[論文メモ] SeamlessGAN: Self-Supervised Synthesis of Tileable Texture Maps
arxiv.org
carlosrodriguezpardo.es
1枚のテクスチャ画像から、シームレスにタイル貼り可能な画像を生成するSeamlessGANを提案。
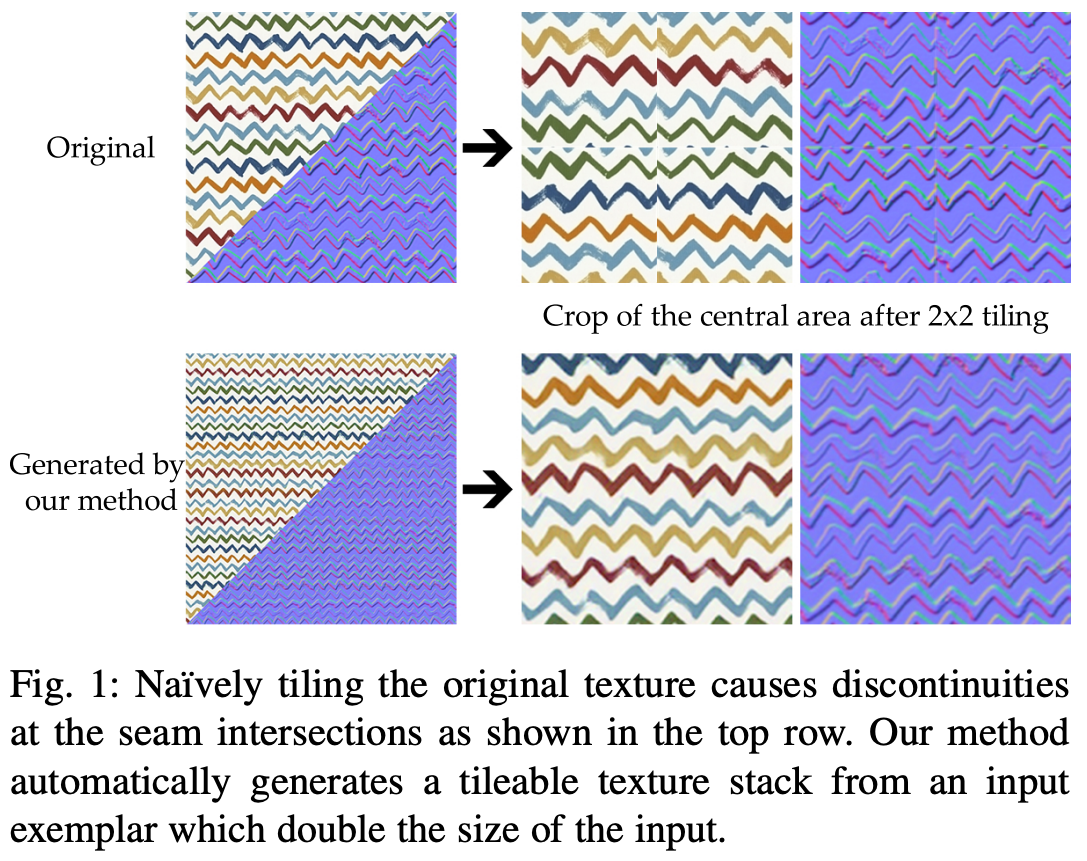
普通に切り取って並べると不連続な部分が生まれるが、提案手法のSeamlessGANではそれがない。
手法
入力はtexture stack(タイル貼りできないテクスチャ画像そのものと、それのアルベドのマップのペア)を入力とする(両方ともRGBで)。
入力のtexture stackから解像度のターゲット画像
をクロップする。
そこからさらに入力となる解像度のソース画像
をクロップする。
このを入力として
を生成するGeneratorを学習する。
アーキテクチャ
SeamlessGANはEncoder-DecoderのGenerator GとDiscriminator Dからなる。
GeneratorはEncoder、Residual Block、Decoder3つのコンポーネントからなる。
Encoder は入力されたテクスチャを解像度半分の特徴量マップにする。
Decoderは画像とアルベド用に2つあり、これらの2つのDecoderの共有の特徴を作るためにEncoderとDecoderの間にResidual Blockがある。
DiscriminatorはPatchGANを利用。テクスチャの局所的なクオリティの向上や、ある程度の制御が可能なため(Dにレイヤーを追加すると全体の品質は上がるが局所的な品質は落ちるらしい)。
タイル貼り可能なテクスチャサンプリング
テクスチャサンプルを学習後のGに与えれば新しいテクスチャサンプルを生成できるが、この生成後のテクスチャサンプルがタイル貼り可能である保証はない。
そこでProGANに倣い、特徴空間で空間方向にリピートを行う。
図2の、
のように得られたx0を4に複製しそれを空間方向にconcatし2倍の解像度の特徴マップF0に拡張し、これをResidual Blockに通して学習を行う。
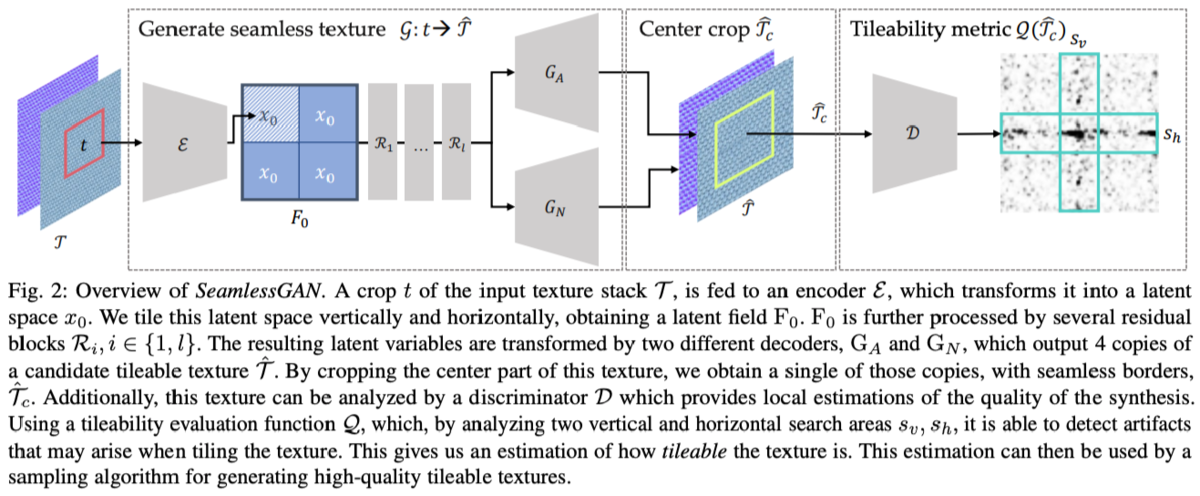
最終的に得られた画像から中心からクロップすればタイル貼り可能なテクスチャサンプルが得られる。
Residual Blockは 個あるが、そのどこでF0への拡張を行うかでクオリティに差が出る(図4参照)。実験的に層の浅い方がよく、結果的には0番目(はじめのResidual Blockへの入力時)が良さそう。
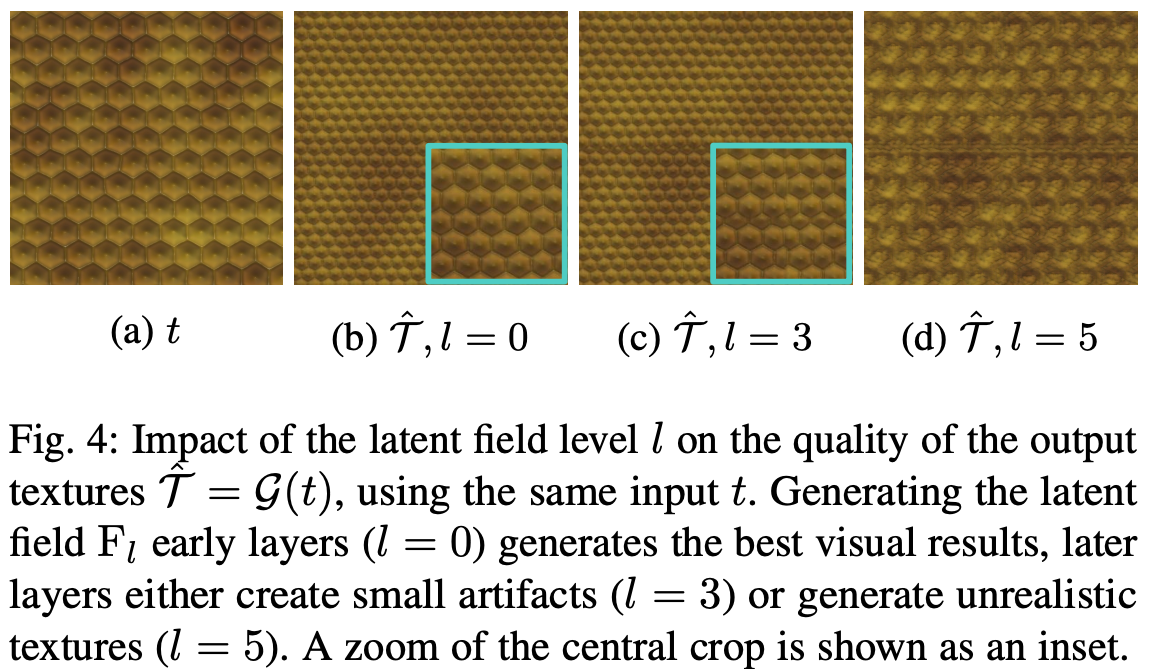
入力のサンプリング
上記によりタイル貼り可能なテクスチャを生成できるようになったが、SeamlessGANは入力により出力が変化し入力によってはクオリティが下がる(図5参照)。

そこでDiscriminatorを用いていい感じのテクスチャサンプルを生成できるような入力のクロップを探す。
クロップした入力画像を、Generatorを
、クオリティを図る関数を
として
となるような
を探す最適化問題を解く。
テクスチャのサンプリング。
採用したGANアーキテクチャはFCNな構造なのでメモリの許す限り、好きな大きさのテクスチャサンプルを生成できる。
また生成されたテクスチャサンプルが大きければリピートして貼り付ける回数も減り、結果的に接合部のアーティファクトも減るはず(図6(a)参照)。
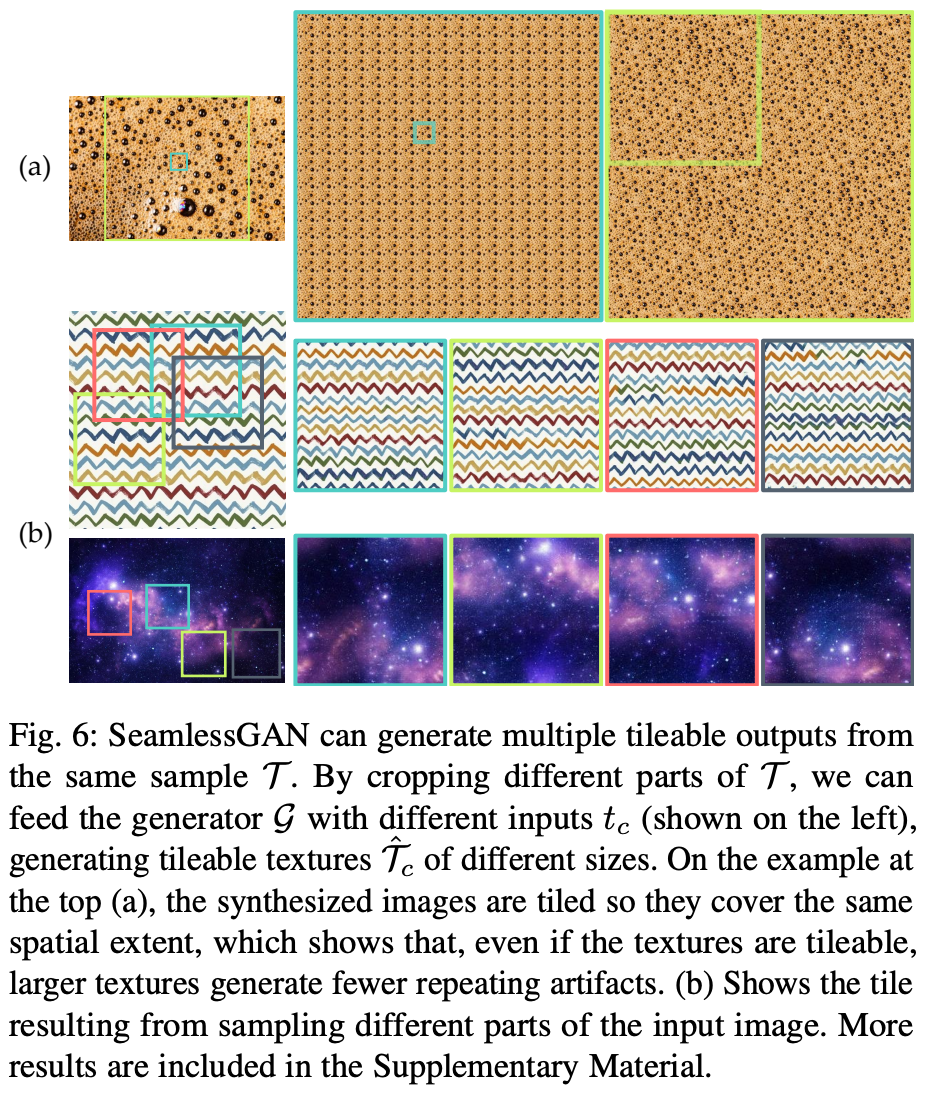
もしタイル貼り可能なテクスチャが見つかったとしても、「元の画像のテクスチャパターンがふくまれていること」と「テクスチャの中にアーティファクトがないこと」が必要。
これらの条件を満たした、可能な限り大きなサイズのテクスチャサンプルを生成できる入力画像となるクロップを探す。
入力画像のサイズから探索していき、クオリティ関数の尺度で十分なものが得られたところでストップする。
クオリティ関数
タイル貼り可能かどうかを判断するのがクオリティ関数。
図5からわかるように、主に接合部にアーティファクトが発生する。
ここでは学習したDiscriminatorを使ってクオリティ関数を構築する。
Discriminatorはadversarial lossによりセマンティクスも学習しているし、やstyle lossで色やリピートのパターン等も学習している。
生成したテクスチャサンプルを、中央部分のDiscriminator出力を
、中央以外のDiscriminator出力を
とする。縦、横の接合部をそれぞれ
、
としたとき
には縦横の接合部が含まれている。
クオリティ関数はか
がしきい値
以上のときに1(
でタイル張り可能)、それ以外0となる関数とする。ただし、
で
、
。しきい値は中心以外のminなので、イメージとしては接合部以外のDiscriminatorの出力、つまり普通の部分のテクスチャの一番それっぽい部分を表している。
で調整したしきい値に対して、接合部がそれと等しいがそれ以上なら十分接合部もそれっぽいということ。
実験・結果
例のごとく省略


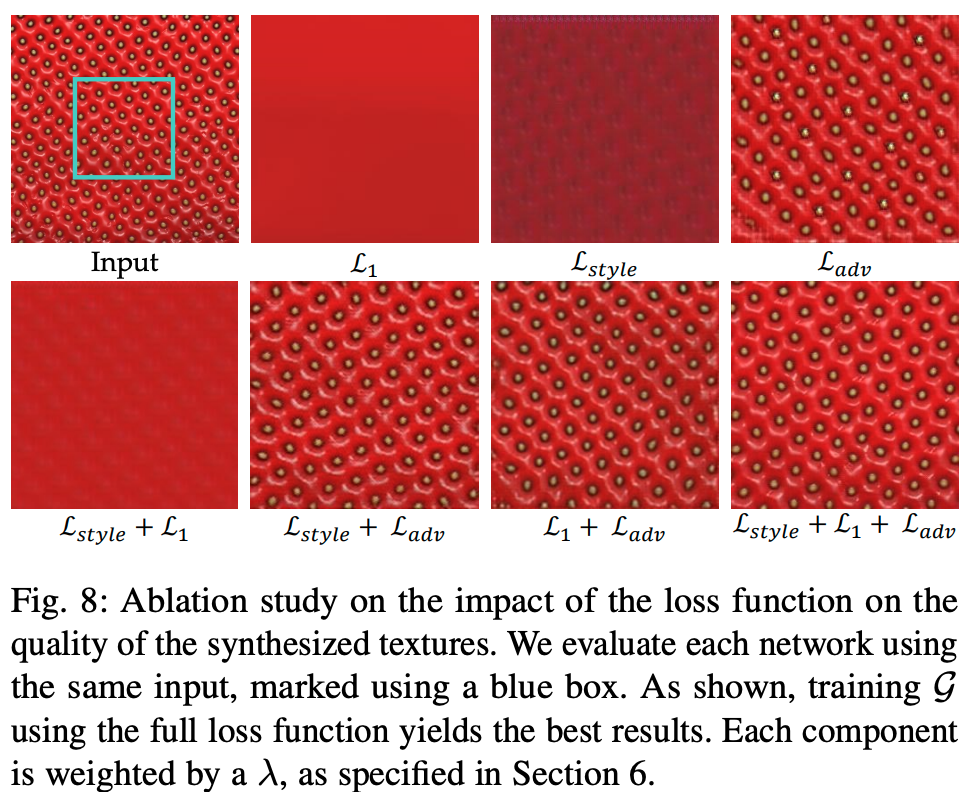
lossのablation