ICASSP 2023
10秒のターゲット音声で変換ができるzero-shot any-to-anyな声質変換モデルの提案
一般的なvoice conversion(VC)ではコンテンツ(音素やテキスト)と話者を分離してターゲット話者情報で再構成スタイルが多い。
コンテンツ情報としてはASRの出力を利用することが多いが、ASRのミスや、そもそもASRの出力ではアクセント情報等が抜け落ちる問題があり、自然なVCが作れない。
最近では self-supervised learning (SSL)の特徴を利用することも増えてきた。
SSL特徴は主にコンテンツ情報とはいえ話者情報等を含んでいるので、それらを排除するため量子化したSSL特徴を利用することも多い。
しかし、量子化したSSL特徴は完全にコンテンツ情報を含んでいるが量子化前に不可逆な不完全なコンテンツ情報になっている。
もっと言えば話者情報を完全に排除できている保証もない。
これらをなんとしたいというお気持ち。
手法
提案手法は3つのコンポーネントからなる。
1) SSLベースの発話特徴抽出器
2) メルスペクトログラム合成器
3) HiFi-GAN vocoder
HiFi-GAN vocoderはそのままなので省略
Speech Representation Extractor (SRE)
コンテンツ特徴を抜き出すためのコンポーネント。
SREの全体像は図1参照。

アーキテクチャはConformerを利用。Conformerはconvとattentionからなるアーキテクチャで比較的軽量かつ長期的、局所的な依存関係を扱える。
メルスペクトログラムからConformer
を使って特徴量
を得る。
このはコンテンツ情報と話者情報を含んでいるので2つのヘッドを追加し、それぞれで別タスクを学習することで情報を分離させる。
Speech recognition
コンテンツ特徴を分離するためのヘッド。
2つのLinear層を追加し、
1つ目の層の後の特徴を、
2つ目の層の後の特徴をsoftmaxに通したものを
とする。
テキストと音声のペアデータを用意し、
を使って音声認識タスクを学習する。
lossはCTC lossで。
コンテンツ特徴としてはを利用するがこれだと
には
から話者情報リークしてしまい、合成時に
から話者情報を推定してしまう。
から話者情報を抜き出しコンテンツ情報だけにするためにピッチ変換した音声
を利用する。
から取り出したコンテンツ情報
とオリジナル音声からのコンテンツ特徴
でSiamese cosine similarity lossをとる。
はコサイン類似度。これにより
にはピッチ変換で不変な特徴 = コンテンツ特徴が残るようになる。
Speaker Verification (SV)
話者情報を分離するためのヘッド。
SREと同じく2つのヘッドを用意して
1つ目の層の後の特徴を、
2つ目の層の後の特徴を
とする。
音声と話者のペアデータを用意してangular softmax lossで学習する。
Mel-Spectrogram Synthesizer
コンテンツ特徴からメルスペクトログラムを合成する。
Mel-Spectrogram Synthesizerの全体像は図2参照。
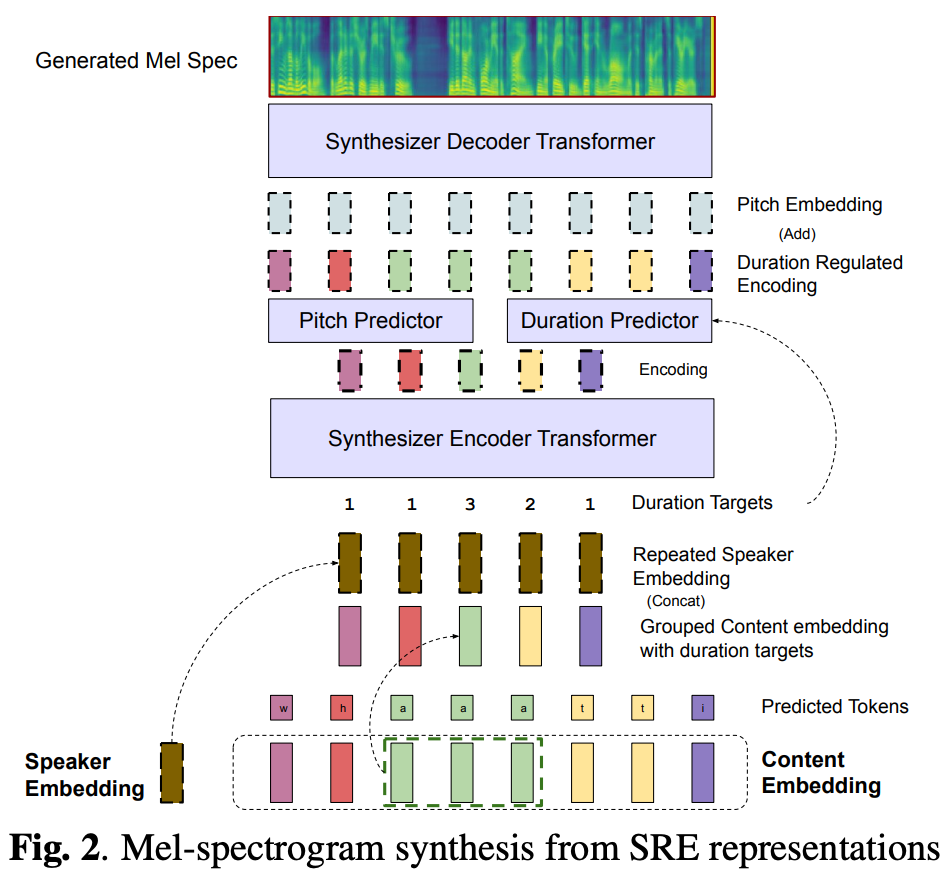
一般的にVCでは発話速度、つまりコンテンツ特徴の長さはオリジナルの音声で決まっている。
そのためdurationを合わせる必要がないが、言い換えると適応的にdurationを変更できないという制限がある。
durationを適応的にするためにコンテンツをグルーピングし、durationを予測するようにする。
グルーピングはSpeech recognitionのときの音素ラベルを利用し、連続する同じラベルのコンテンツ特徴をまとめる。
グルーピングしたコンテンツ特徴をとする。
これによりdurationのないコンテンツ特徴、つまりテキスト的な情報が得られる。
このと話者情報
から、対応するピッチとdurationを予測する。
中間特徴をとして、
durationは
ピッチは
ピッチ情報は埋め込み後、中間特徴に足され話者情報を含んだコンテンツ特徴になる。
このを元のdurationを使って長さに戻し、そこからメルスペクトログラムを予測する。
その時の連続した回数がdurationのラベル で、
ピッチやdurationはそれぞれ、学習時は真の値を利用し、テスト時は予測したもの利用する。
durationのGTラベル は連続した回数(図2のDuration Target)、ピッチのGTラベル
はYin algorithmで取得。
Mel-Spectrogram Synthesizerのlossは以下。
実験・結果
ConformerのSSLはLibriSpeechで。
SREはLibriSpeechで音声認識を、VoxCeleb-2で話者認識を学習。
Mel-Spectrogram SynthesizerはLibriTTSで学習
の効果を確かめるためのablation。
によりASR CERは不変だが、話者認識ができなくなっているのがわかる。
ただ、思ったより話者認識できており、ピッチ変換では消せない部分が結構あるなという印象。

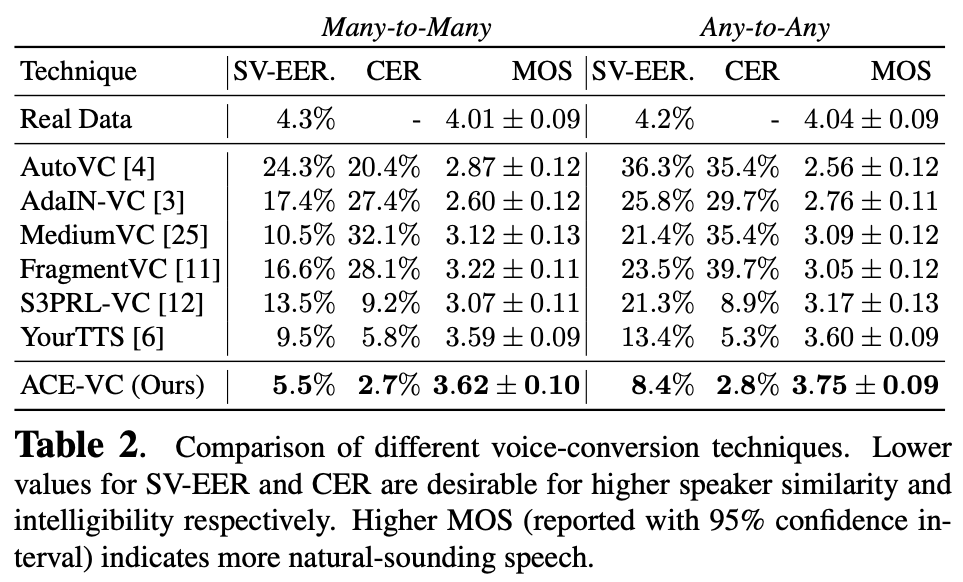
メインのVCタスク。many-to-manyとany-to-anyそれぞれ実験。any入力ではターゲット話者の10秒の発話を利用。
SV-EERは別の話者認識モデルを使ってのポジティブ・ネガティブそれぞれの音声とのerror rateで話者類似度の指標になるらしい。
全体的に既存手法より良さげ。
所感
よくあるdisentangle系のVCでものすごいテクニックとかは感じられなかった。
ピッチシフトした音声を利用したコンテンツ情報の抽出がそれなりの効果は有りつつも、話者情報が意外と残るなという印象。
もっと強いaugmentationをかければより良くなるのか?
VCの結果だけがあるが、このsiamese lossでdurationやピッチのlossがどうなったのか気になる。
conformer部分を既存のcontent vecで行えば簡単に再現できるかも?