[論文メモ] NORMFORMER: IMPROVED TRANSFORMER PRETRAINING WITH EXTRA NORMALIZATION
FAIR
概要
オリジナルのTransformerは次のSublayer(MHAとかFeedForward)への入力の分散を小さくするためSublayerの出力 + residual connectionの後にLayerNorm(LN)している("Post-LN")
最近の研究でPost-LN Transformerは入力に近い層に比べ出力に近い層が大きな値の勾配を持つことが確認され、LNをSublayerの前にすることを提案している("Pre-LN")
Pre-LN Transformerでは小さいlearning rate(lr)でウォームアップした後、大きなlrで学習をすることでPost-LNと比べ性能が改善している。
Pre-LNはPost-LNに比べ安定しているが、今度は出力に近い層に比べ入力に近い層が大きな勾配を持つようになった。
提案するNormFormerは3つのnormalizationを追加して勾配の大きさを全体に同じ大きさにする。
手法
NormFormer
アーキテクチャの概要は図1の中央を参照。
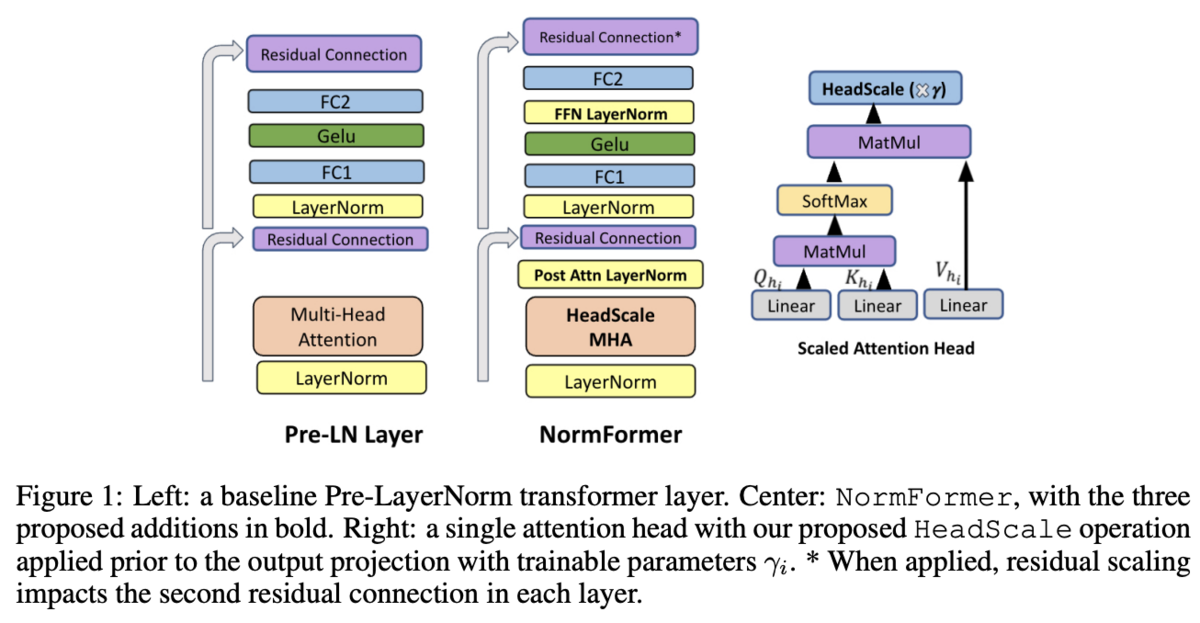
3つのNormalizationを追加する。
Scaling Attention Heads
1つ目はAttentionのHead部分。
普通のMulti Head Attention(MHA)は各Attentionの出力をとした時
という形をしているが、この各ヘッドをスケーリングする。
は学習可能パラメータで1で初期化。
Additional Layer Normalization and Putting it All Together
もう2つのNormalizationはMHAとFFNの出力の後。
Pre-LNにおけるレイヤーによる入力
に対する操作は
となっているが、これらを
Experiments
気になるところをピックアップするので詳しくは論文参照

Residual Scaling(RS)
近年の研究でresidual connectionにもスケーリングを導入すると安定すると報告。

◦は要素毎の積では1で初期化した学習可能パラメータ。
この仕組はNormFormerにも導入できる。

表2を見るとRSを導入するとパラメータの少ないモデル(<1.3B)では改善。ただし、1.3Bを超えると悪化する(図2)。


所感
LNを追加するというシンプルな方法で改善するのは嬉しい。多少のオーバーヘッドが気にはなる(学習時だけでなく運用時も発生するので)。
Post-LNとPre-LNでも違いが大きそうで、TransformerはNormalizationにかなりセンシティブそう。
RSのように元のモデルの性能を落とさない(重みが1なら同じだし)手法にしても悪化を招くことがあるので最適なNormやスケーリングの種類・位置を自分で探すのは難しそう。