[論文メモ] TRAINING ROBUST ZERO-SHOT VOICE CONVERSION MODELS WITH SELF-SUPERVISED FEATURES
arxiv.org
教師なし学習によるVoice Conversion(VC) modelの学習
執筆当時、結果のURL。
trungd.github.io
あくまでメモ。間違っているかもしれない。
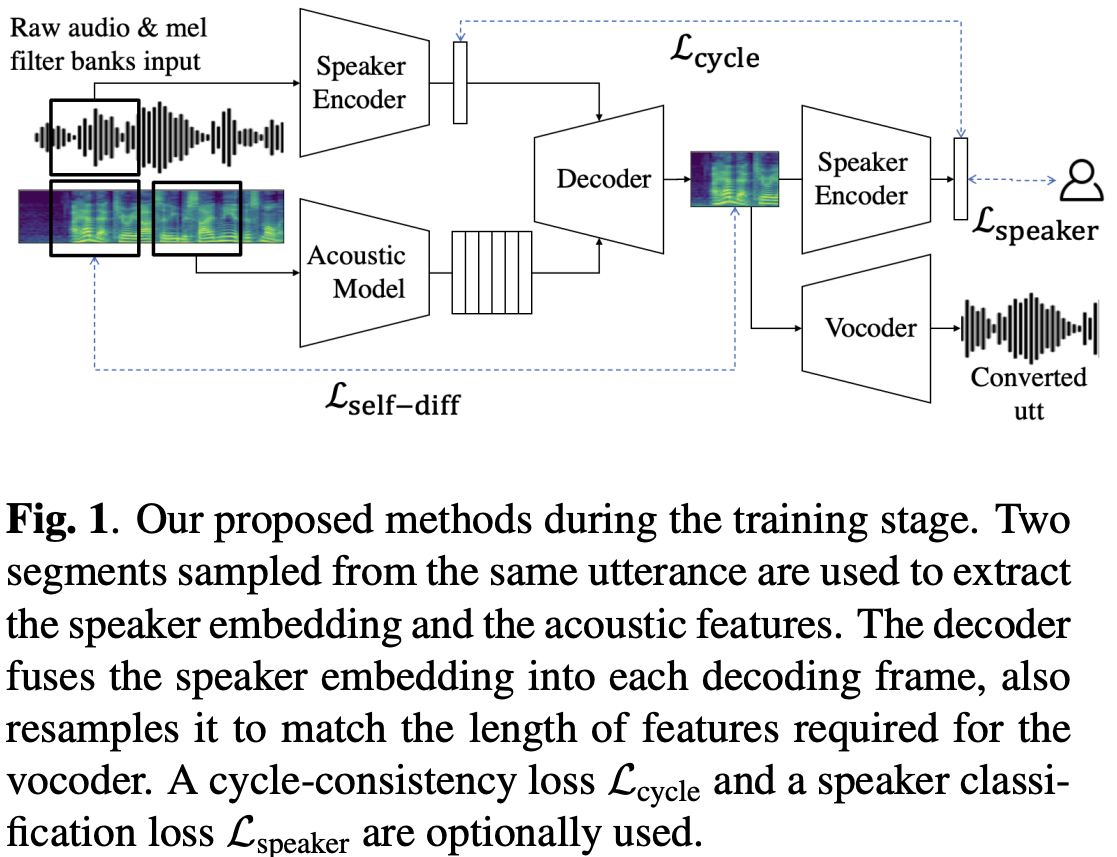
手法
をそれぞれソース・ターゲットの音声、
をそれぞれソース・ターゲットの音声特徴(MFCCとか)とする。
ソース音声のコンテンツ埋め込みは
をコンテンツencoderとして
(
は入力の時間方向の次元、
はコンテンツの埋め込み次元)。
ターゲット音声の話者埋め込みは
を話者encoderとして
(
は話者埋め込みの次元数)。
それぞれのencoderは入力は異なる(音声、音声特徴)ので注意。
decoderはコンテンツ埋め込みと話者埋め込みを入力として長さの
次元の音声特徴を出力する(ここではスペクトログラム)
なおパラレルデータは利用できないとする()。
なので再構成lossは自己再構成になり。
Length resampling decoder
ここはよくわからなかったのであまり参考にせず。
一般的なアーキテクチャだとdecoderはコンテンツ埋め込みから音声特徴を生成し、それをvocoderで音声にする。
このとき長さのミスマッチが起こる。
vocoderは高いサンプリングレートかつ小さいwindow sizeの入力が好ましいが、音声特徴はより大きいwindow size、むしろ生の音声の方が効率的。
そのためdecoderの入力長と出力長
が異なる。
これを修正するためにupsamplingとpoolingを行う。
例としてコンテンツencoderが16kHzの音声を受け取り1/320倍の特徴を出力する。
vocoderはwindow size 300で24kHzの音声を出力する。つまり。
なのでdecoderの入力を8倍し、stride 5のaverage poolingを行うことでコンテンツencoderの自己教師あり学習が出来る。
ちょっとよくわからなかった。と
はそもそも別の特徴なので長さが異なるのは当然では?読むときに何か見落としているかも?
Self-reconstructing from pairs of utterances
一般的なself-reconstructionはの設定で、
で学習するが、これだと話者埋め込みにコンテンツ情報が混ざり、話者とコンテンツが分離できない。
そこで同じ話者の別のセグメントを利用する。

Enforcing consistency and separability for speaker embeddings
話者埋め込みは同じ話者なら当然同じになってほしいのでcycle-consistencyを導入。
をdecoderに生成された音声特徴とする(
)。
cycle-consistency lossは以下。

2項目と3項目がおかしく感じるが気のせい?からは話者
の話者埋め込みが得られそうだが。
上記のlossだと話者埋め込みが他の話者の埋め込みと分離が悪くなる。そこで出力付近にヘッドを追加し、話者IDをを利用したクラス分類lossも追加。
が新しいヘッド、
はone-hotの正解の話者IDのラベル、
がcross entropy loss。

所感
よくあるZero-shot VCの形。言葉の統一感等が少々悪くわかりにくい論文だった(小並感)。
Length resampling decoderがちょっとよくわからなかった。
同じ話者の発話の違うセグメントを利用して話者埋め込みを作るのは以前試してなかなかうまく行かなかったが、自分の実装が悪かったのだろうか。
セグメントの切り出しに関してもどれくらいの長さを利用すれば良い埋め込みが得られるのかなどわかっておらず適当だったのも良くなかったかも。
暇があれば応用してみる予定。