[論文メモ] Multimodal Conditional Image Synthesis with Product-of-Experts GANs
スケッチやテキストなどのマルチモーダルを条件としたProduct-of-Experts Generative Adversarial Networks (PoE-GAN) の提案。

既存のConditional GANは条件としてスケッチやテキストなど1種類の入力を条件としていた。しかし、それだとスケッチのが説明しやすいときや逆にテキストのが説明しやすいときなどの場合に対応ができないよねというお気持ち。
手法
個モダリティ
と画像がペアになったデータセット
が与えられたとき、これらのモダリティの部分集合を入力として画像を生成する生成モデルを学習する(
)。
条件が個あるので
通りの条件での生成が可能で、当然モダリティが1つの場合(
)や空の場合(
)でも生成できる必要がある。
モダリティとしてはテキスト、スケッチ、セグメンテーションマップ、画像(スタイルのリファレンス)を採用するが、フレームワーク的には他のモダリティも簡単に導入できる。
Product-of-experts modeling
条件として入力するモダリティは画像生成時に満たすべき制約であり、与えられた条件を満たす画像集合はそれらの条件を1つずつ満たす画像集合の積集合の部分になる(図2)。

ということで同時分布がある1つのモダリティ条件とした分布
、
の積として表現できると仮定する。
このように個々モダリティから生成する”エキスパート”を"掛ける"のでproduct-of-experts(PoE)と呼ばれる。
Generatorはlatent code を入力して画像
を生成するが、
は
に対して一意に決定するので
を求めるのは
を求めるのに等しい。
をpriorとして
を構成するのにPoEを下記のようにモデリングする。

は一つのモダリティを条件としたエンコーダ。
Multiscale and hierarchical latent space
テキストとスケッチなどでモダリティの解像度が異なるのでlatent spaceもそれに合わせて階層化する。
とし、
は特徴ベクトル、
を解像度ごとの特徴マップ(
,
は画像と同じ解像度)とする。
したがって先程の式(1)の各要素が分解でき、下記の式(2)のようにできる。

より解像度の低い、抽象度の高いを条件として、その積の形式になる。
ここで、
は平均と分散をニューラルネットでパラメータ化された独立したガウシアン。
なおはガウシアンの積なのでガウシアンになる(下記の式3)。
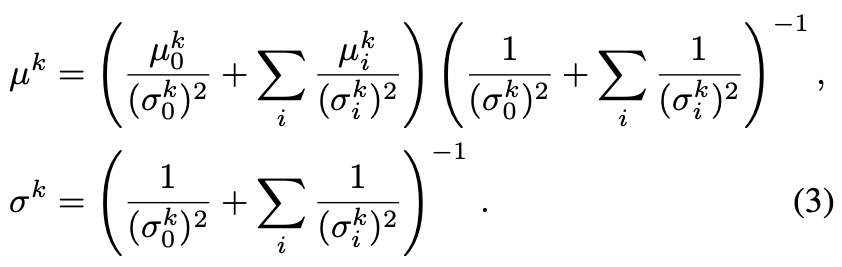
. Generator architecture
アーキテクチャは図3を参照。各モダリティをエンコード後、Global PoE-Netで集約する。

セグメンテーションマップとスケッチは入力をskip connectしたCNNで、スタイルはResNet、テキストはCLIPを使ってそれぞれエンコードする(図11)。

Global PoE-Netは図4参照。
MLPでガウシアンを予測し、
をサンプリング。これがdecoderのメインの入力になる。
decoderはResBlockからなる(図5を参照)。

を入力としてそれに対してconvolutionをするのがメインだが、途中で解像度毎のセグメンテーションマップとスケッチを式(3)のPoEで処理した
を使ったSPADEと
をMLPに入れて得た特徴ベクトル
を使ったAdaINを行うlocal-global adaptive instance normalization(LG-AdaIN) レイヤーを挟む。

テキストやスタイル情報は画像全体の大まかな情報を持っているのに対して、セグメンテーションマップやスケッチは画像の詳細も含んでいることを考えると、セグメンテーションマップとスケッチのみ途中で注入するのは理解できる。
Multiscale multimodal projection discriminator
Discriminatorは画像と条件
を受け取り本物かどうかのスコア
を出力する。
各モダリティが独立と仮定すると下記の式。

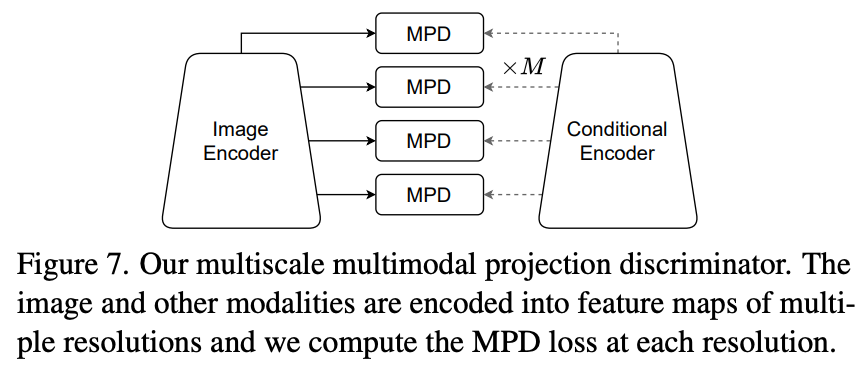
Projection Discriminator(PD)をマルチモーダル用に一般化したMultimodal PD(MPD)を提案(図6)。

画像、条件それぞれを特徴空間に埋め込み、条件なし項に関しては画像埋め込みをLinearで出力、条件ありの項に関しては条件の埋め込みと内積を取り、それらの和として表現するのがPDだが、MPDでは条件ありの部分を条件の数だけ増やす(式6)。

セグメンテーションマップとスケッチに関しては空間的なモダリティなのでそれぞれの解像度毎でMPDを行う(Multiscale MPD)
Losses and training procedure
Latent regularization
PoEの仮定(式1)の元、条件について周辺化したpriorと条件なしのpriorは一致する。

なので各解像度でKLを最小化。はモダリティに対して、
は解像度に対しての重み。

Contrastive losses
contrastive lossはペアデータのバッチが与えられたとき、式9のように、ペアでないものに関しては離したままペア同士は似るようにするloss。

ここでは画像に関してと条件に関しての2種類のcontrastive lossを利用。
画像に関しては学習済みのVGG encoderを用いて本物の画像と、その条件から生成した画像
について類似度を最大化する。

perceptual lossに似てるが、それよりパフォーマンスが良いらしい。
条件に関しては2つあり、1つ目は本物の画像と条件
それぞれの埋め込みに対してで下記。

はDiscriminatorの中間表現で式6と図6(b)を参照。
このlossはあくまでDiscriminatorのupdate用で、Generatorには本物の画像ではなく生成画像に関してlossをとる。

最終的なlossは以下。

は重み、
は
のgradient penalty。
実験・結果





所感
複数のモダリティを条件としたときのcGANの提案。
思っていたよりシンプルだった(全部埋め込みにして生成)。
確かに、テキストやスタイルのが表現しやすいこともあるし、スケッチで表現したいときもある。
参考になった点は
1つ目はモダリティによって入力する場所を分割すること。確かにスケッチやセグメンテーションマップは生成結果の詳細部分への制約になるのでそれなりの解像度を保ったまま入力したい。逆にテキストやスタイルは画像全体に関わることなので入力で十分。StyleGANの生成結果制御でも似た議論があった。
2つ目はKL loss。確かに周辺化すれば一致するよね。
3つ目はLG-AdaIN(AdaINとSPADEの融合)。取り扱う情報の解像度に合わせて2種類を使い分けるのはなるほどとなる。
自分でcGANを使うにあたって参考になることが多かった。