[論文メモ] THE SINGING VOICE CONVERSION CHALLENGE 2023
歌声変換チャレンジ
概要
2016年から開始されたVoice Conversion Challenge(VCC)は対象話者への声変換をベース目標としてやってきた。VCC2020では自然性についてはまだ人間レベルではないにしろ正解話者との類似度は非常に高くなった。そこで音声変換ではなく、より難しい歌声変換を目標としSinging VCC(SVCC)に変更した。
歌声変換が声変換より難しいと考えられる理由は
1) 普通の発話と異なり様々なピッチ、音圧、表現や歌唱のスタイルがある
2) ピッチについては曲の音符に従いつつも、歌い方は歌手によって異なるのでそれらの情報を適切に扱う必要がある
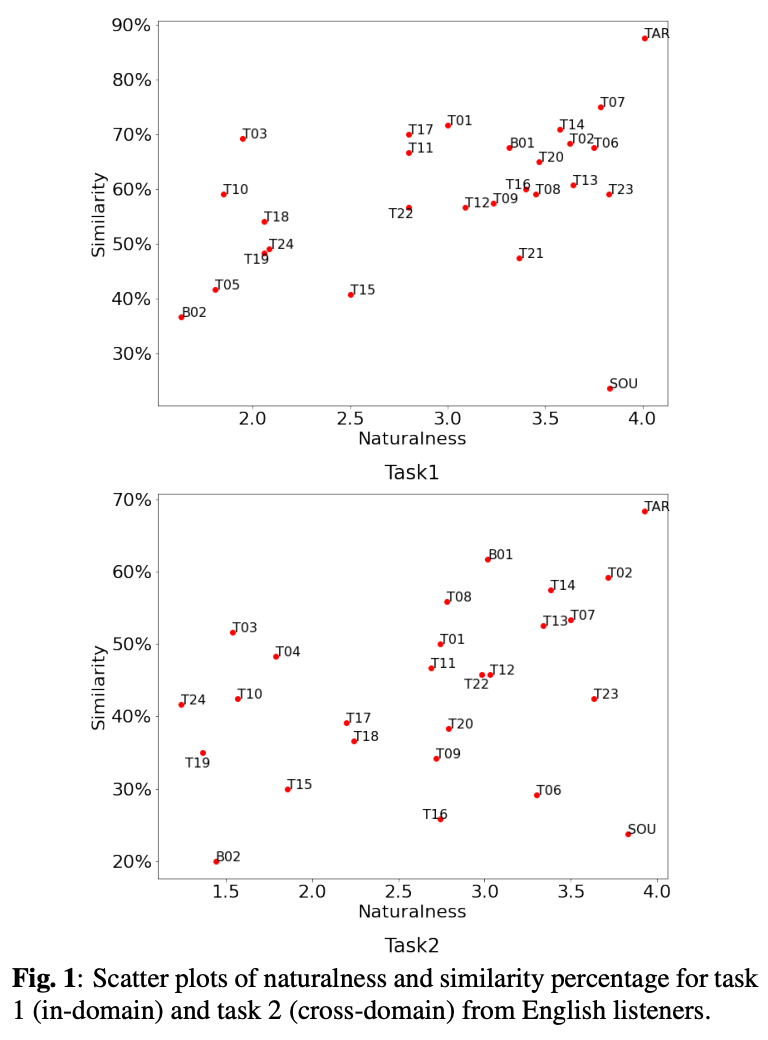
簡単な結果の概要が図1
参加者と手法概要
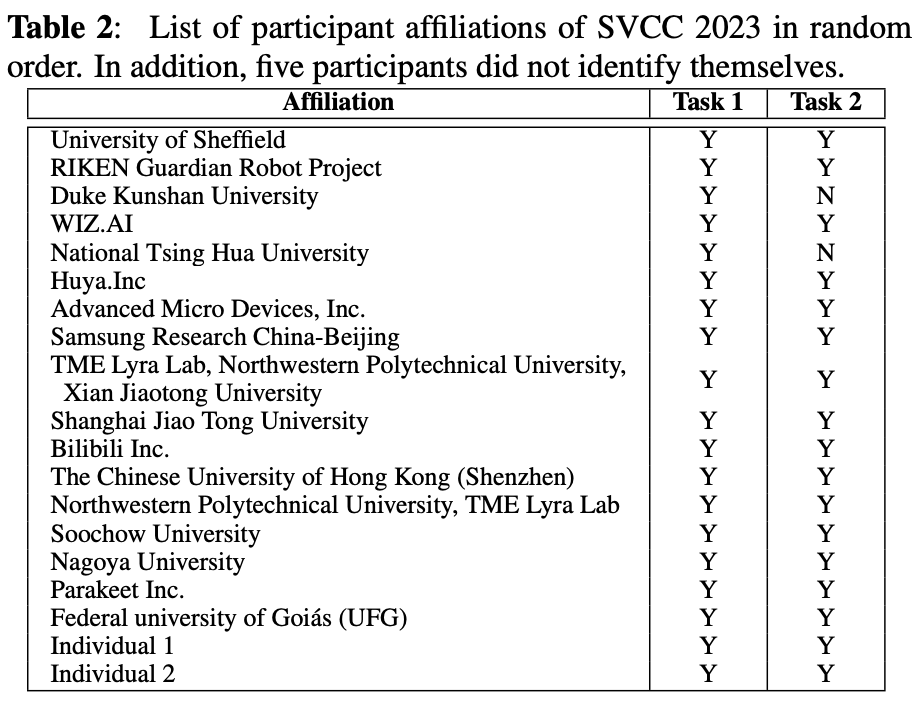
参加者は以下の表2の24チーム。
ベースラインの手法としてDiffSVC(B01)とDecomposed FastSVC(B02)を導入。
手法をVAEの有無、コンテンツ特徴、ボコーダについて分類してみたのが表3。
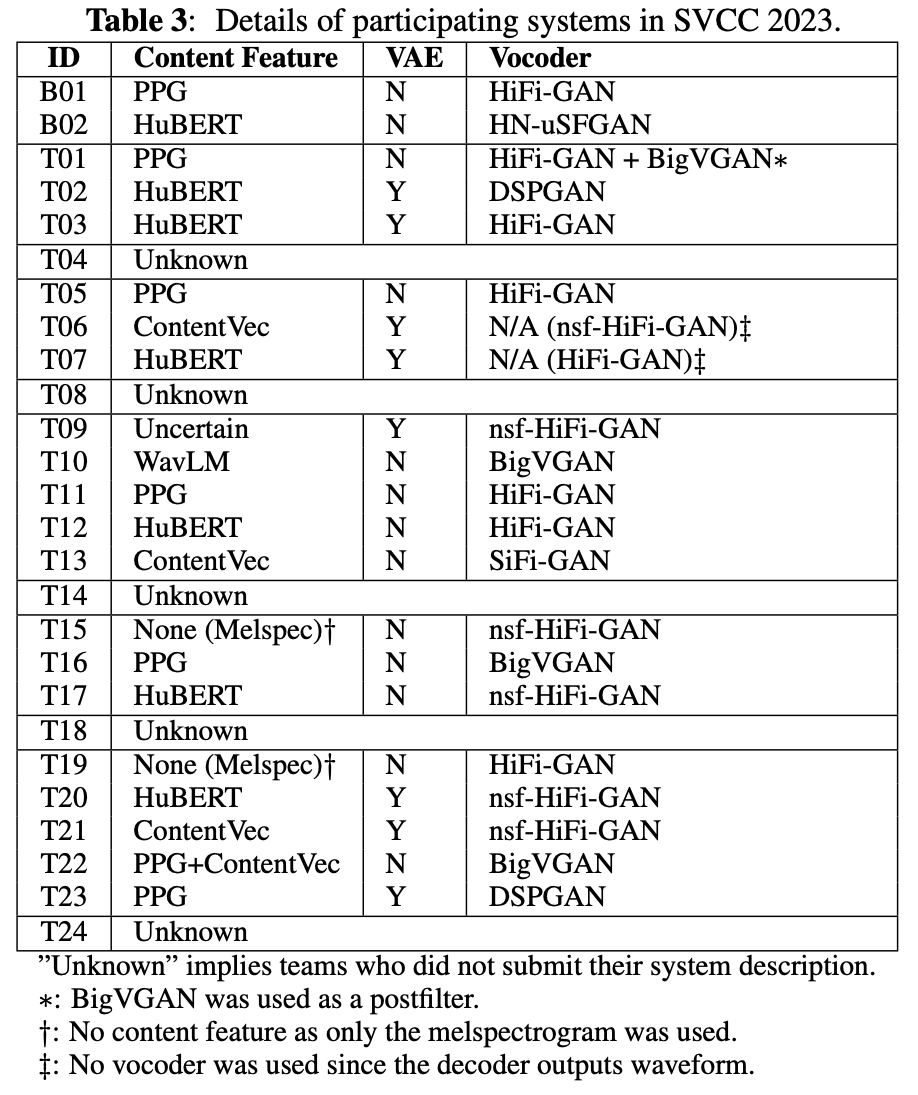
コンテンツはContentVec、HuBERT、PPGが多そう。
VAEは多くないが、トップに食い込んだ手法はVAEを採用している。
ボコーダはHiFi-GANやその派生が多い。自然性トップの手法はDSPGANだったが、サンプルが少なくDSPGANが自然性向上に有効かは判断できない。
評価と結果
評価指標は自然性と類似性。
評価者はAmazon Mechanical Turkではなく、2つの企業から日本語と英語のリスナーを募集した。70万円かかったらしい。
自然性
図2が自然性の結果。
タスク1ではT23がトップでタスク2はT02がトップ。どちらのタスクでもトップは同じ感じ。
どの手法もソースやターゲットを超えられなかった。
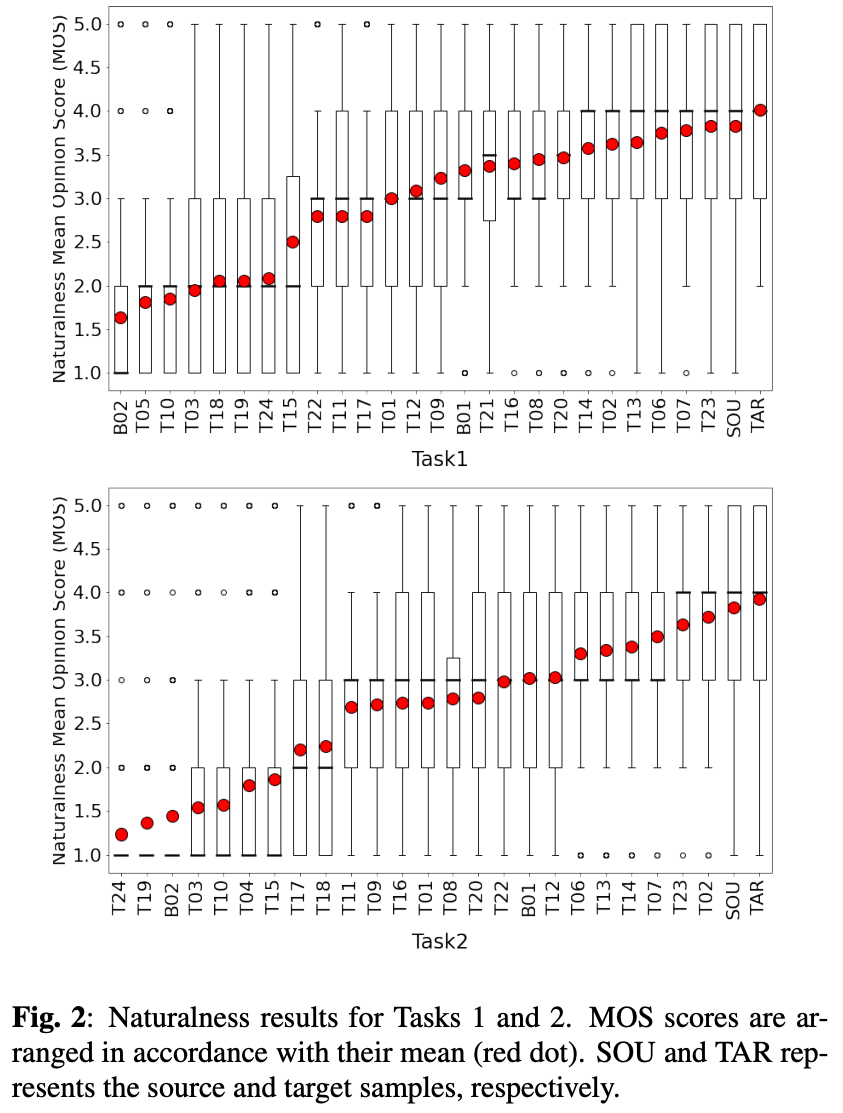
ただ図3(a)と(c)から、T23、T07、T02については実サンプルと優位な差がなく、トップシステムについては人間レベルの自然性と言えそう。
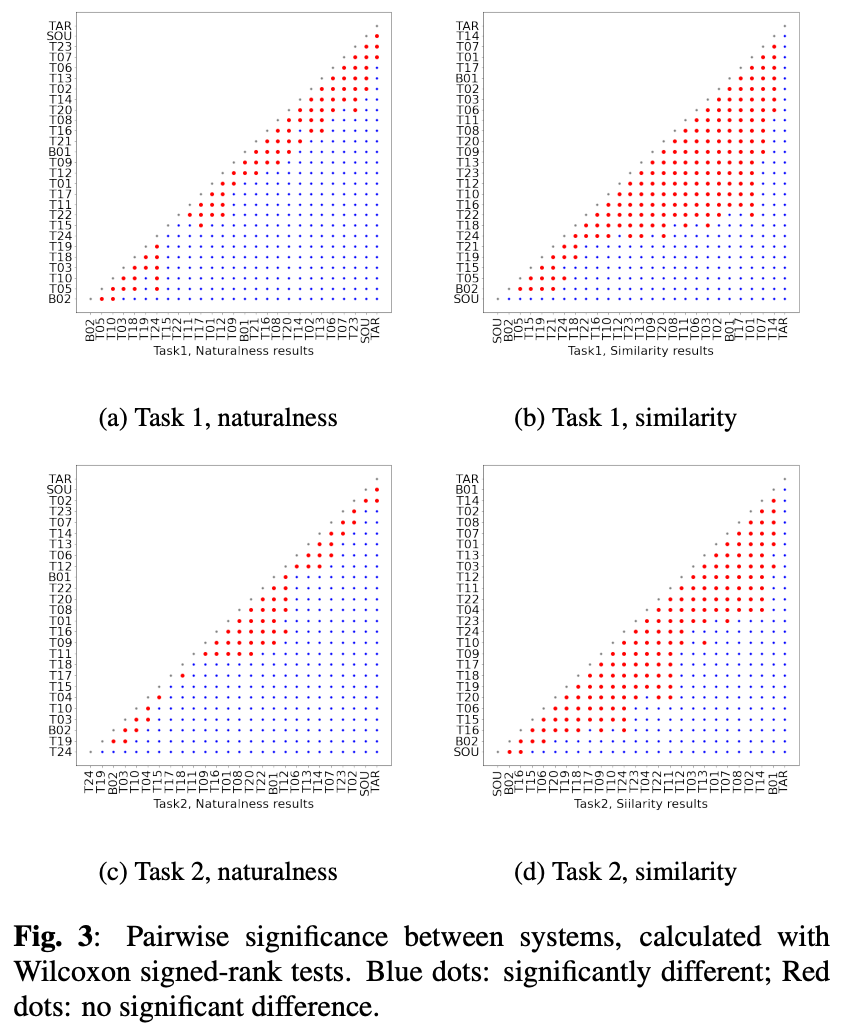
また、タスク2はスコア3.0を超えるのが8チームしかなく、タスク2のが難しいというのが確認できた。
類似性
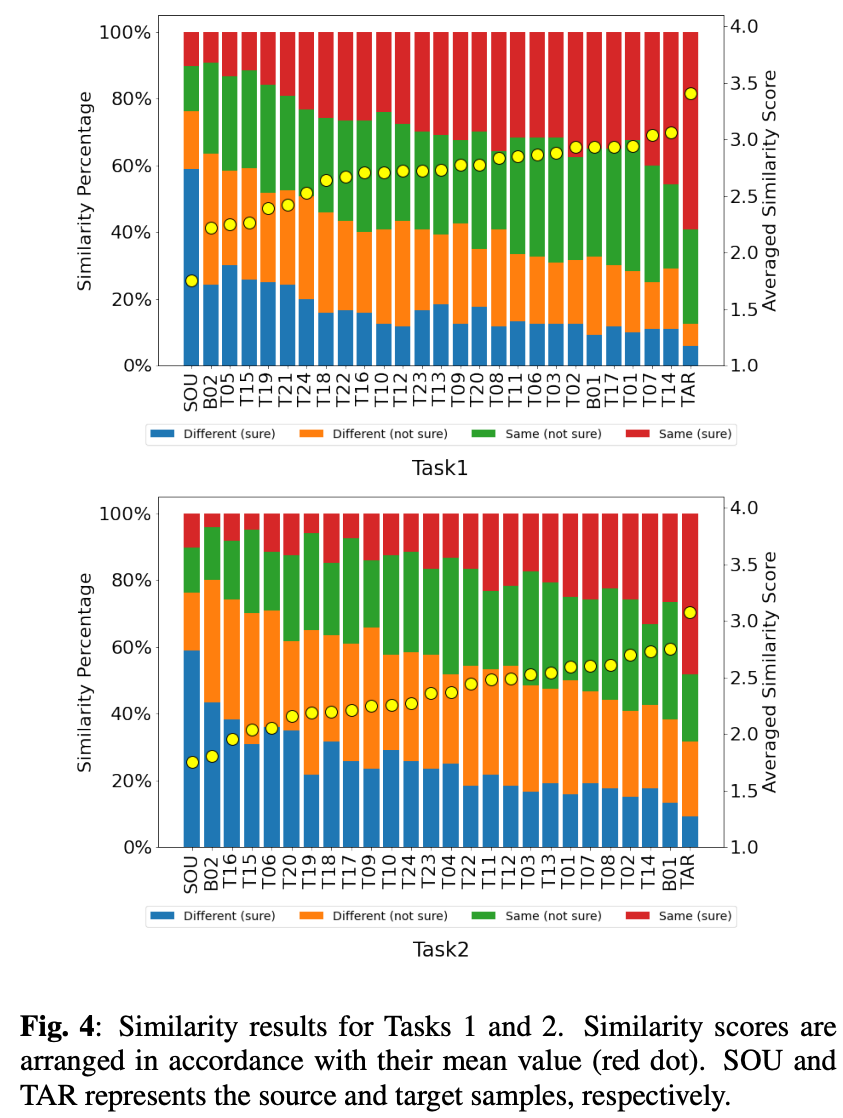
結果が図4。ベースラインB01が上位に来ている。
トップの手法とターゲットには0.4ポイントも開きがある。
図3(b)(d)を見ても、現状では類似性はまだ改善の余地がありそう。
また、類似性についてもタスク2のが難しいことがわかる。
日本語リスナーと英語リスナーの判断の違い
今回は英語音声なので日本語リスナーにとっては非ネイティブとなる。
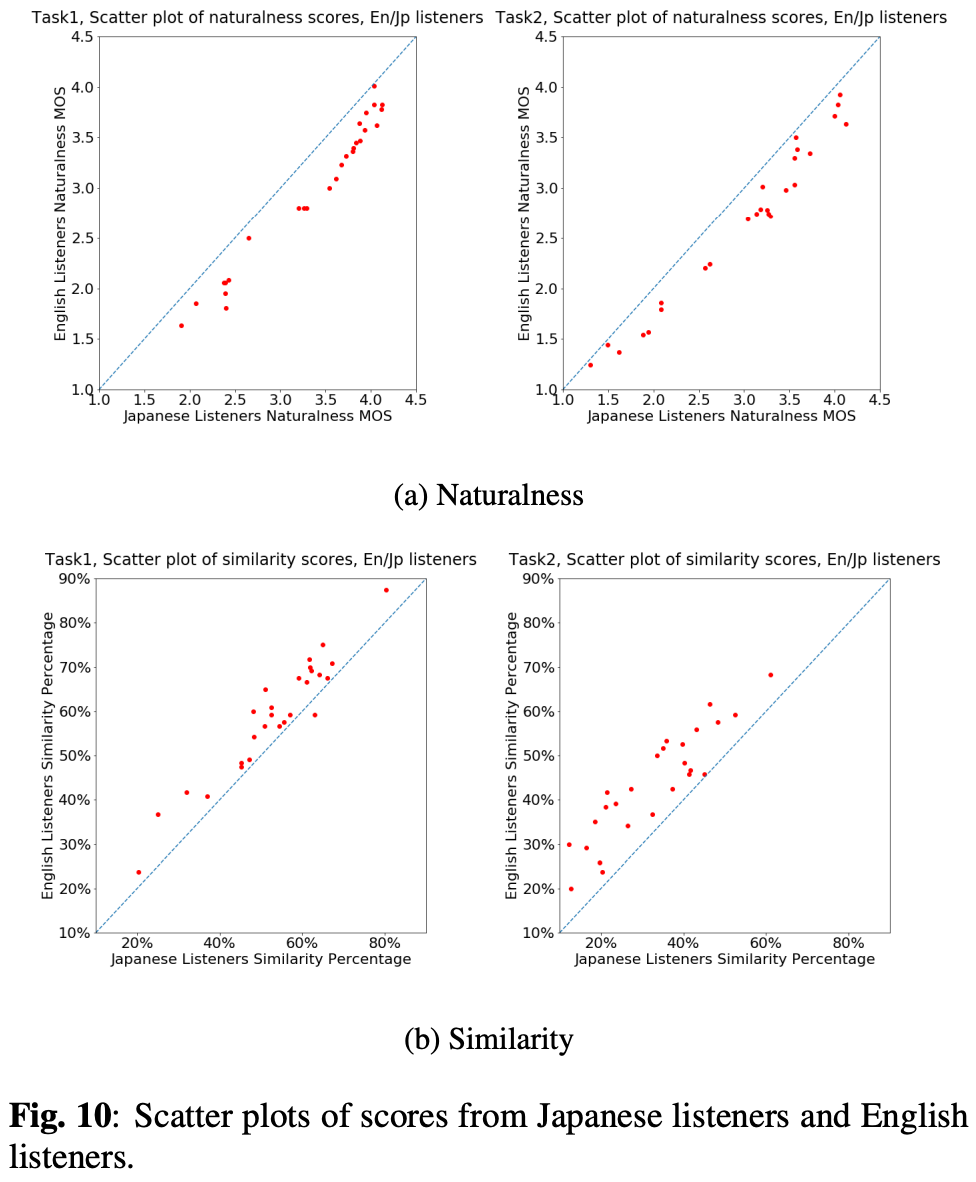
タスク1の自然性、類似性、タスク2の自然性、類似性について、英語リスナーとの相関係数を計算するとe 0.985、0.975、 0.985、0.924だった。
図10が散布図相関係数は大きいものの日本語・英語リスナーで傾向の違いが見られた。
- 日本語リスナーは自然性に高スコアをつける傾向
- 英語リスナーは類似性に高スコアをつける傾向
その結果日本語リスナーは変換した歌声を区別できない。
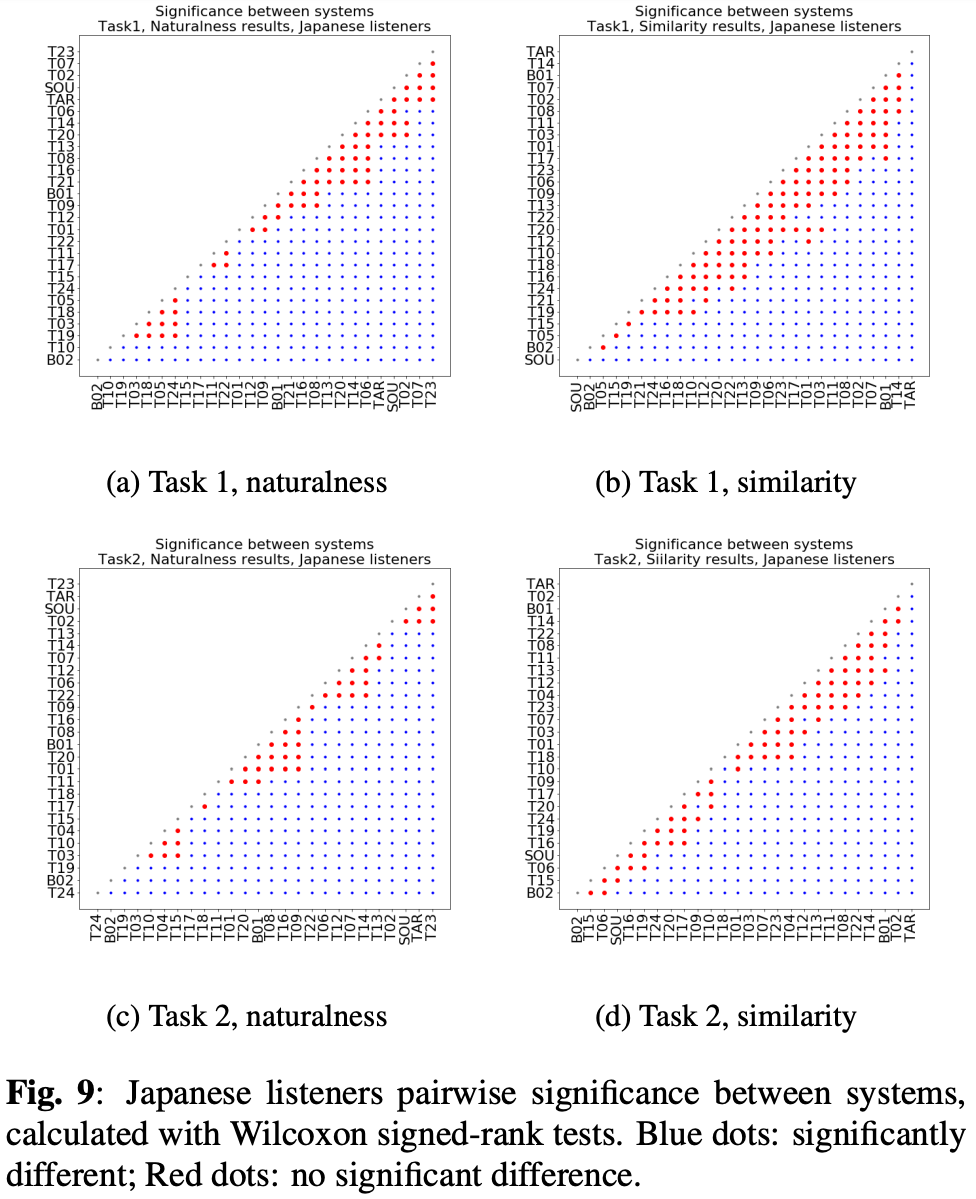
また、スコアの数が多いほどシステム間の統計的に有意な差異を観察しやすくなるという仮説を立てていたが類似性と自然性で異なる結果が得られた。
図3は英語リスナーについて、図9は日本語リスナーについての結果。
類似性についてはスコアが多いほど差が観測できたが、自然性は少ない英語リスナーで十分に信頼性のある結果が得られた。
自然性についてはスコアの数だけではなく、他の要素(文化や個人の趣向)の影響がありそう。
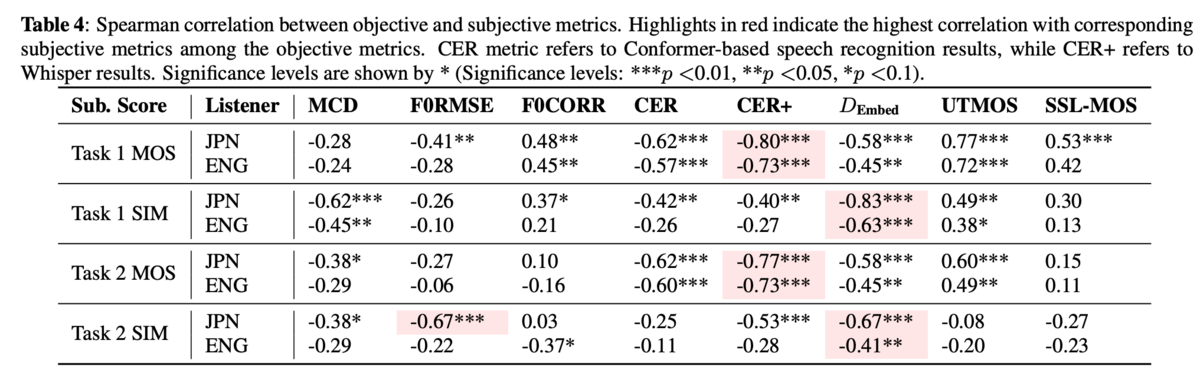
客観評価と主観評価の関係
mel cepstral distortion (MCD)、F0、歌詞(CER、CER+)、話者類似性()、MOSについて比較。
- スペクトログラムやF0は客観評価と主観評価に優位な相関はない
- 歌詞については相関がありそう
- 埋め込みによる話者類似性の評価は統計的に優位性を示したが、ネイティブとの類似性評価には微妙
- 音声コーパスで学習したMOS予測モデルでも中程度の相関がありそれなりの汎化能力
所感
音声変換ではなく歌声変換でのチャレンジ。普通の発話では出てこないピッチがあるので確かに難しそう。
リスナーの言語による評価の違いはわかる気がする。英語はまだしもあまり聞かない中国語のサンプルとか聞いても全く違いが分からなかったりする。
so-vits-svcがそこそこ使われているのもなるほどとなる。日本ではなぜかRVCが流行っているが海外ではやはりso-vits系か。
VAEの重要性が再認識できた。