[論文メモ] VECTOR-QUANTIZED IMAGE MODELING WITH IMPROVED VQGAN
openreview.net
あくまで個人的なメモ
VQGANの改善とベクトル量子化を使った画像生成モデル・画像分類モデルの改善。
VQVAEはCNNベースのAE、VQGANはそこにadversarial lossを導入した。
これらはCNNのauto encoder(AE)の学習(ステージ1)とencodeしたlatent variablesの密度をCNN(or Transformer)で学習する(ステージ2)という2つのプロセスから成る。
こういったベクトル量子化の学習(ステージ1)->画像タスク(ステージ2)といった手法はVector-quantized Image Modeling (VIM)と呼ばれるらしい。
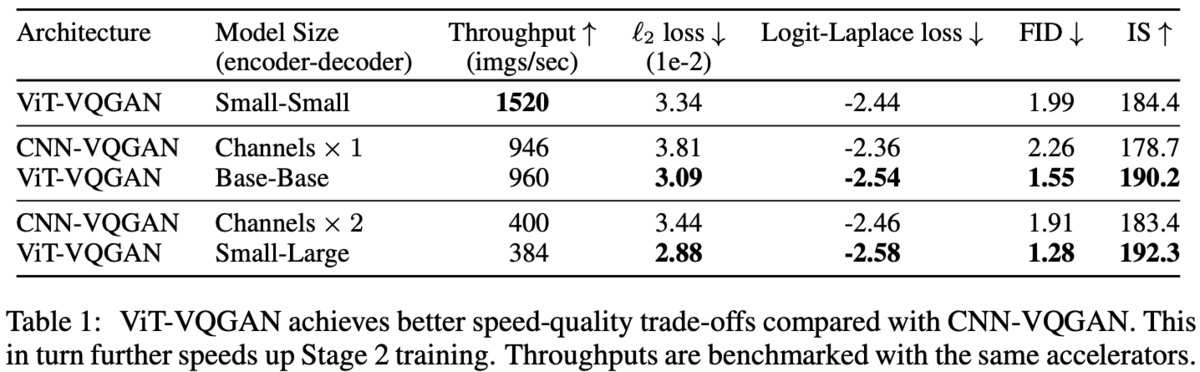
ベクトル量子化の結果は下流のタスク(ここでは画像認識と画像生成の2つ)に大きく影響し、より良いベクトル量子化は下流タスクの精度改善、学習の高速化にもつながる。

VECTOR-QUANTIZED IMAGES WITH VIT-VQGAN
VQGANをベースにベクトル量子化を改良していく。
CNN-VQGANとViT-VQGANのパフォーマンス比較は表1。
ViT-VQGAN
VQVAEもVQGANもCNNベースのencoder、decoderだったがこれをViTベースに変更する(ViT-VQGAN)。
8x8のオーバーラップなしでパッチを切り出しエンコードする(256x256は32x32=1024のトークンになる)。
また、transformerブロックの出力にtanhの活性化関数と2層のMLPを適用する。
ただしencoderとdecoderの出力には活性化関数は適用しない。
これらによりグリッドのアーティファクトが消えより高精度な画像が生成できる。
Codebook
ベクトル量子化の目的関数は式(1)の形。、
でstop-gradient。
がcodebookベクトル、
はencoderの出力。encoderの出力とcodebookベクトルをお互いに近づける感じ。

普通のVQVAEなどはcodebookの初期化が良いとはいえず、実際に使われないcodeが多い。
codebookの品質は画像の再合成や画像生成にも大きく影響する。VQGANでは1024のcodebookの選択をヒューリスティックな選択に依存し、高精度な画像を得ている。
大きなcodebook(サイズ8192)でも使用率を高くするため以下の2つの改善を行う。
Factorized codes
ルックアップのインデックスコードをencoderの出力を線形写像し低次元にする(768次元 -> 32次元 or 8次元)。
つまり実際にdecoderで使うのは高次元だが、codebookから検索するときは写像した低次元で行う。
これによりcodebookの使用率が向上。
低次元への写像はルックアップと埋め込みを分離する効果があると考えられる。
 -normalized codes
-normalized codes
encoderの出力とcodebookベクトル
に
の正規化を適用(球面に射影)。
正規化したので
と
のユークリッド距離はコサイン類維持度になる。
これにより学習が安定し、再構成の質も改善。
VECTOR-QUANTIZED IMAGE MODELING
Transformerのdecoderのみのモデルを利用して、画像データの密度P(x)を自己回帰でモデル化(式(2))。lossはnegative log-likelihood。

この学習済みモデルを用いて画像生成、画像分類を行う。
実験
論文を参照。かなり高精細な画像生成ができるがStyleGAN2には劣るといった感じ。


所感
正直VQGANをViTで置き換えたぐらいの印象でそこまで感動はなかった。Transformerを使って画像トークン列を生成するのもVQGANのTaming Transformerでやられていたので正直うーんといった感じ。
codebookのルックアップ用に低次元に写像 and 正規化はたしかに効果がありそう。
生成結果は悪くはなさそうだがのっぺりとしたスムージングをした感じの画像でノイズが少ないという意味では良さそう。自然物よりも人工物の生成が良さそう?
ベクトル量子化の方法としてCNNよりはViTを使った方が良さそうだが、ある程度の精度を出すのにどれくらいの画像が必要なのかが気になる。