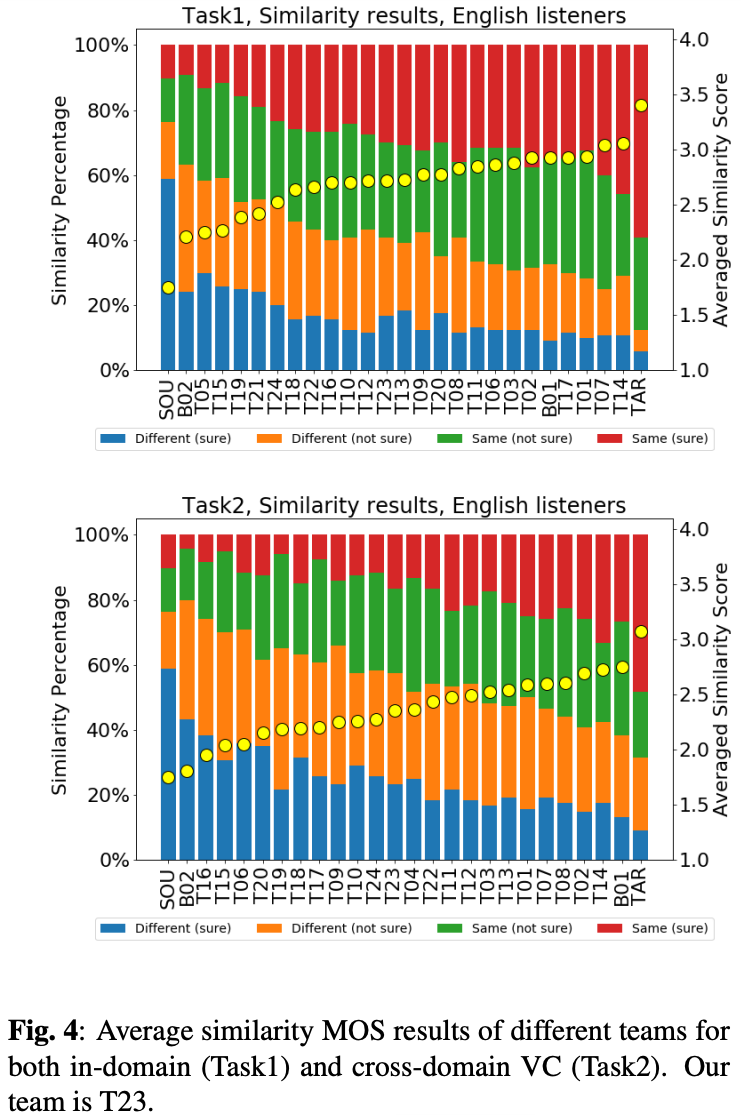
類似性についての結果が図4。
類似性について中央くらいの順位だが、他の手法と比べ大きな差はない。
単純にSVCタスクにおいて類似性を高めるというのが非常に難しいとのこと。
ablationとして
- PBTC moduleの有無
- whisperをconformerベースのWenetSpeechとLibriSpeechで学習したモデルに変更
- Warm-upステージの有無
を調査。結果が表2。
自然性への影響は大きそうだが、類似性については怪しい。
