[論文メモ] WAVE-U-NET DISCRIMINATOR: FAST AND LIGHTWEIGHT DISCRIMINATOR FOR GENERATIVE ADVERSARIAL NETWORK-BASED SPEECH SYNTHESIS
ICASSP 2023
Wave-U-NetをdIscriminatorとして採用する。
HiFi-GANやVITSではdiscriminatorのアンサンブルを採用し高品質な音声を学習している。
しかしアンサンブルすればパラメータが増加し学習時間が長くなる。
アンサンブルではなく、強力なdiscriminator1つで置き換えられないか?というお気持ち。
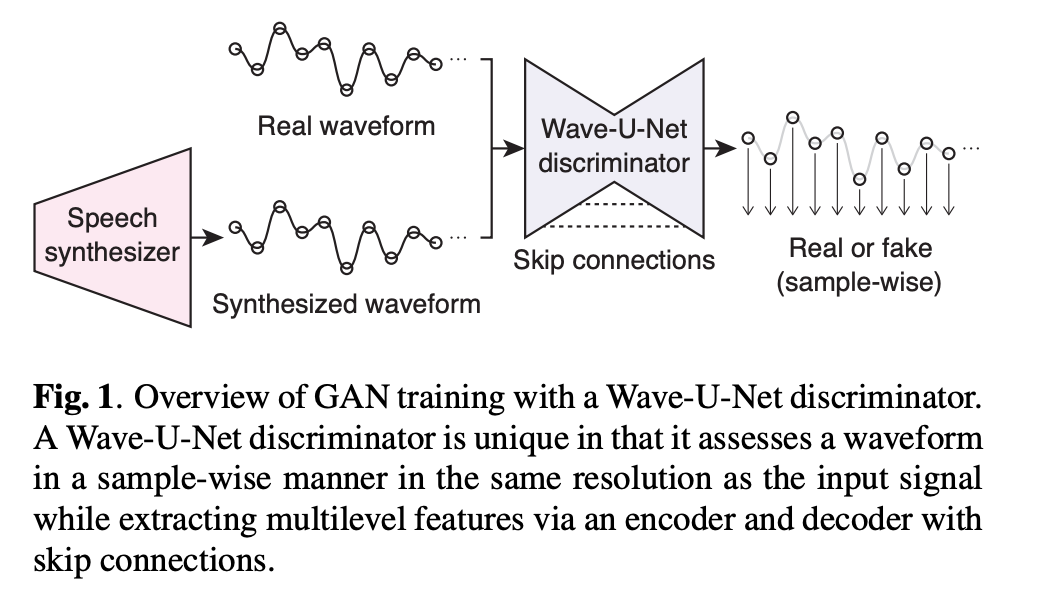
手法
Wave-U-Netをdiscriminatorとして採用する。
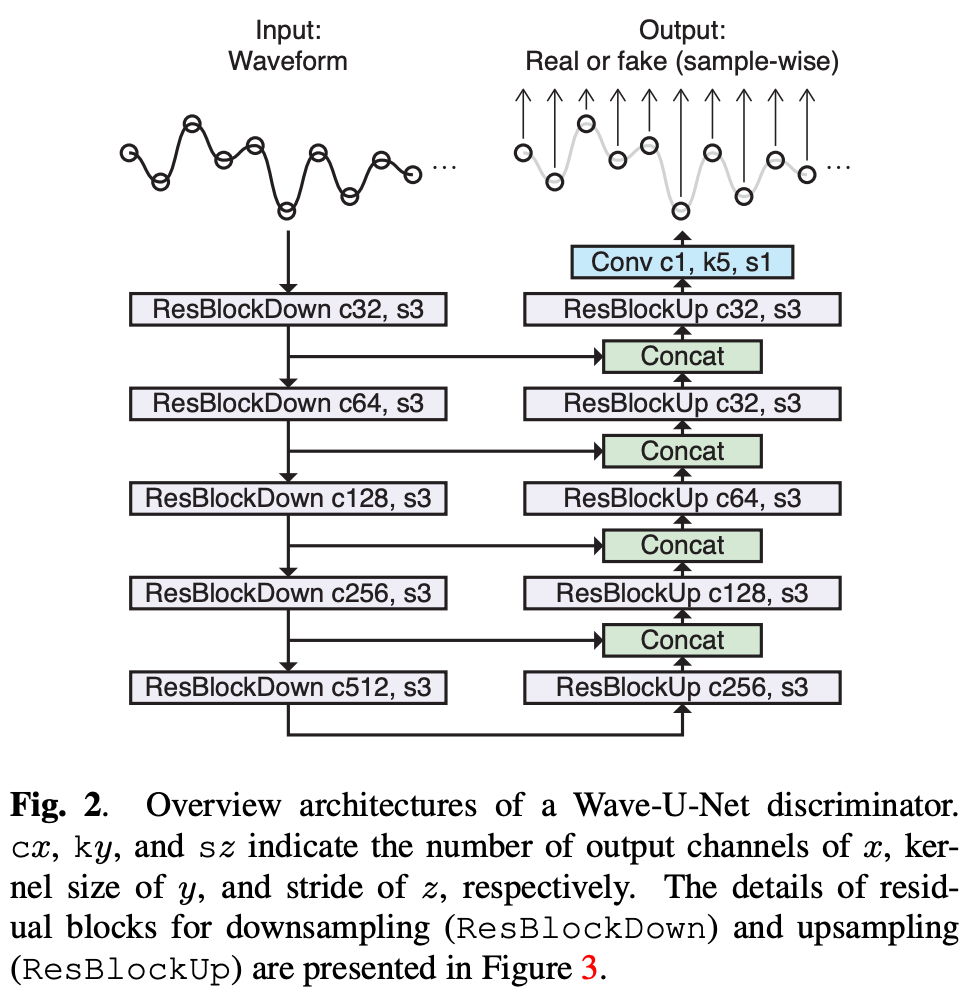
Wave-U-Netのアーキテクチャは図2を参照。
discriminatorは音声波形の特徴であるマルチスケール、マルチピリオドに対応できる必要がある。
HiFi-GANはそれぞれのdiscriminatorを利用している。
Wave-U-Netのアーキテクチャならこれに対応可能。
Wave-U-Netはエンコーダ・デコーダの形式で一般的なdiscriminatorとして採用されるエンコーダのみの構造と異なる。
各解像度での特徴をスキップ構造を持つデコーダに送りサンプル点レベルでのreal/fakeを判定する。これはPatchGANに近い。
単純にWave-U-Netを採用するのは学習が難しく、安定した学習のためにいくつかの工夫を行った。
Normalization
画像タスクでよく使われるspectral normやinstance normはあまり効果なし。
weight normに関しでもだめだった。これはWave-U-Netが既存のdiscriminatorと異なりエンコーダ・デコレータの深い構造だからかもとのこと。
そこでglobal normを提案。

は元の特徴、
はi番目の
の特徴。なお
。
これにより特定の特徴量に制限されるのを防ぐ。
Residual connections
層が多いせいか、global normを導入してもサチってしまう。
そこでresidual connectionを導入し勾配消失を防ぐ
Wave-U-Netを構成する各ブロックの最終的な構造は図3。

loss functions
adversarial lossとしてはLSGANのものを採用。

また feature matching lossも採用。なおはレイヤー数、
は
番目のレイヤーの特徴量、
は
番目のレイヤーの特徴量の数。

実験・結果
データセットはLJSpeech、VCTK、JSUT。
素のHiFI-GANをベースラインとして比較する。
またend2end手法としてVITSについても比較する。
評価指標はMOSとcFW2VD。cFW2VDは音声版FID的なもの。
HiFi-GANでの実験結果が表1, 2, 3。
Wave-U-Netにしたことで大きな品質の劣化はないが、学習速度が2倍以上になったことがわかる。パラメータも14.5倍程度軽量になった。

VITSでの学習結果が表4。
HiFi-GANのときと同じような結果が得られている。

所感
Wave-U-Netをdiscriminatorに採用するというシンプルだが効率化できる良い手法。
U-Netをdiscriminatorに採用するは画像のときにもあったのでむしろなぜ今までやらなかったのか不思議。安定しなかったから?音声へ注目が小さかった?
最近は思考停止してHiFi-GANのMPDとMSDを採用する手法が多いので、こういったところの改善はありがたい。
また、最近ではRVCやso-vits-svc等の声質変換も盛んで、これらは研究ではなく数実験してみての世界なので1回の試行が高速化されるのは発展に繋がりそう。
パラメータが少なくなり、その分generatorやバッチサイズを大きくできるのも嬉しい。
ただ、画像のときのU-Net discriminatorが自分で実験したときに論文ほどあまりうまくいかなかったのでそこが心配。
あと、discriminatorのreal/fakeがフレームでどうなっているかのサンプル画像が欲しかった。