[論文メモ] SELF-ATTENTION DOES NOT NEED O(n^2) MEMORY
self-attentionの計算にメモリは必要ない
self-attentionはクエリ、長さ
のキーとバリューをそれぞれ
、
として次の式で表せる(ただしクエリが1つのとき)。
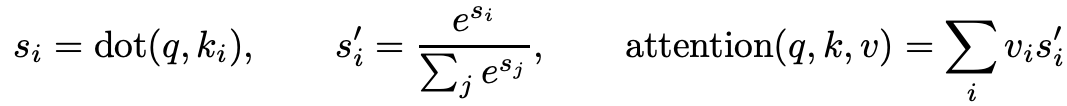
普通に実装するとの計算・保存ために
の計算量とメモリが必要。そしてself-attentionは
必要。
これを改善し、
attentionの計算について。
まずsoftmax(式のの部分)で
をattentionの最後に移動する。
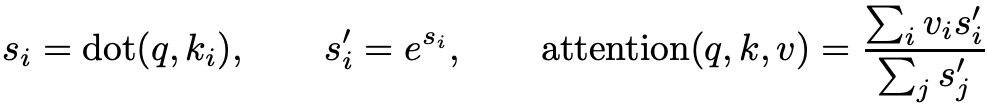
これは定数メモリで計算出来る。
attentionの除算部分のためにと
を用意する。
キーとバリューのペアを取り出したら、
を計算し
と
を蓄積していく(
、
)。
そして最後にで割ればよい。
これによりのメモリ消費。
これをself-attentionに拡張するにはクエリにインデックスを1つ追加するだけで、それでものメモリに抑えられる。
ただ、入出力は必要でこれは仕方なし。
所感
JAXの実装が乗っているけどJAXをあまり使わないので悲しい。
JAXを使う人は使ってみてもいいのかもしれない。