[論文メモ] NNSPEECH: SPEAKER-GUIDED CONDITIONAL VARIATIONAL AUTOENCODER FOR ZERO-SHOT MULTI-SPEAKER TEXT-TO-SPEECH
arxiv.org
間違えてるかもしれないので注意。
Conditional VAE(CVAE)を使ったzero-shot text-to-speech(TTS)の提案。
既存手法だとほかfine-tuningしたりタスクで学習したSpeaker Encoderを使ったりする方法があるが、fine-tuningはデータの保存や学習コストが高い(ユーザーが多いと更に大変)、Encoderを使うのはクオリティが低い(Encoderの解像度だと表現しきれない)。
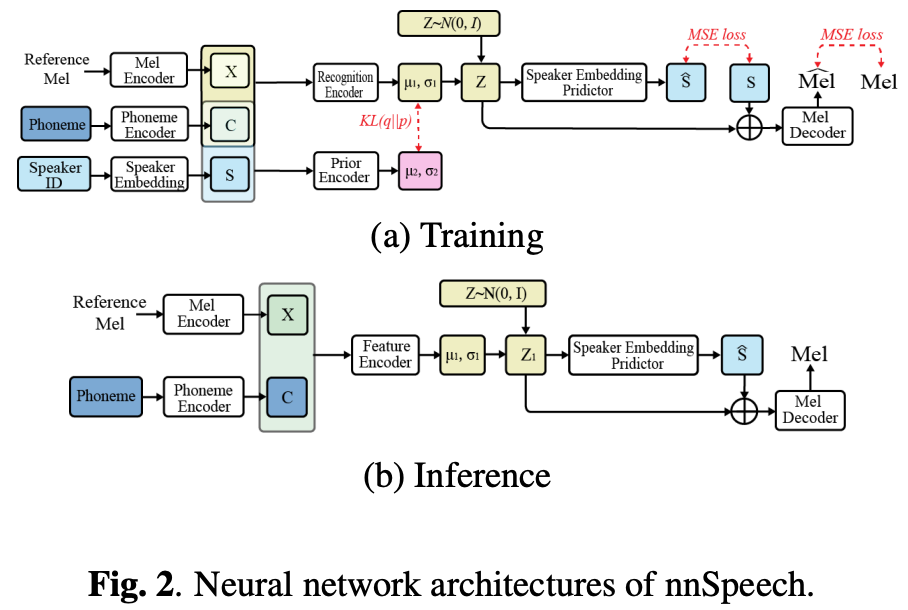
なので提案するnnSpeech(no new speech)ではSpeakerをガイドとしたCVAEを利用してzero-shot化する。
手法
CVAEは条件付きのVAEで下記の条件付きの対数尤度で学習する。
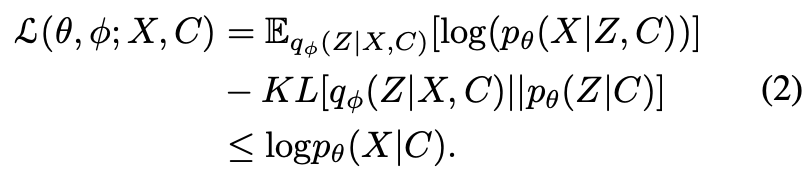
をメルスペクトログラムEncoderの出力、
を音素Encoderの出力とする。
メルスペクトログラムEncoderはAdaIN-VCのものを、音素EncoderはFastSpeech2のものを利用する。
条件付き分布を考える(
、
はネットワークでモデリング)。
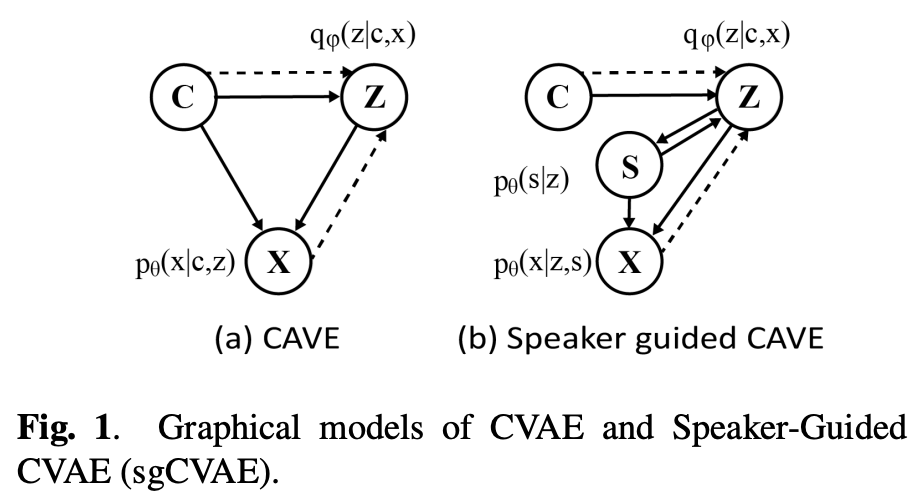
図1(a)のように真のを
でモデリングすると、メルスペクトログラム
を再構成するときに潜在変数
が話者情報を持つ必要があるため直感に反する。
そこでspeaker-guided CVAEを提案する。が話者情報
に基づいていると仮定する(
)。そして
を
で予測する。
は
の情報を含んでいるので
とできる。
もとの条件付き分布を書き換えて、になる。
と
はガウシアンに従うと仮定して、それらの平均、分散は
からMLPで予測する。
lossは話者情報で変更したELBOの最大化

一項目と二項目のは生成したメルスペクトログラムと話者埋め込みに関するものでELBOの最大化のためにはMLEを最小化すれば良い。

三項目はKLの最小化。
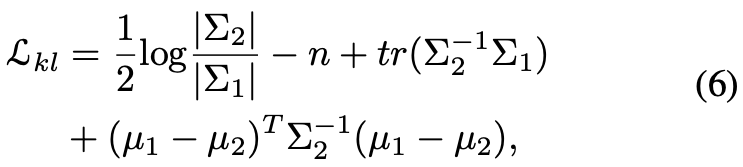
最終的なlossは下記ではハイパラ。

なおボコーダはHifiGANを利用。
実験・結果
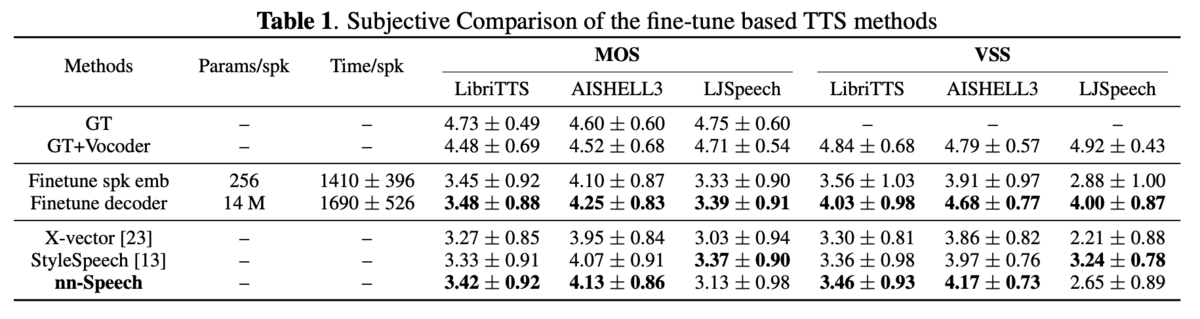
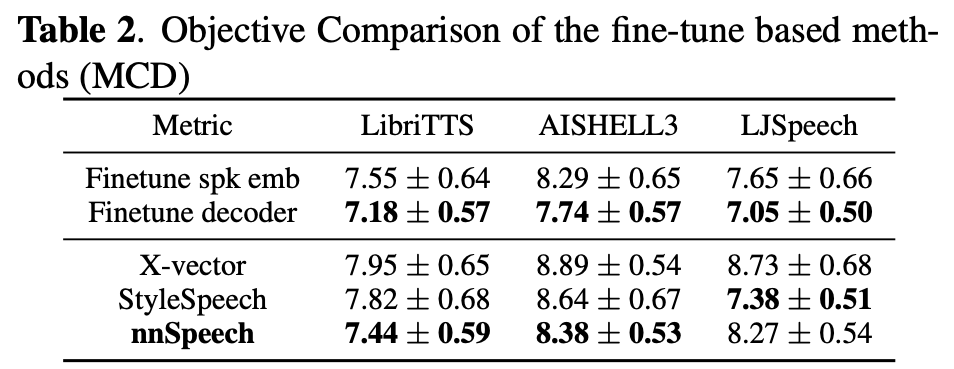
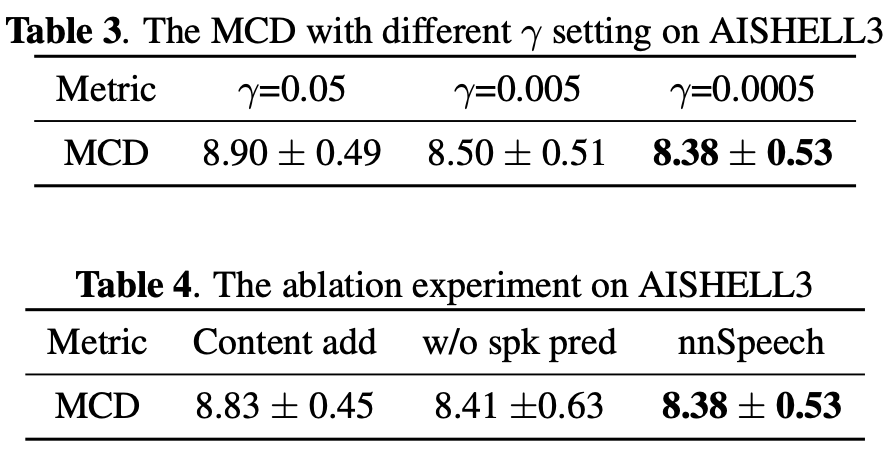
所感
paper内でデモや結果のリンクがなかったのは珍しい(VC系は最近デモの公開が多いので)。
それ故に少々結果は懐疑的。ぶっちゃけ数字だけでは何もわからない。