[論文メモ] Disentangling Style and Speaker Attributes for TTS Style Transfer
speech style transferにおいてseen、unseenの両方を改善したAE型のEnd to End なTTSモデルの提案
手法
全体像は図1
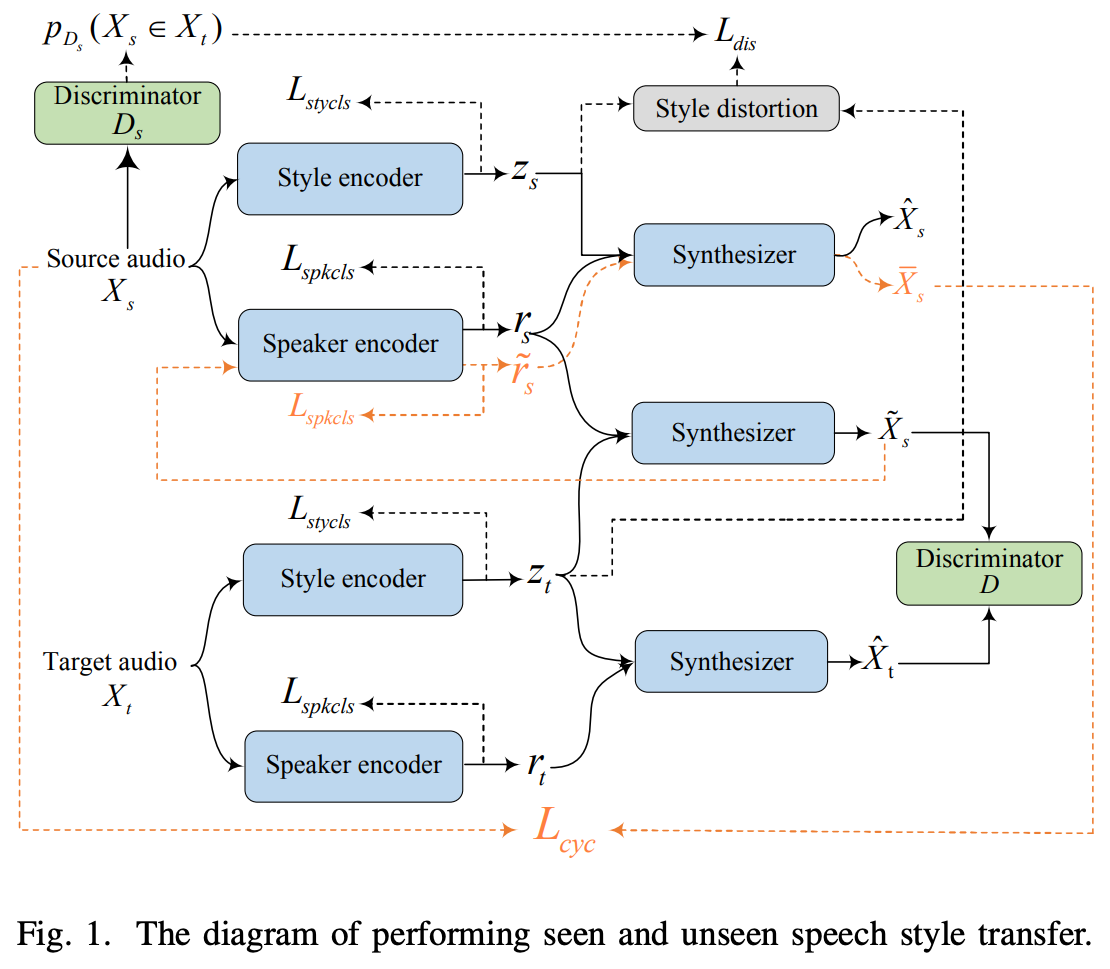
ソースとなる発話を、ターゲットとなる発話を
とする。
これらの発話はスタイル特徴と話者特徴
に分けられるとする。
ソースとターゲットに含まれるそれぞれの発話と
は個別のスタイル
、
を持つ。ここでいうスタイルは話し方や感情、韻律などを示す。
そしてスタイルエンコーダーを、話者エンコーダーを
とすると、
ソース発話のスタイル特徴:
ターゲット発話のスタイル特徴:
ソース発話の話者特徴:
ターゲット発話の話者特徴:
となる。
SynthesizerモデルとしてはTacotron2を用い、とする。
はスタイル特徴
と話者特徴
を入力とし、メルスペクトログラムを出力する。
仕組みとしてはソース・ターゲット発話を各エンコーダーでスタイル特徴と話者特徴に分離させ、各特徴の組み合わせで生成したメルスペクトログラムを色々なlossで最適化する感じ。
lossは6つあり、reconstruction()、adversarial(
)、style distortion(
)、cycle consistency(
)、style classification(
)、speaker classification(
)。
詳しくは後で。
Style Space
が学習すべきスタイル空間について。
スタイルを表現するのにガウシアン分布を使ったVAEだと不十分な場合がある。
そこでInverse Autoregressive Flow(IAF)を採用する(図2参照)。
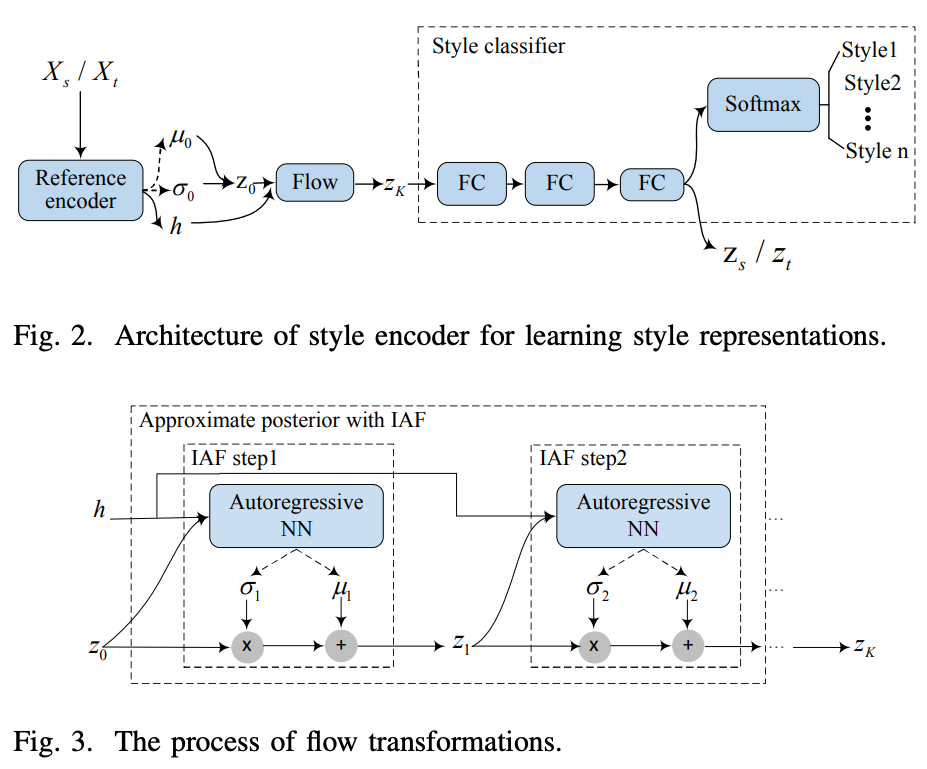
始めのエンコーダでを出力し、ランダムサンプルした
を使って
初期値を生成し、それを繰り返す(
)。
をflowの最後の出力とすると確率密度は以下の式で得られる。
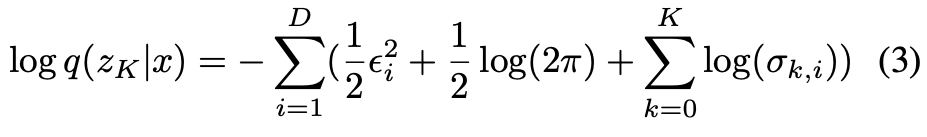
下記の記事が参考になった。
peluigi.hatenablog.com
Speaker Encoder
既存手法ではvoxcelebコーパス等を使って話者エンコーダを事前に学習しているものが多い。
提案手法では話者エンコーダを同時に学習する。
話者エンコーダのアーキテクチャは図4を参照。
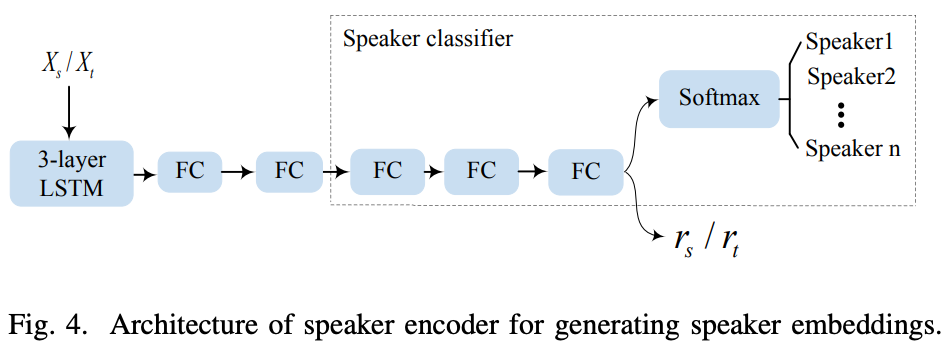
活性化関数はReLUでクラス分類のヘッドはスタイルエンコーダと同じく3つのFC層。最後のFC層の出力が話者特徴になる。
Six Specifically-designed Objectives
6つのlossについて
は最適化対象のネットワークのパラメータ。
は同じ発話のスタイル特徴と話者特徴から生成したメルスペクトログラムが元のメルスペクトログラムと同じになるように。
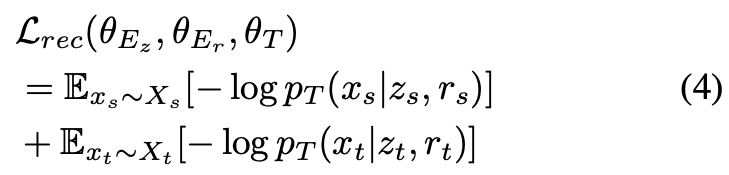
これでと
にメルスペクトログラムを復元するのに必要が情報が盛り込まれる。ただ、まだ2つの特徴量に何が含まれるかは不定。
は出力結果のスタイルがターゲットスタイルに従うように。
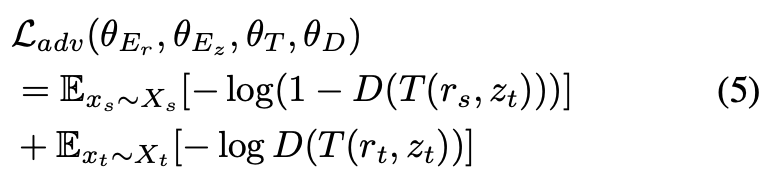
これによりには最低でもターゲットのスタイル情報が盛り込まれる。(
にすべて盛り込むこともできそう)。
上記のlossだけだとに制約がなくスタイルを学習する保証がない。そしてこの問題は話者特徴にも影響する。
そこでdistortion loss を導入する。これは
を
に近づけるためのもの。
はじめにdiscriminator を発話がターゲットの発話であるか否かを学習する(
)。
そしてを学習するときに
を使って
と
、2つの歪みが一定になるように強制する。
を
ノルムとして以下の式の制約を課す。
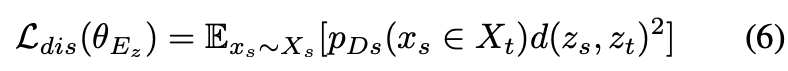
distortion lossは生成した発話がターゲットのスタイルになるようにするためのもので、話者についての保証がない。
話者を一致させるためにcycle consistency lossを導入。
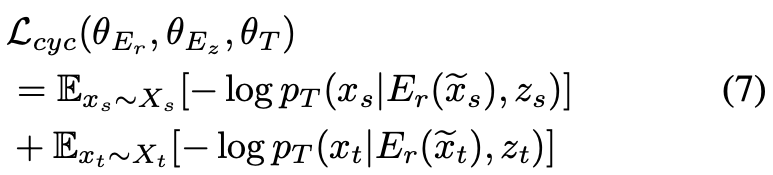
は
をターゲットのスタイルに変更したもの。
スタイルを変更した音声から話者エンコーダで話者特徴を取り出したとき、それはスタイル変更前の音声と同じ話者であってほしいという感じ。
これにより
そしてスタイルと話者をよりしっかり分けるためにそれぞれをクラス分類する(と
)。
最終的なlossは以下の式で、各lossについている文字はそれぞれの重み。
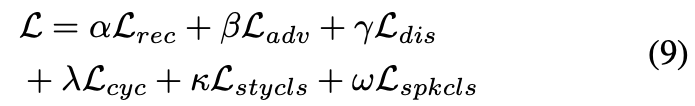
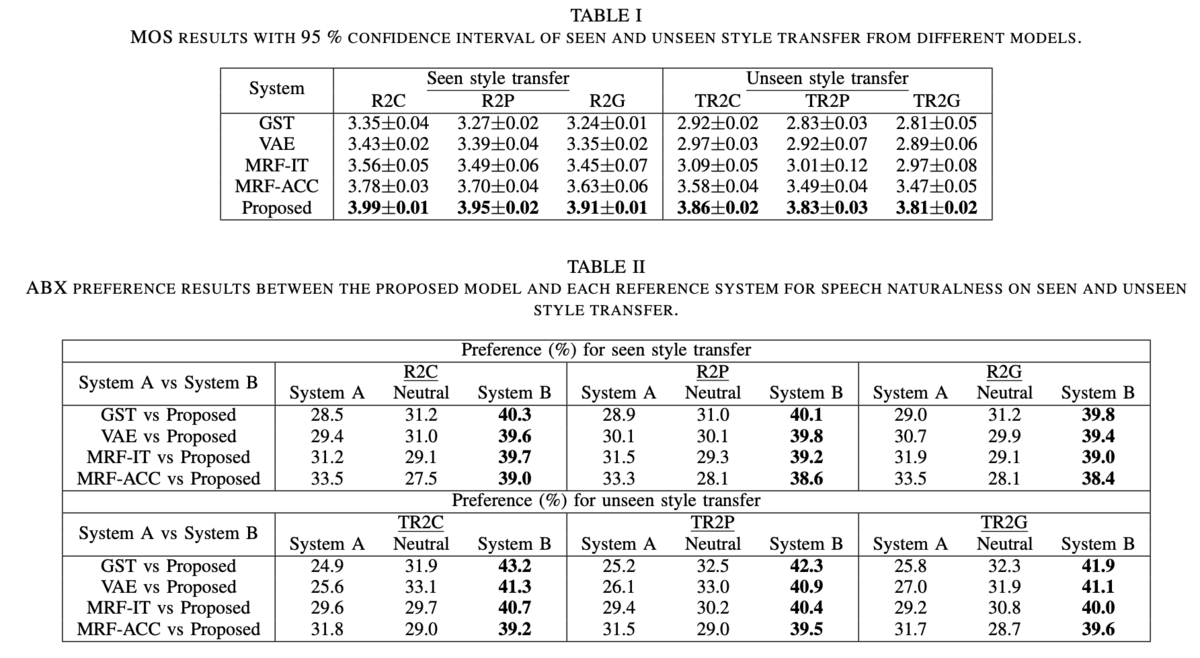
実験・結果
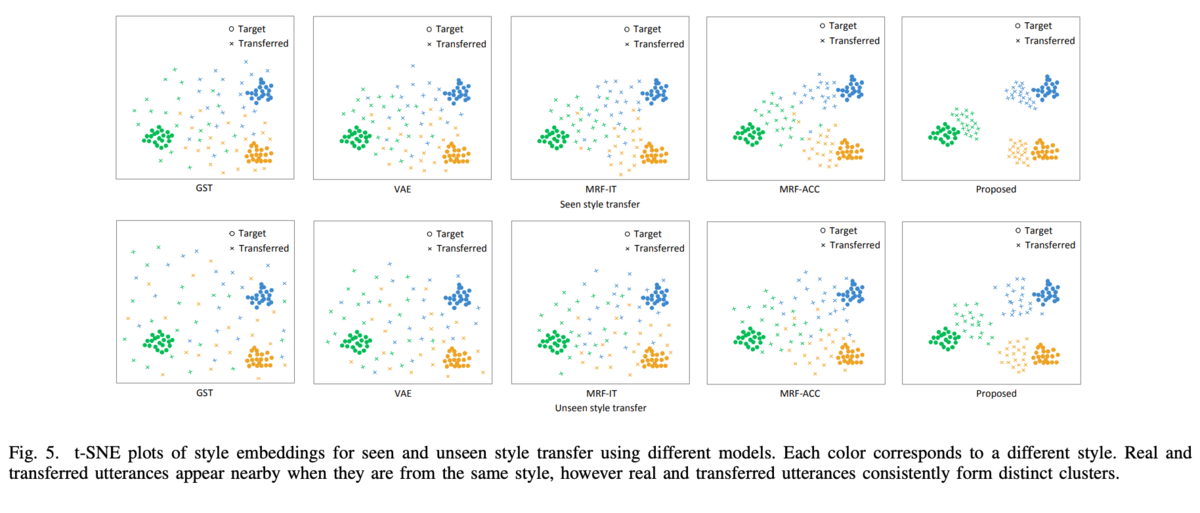
所感
いろんなlossでガチガチに縛った感じ。
整理しないと各lossの役割がこんがらがってしまう。
音声のスタイルというのがいまいち分かりにくい。話し方とか感情とか言われればなるほどとならなくもないが、この手法ではスタイルと話者を分離していて、それではコンテンツはどこに行ったの?(多分スタイルに含まれていそう)となる。
話者とスタイルの分離なのでコンテンツが含まれていてもいいのだろうけど、スタイル特徴と言い切れないのがなんとも。
そしてに発話情報が入っていても問題なさそうに見えるが、何か見落としている?そのためのdistortion loss?
デモが公開されているけど中国語なので正直違いがわからない。