[論文メモ] DaViT: Dual Attention Vision Transformers
空間方向だけでなくチャンネル方向のself-attentionも導入することでglobal contextを扱えるようにした。
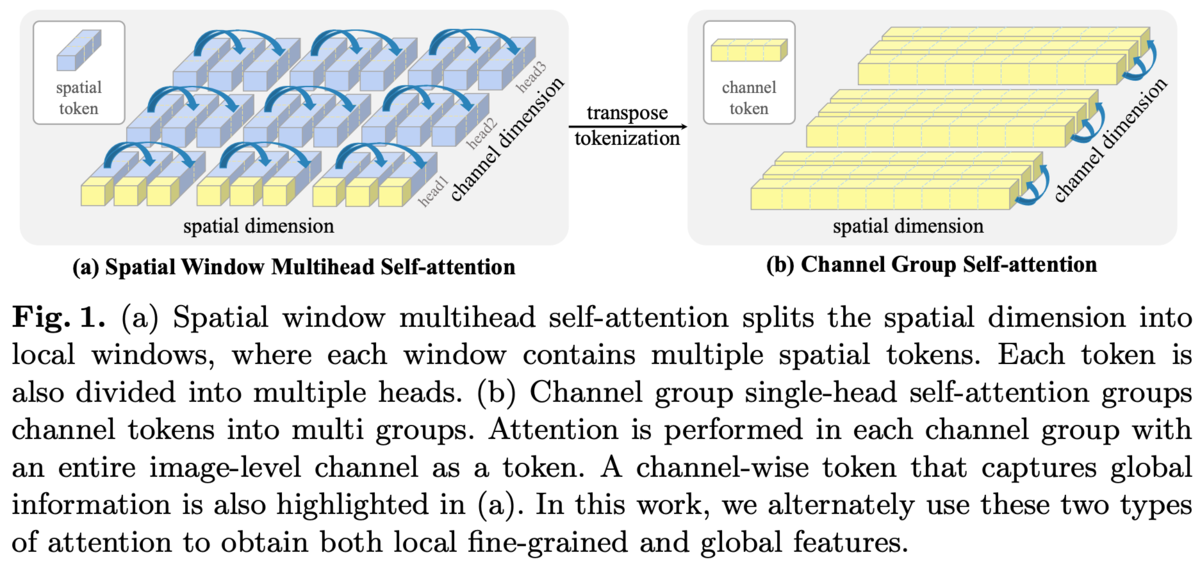
Vision Transformer(ViT)は画像をオーバーラップなしのパッチに切り出して、それをシーケンスとみなしてself-attention(SA)を行うが計算コストが高く解像度が高いと厳しい。
Swin Transformerなどで導入されたlocal attentionは切り出したパッチをグループにまとめそのグループ内でSAすることでコストを抑えたがグループ同士のインタラクションが必要になる。
これらのピクセルレベル・パッチレベルSAの手法とは違った、計算コストもそれほど多くなくglobal contextを扱える画像レベルSAを作れないか?というお気持ち。
手法
空間方向だけではなく、チャンネル方向のSAも導入したDual Attention Blockを提案
Dual Attention Blockの構造を図3(a)に示す。
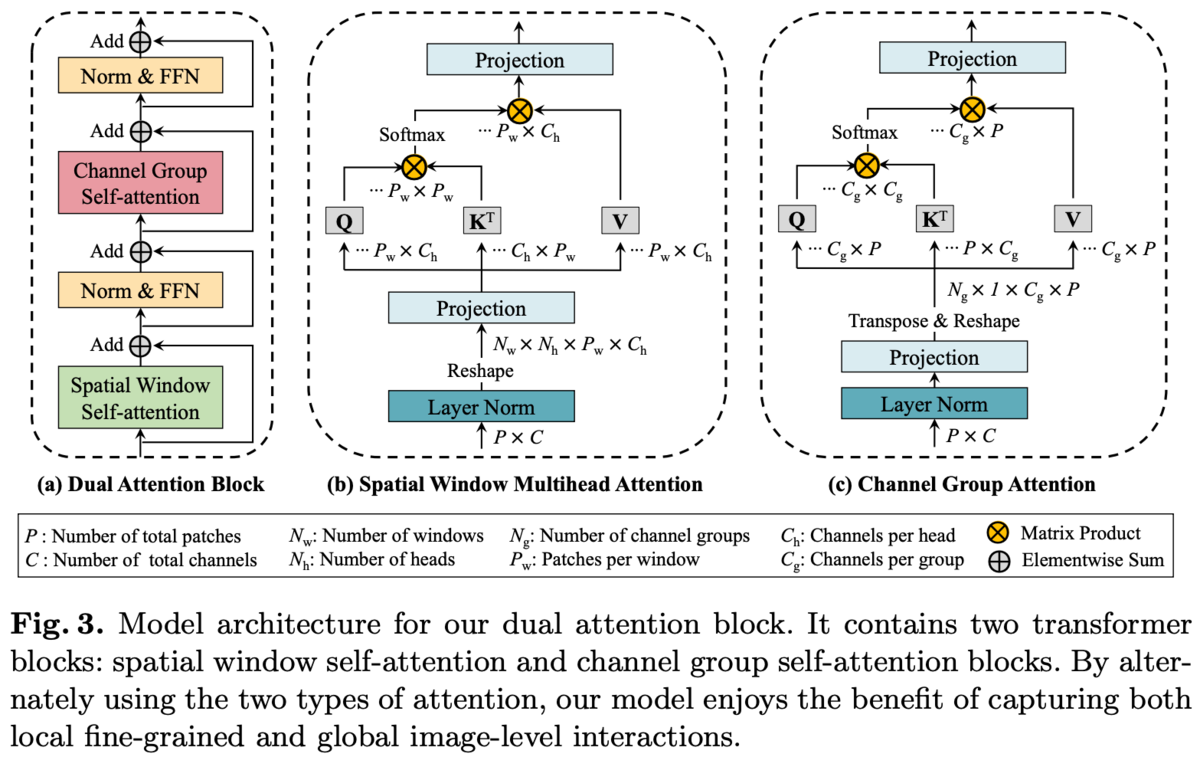
Spatial Window SAはSwin Transformerのものと同じ。
local window内でSAするのでグローバルな情報を扱えない。
そこでChannel Attention(CA)を導入する。
チャンネル数、画像の縦横を
としたとき、空間方向のSAは長さ
の
次元特徴ベクトルのシーケンスとみなしてSAを行うのに対して、チャンネル方向のSAは長さ
の
次元特徴ベクトルのシーケンスとみなしてSAを行う。
各パッチは画像の局所的な情報を持っているのに対して、各チャンネルはすべてのパッチを横断して画像全体における特徴を持っており、CAによりグローバルな情報を扱うことが出来る。
ただ、チャンネル次元が512とかになると計算コストが大きいのでチャンネルをGroup Normのようにグループ化し、そのグループ内でチャンネル方向にSAを行う(Channel Group Attention(CGA))。空間方向でのlocal windowと同じ。
local window SAと同じ制限、つまりグループ同士でのインタラクションが必要になるがそれは空間方向のSAが担ってくれる。
計算量については省略。詳しくは論文参照。
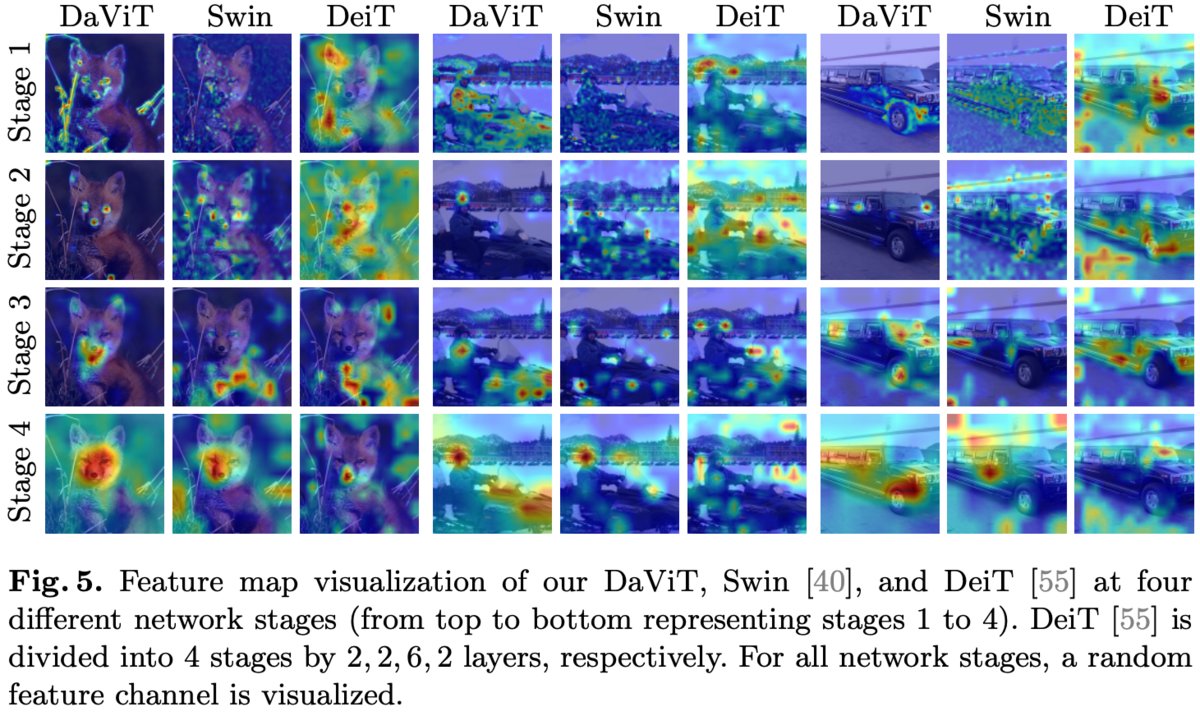
特徴マップの可視化比較。
このDual Attention Blockを使ったアーキテクチャをDual Attention Vision Transformers (DaViT)とする。
よくあるViTと同じアーキテクチャ構造でパッチ埋め込みのレイヤーの後に4つのブロックがスタックされる階層構造。
ViTでお決まりのサイズ毎の複数アーキテクチャ。
が層の数、
がチャンネル方向SAのグループ数、
が空間方向SAのヘッド数。
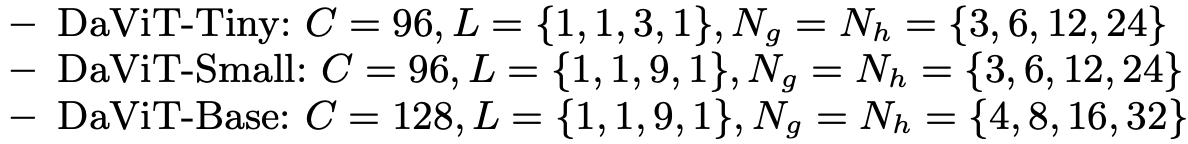
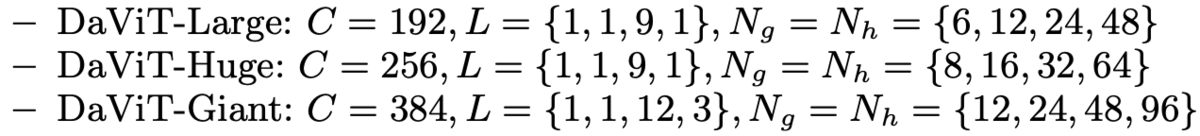

実験・結果
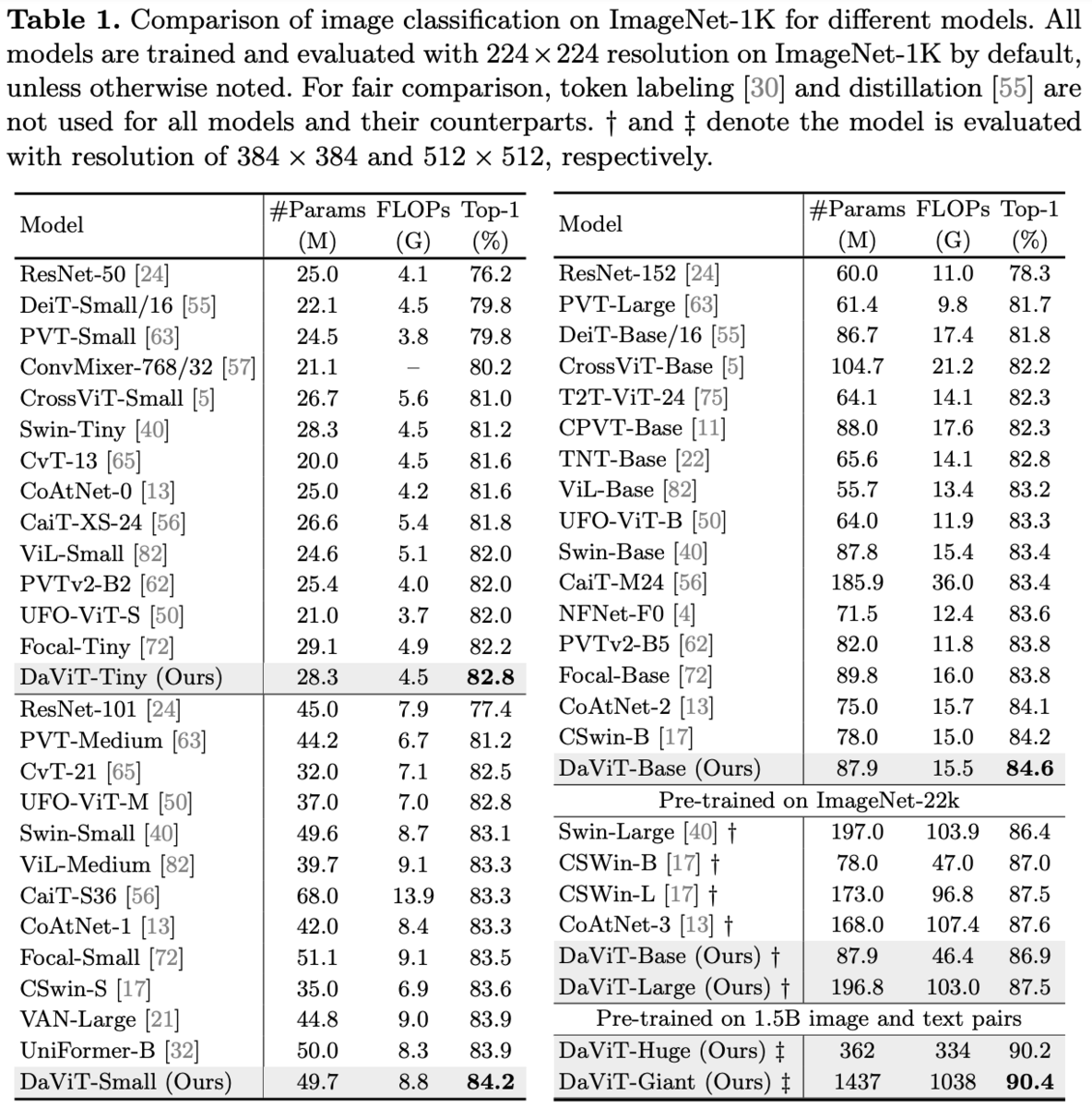
ImageNet-1Kのクラス分類、COCOの物体検出、ADE20kのセマンティックセグメンテーション。
バッチサイズ2048、AdamW、300エポック。
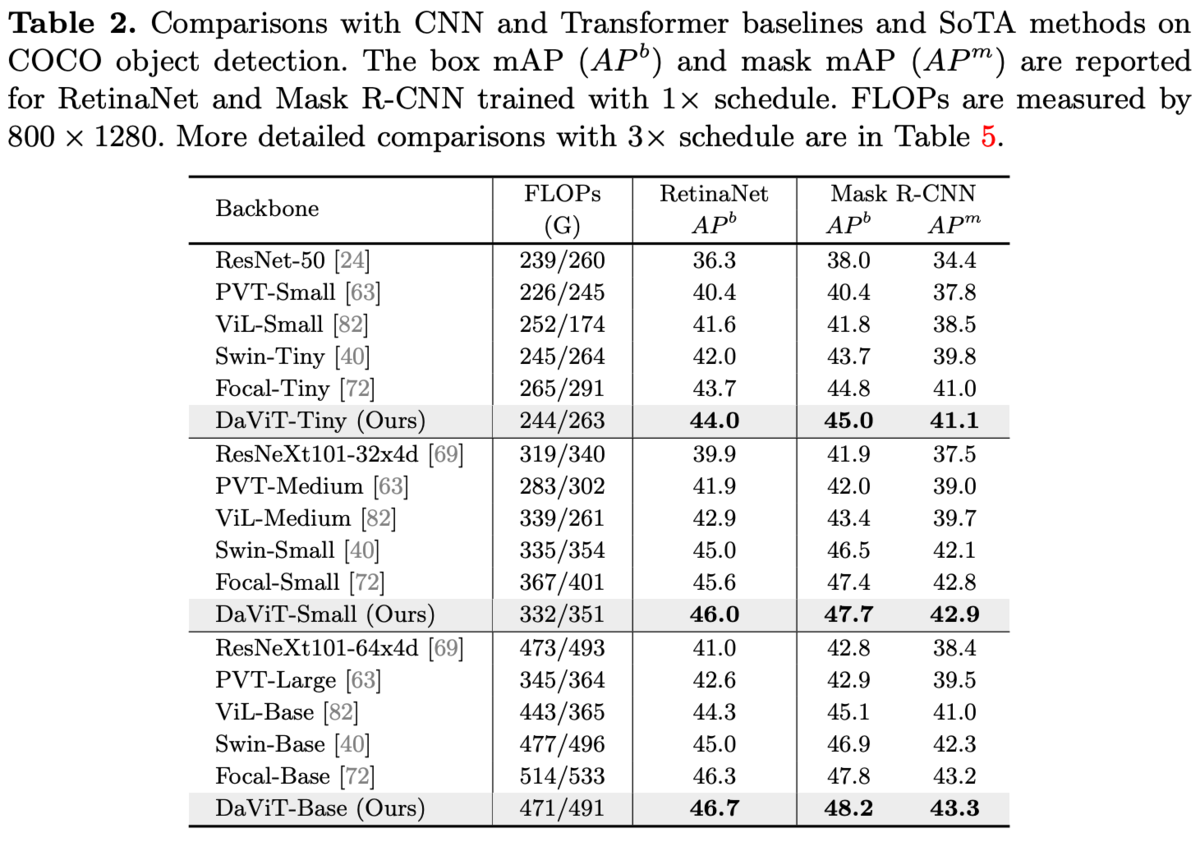
COCO。
ADE20k
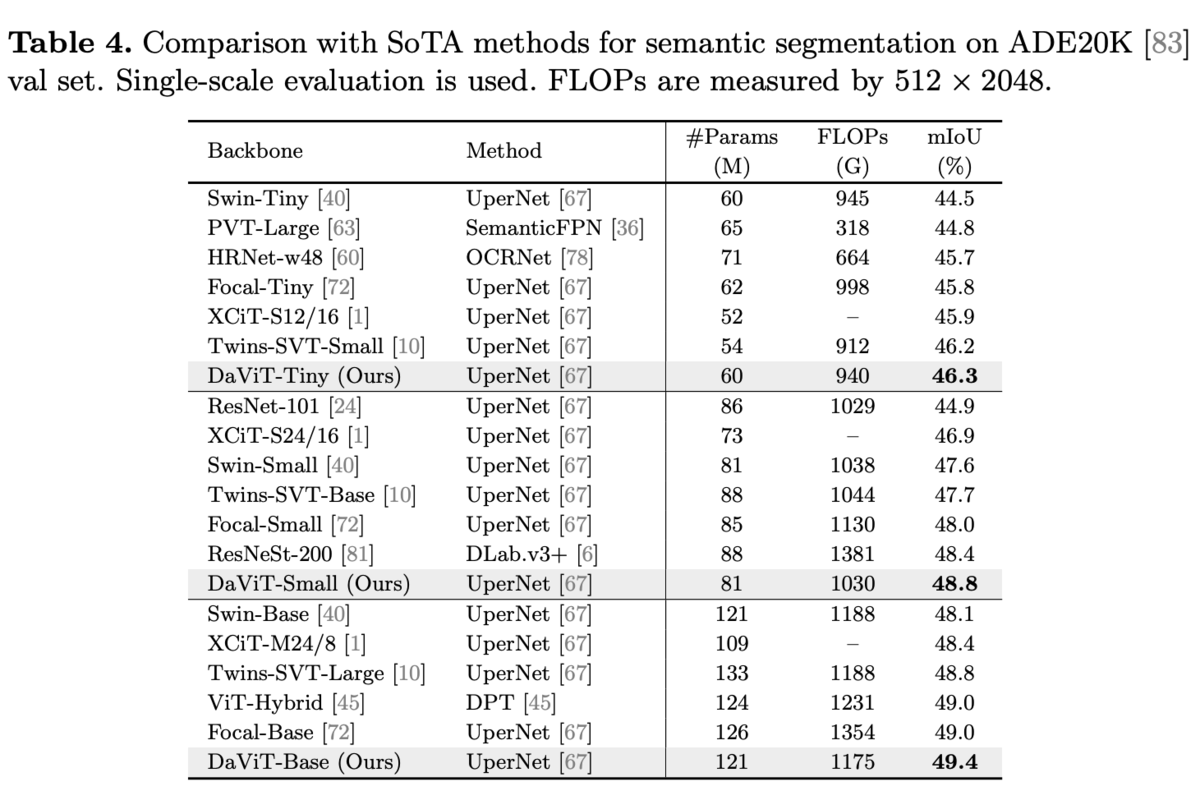
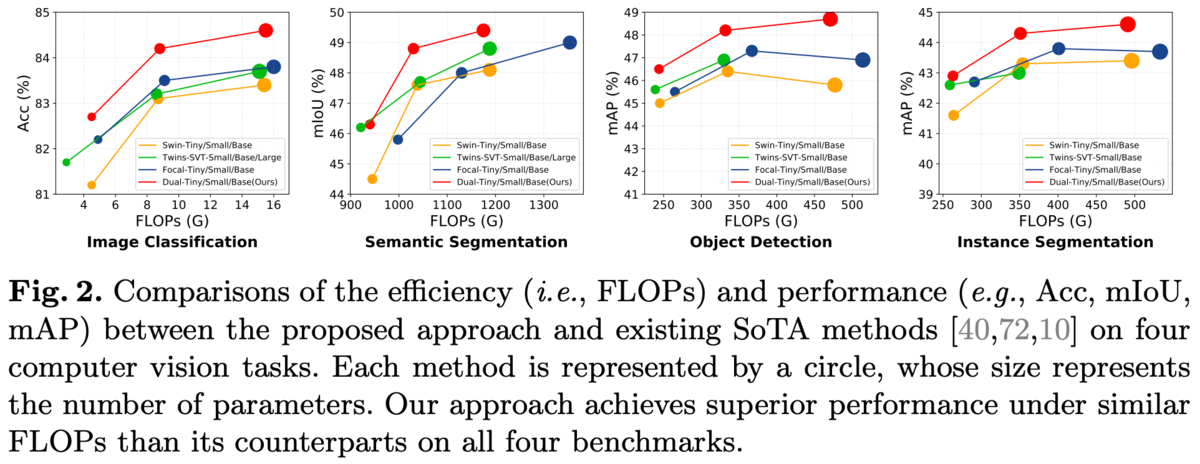
同じレベルのFLOPsで比較しても優位。
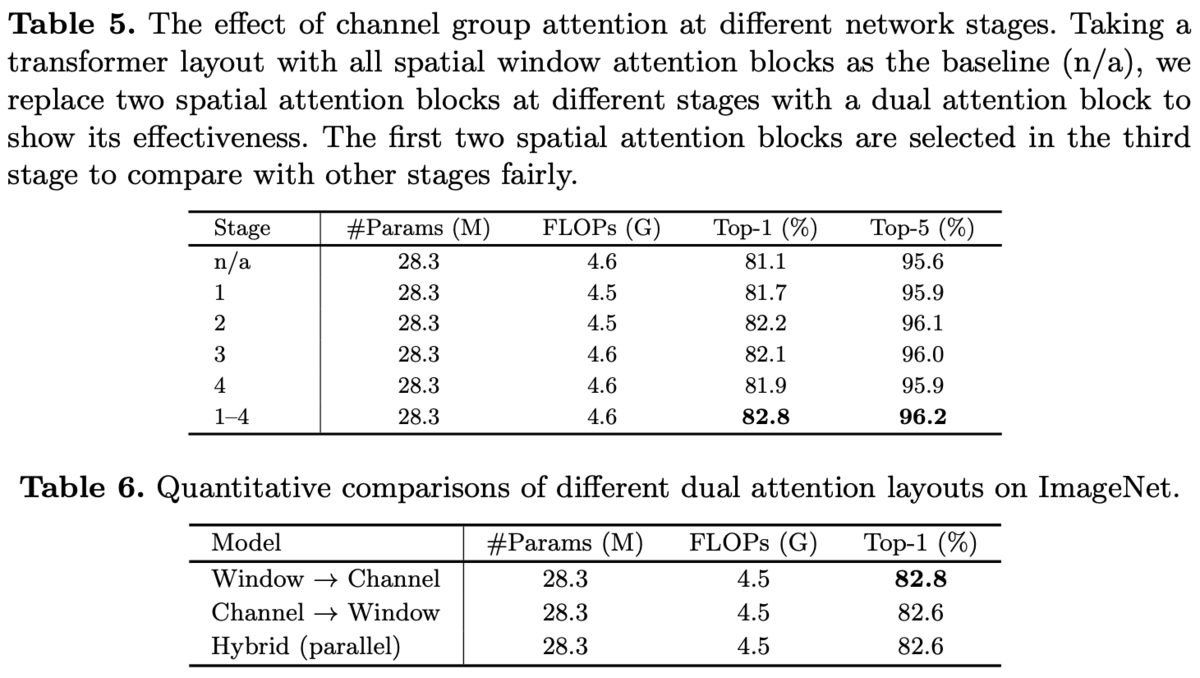
Ablations。
CGAをどのブロックで採用するか(表5)と各SAの順番比較(表6)。
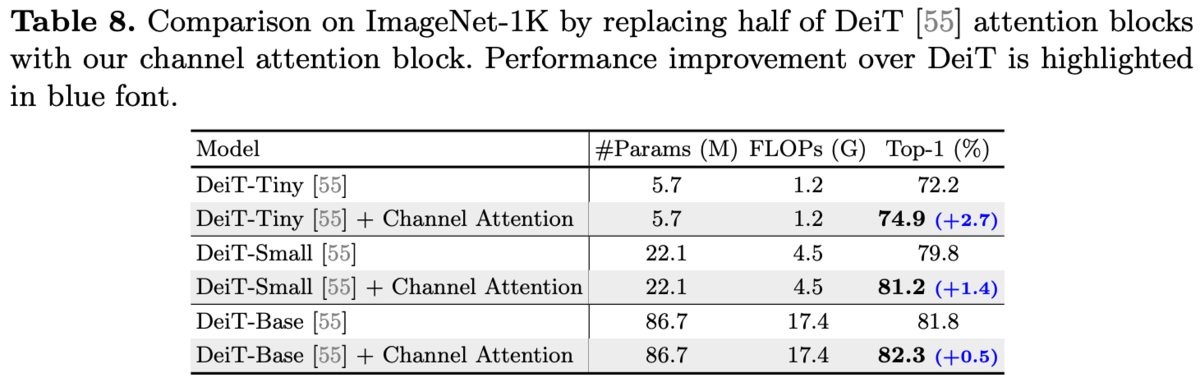
DeiTの各Blockの半分をChannel Attentionに置き換えた。
所感
チャンネル方向のattentionで、Group Normのようにチャンネルをグループにするというシンプルな解決策。
グループに分けると計算コストは減るがグループ同士のインタラクションが必要になる。
それを直交する方向(空間方向とチャンネル方向)でattentionすることで解決しているのは良い。
[論文メモ] PixelFolder: An Efficient Progressive Pixel Synthesis Network for Image Generation
Pixel Shufflerを使ったピクセルレベルの画像生成

既存手法にCIPSというのがあり、これはピクセル座標と潜在変数から画像を生成するというもの。ピクセルは独立で、空間方向でのconvolutionはなく、基本ピクセル独立のMLP(Network In Networkみたいな)。
しかし、メモリの消費も大きく計算量も多いのでそれをどうにかしたいというお気持ち。
手法
Pixel Shufflerを導入して解像度を下げる。ここではpixel foldingという名前をつけているが統一してほしい。ここでは一応pixel foldingという名前を使う。
pixel foldingの仕組みは図3(a)を参照。

pixel foldingはあるテンソルを
にreshapeし解像度を下げる(図3(a)の上)。
逆操作のpixel unfoldingはテンソルを
にreshapeし解像度を上げる(図3(a)の下)。
reshapeするだけなので計算コストも少なく情報も落ちない。
このpixel foldingを使ったアーキテクチャをPixelFolderとする。
アーキテクチャの全体像は図2(b)を参照。ちなみに図2(a)が既存手法のCIPSのアーキテクチャ。

アーキテクチャは各解像度で各ピクセルの初期値となる入力があり、入力と同じサイズの画像を生成する。最終的にそれらをターゲットの解像度にアップサンプリングし足し合わせることで画像を生成する。
途中pixel foldingで解像度を落としpixel unfoldingで元に戻すボトルネックな構造。
ピクセルに対してのMLPを適用して画像を生成するので解像度を下げるとコストを下げられる。ただすでにピクセル独立ではないと思う。
各解像度では初期値特徴を多分conv1x1あたりでチャンネル数を1/4にし、pixel folding -> ModConv -> pixel unfolding -> ModConv -> ToRGBというプロセスをたどる。自身より解像度の低いステージがある場合はその中間特徴も受け取る。
初期値特徴は各座標のフーリエ特徴と座標ごとの学習可能なパラメータ。
ModConvはStyleGAN2で採用されたModulated Convでこれは3x3のカーネルサイズ。






[論文メモ] MixFormer: Mixing Features across Windows and Dimensions
CVPR2022 Oral
window baseのattentionとdepth-wise convで双方向インタラクションすることで計算量を抑えつつlocal globalの情報を扱えるようにした。

Vision Transformer(ViT)の一つの成功例としてSwin Transformerがある。
Swin Transformerはオーバーラップ無しのwindowを切り出し、その中でattentionを行うというwindow baseなattention(local window self-attention)を採用している。
local window self-attentionは受容野を絞ることで計算量を抑えまた画像タスクの帰納バイアスとなる。しかし受容野を絞ったことで元のself-attentionより能力が制限されている。
これを改善するためにdepth-wise convと組み合わせる方法も提案されている(HRFormerとか)。これはlocal window self-attentionとdepth-wise convを続けて行うことでlocal globalを組み合わせているが、これだと情報がうまく混ざらず、またのlocal window self-attentionとdepth-wise convそれぞれの弱点を無視しているため特徴表現があまり良くない。
これらをどうにかしたいというお気持ち。
手法
local window self-attentionとdepth-wise convを並列し、かつ双方向インタラクションを行うMixing Blockを提案する(図1)。
並列化はそのままの通りでlocal window self-attentionとdepth-wise convを並列で行い、それらの出力をconcat後 feed-forward network(FFN)に通す。
local window self-attentionのサイズは7x7、depth-wise convのカーネルサイズは3x3。これらは実験的に決定。
次に双方向インタラクションについて(図1の水色の矢印)。
local window self-attentionはチャンネル方向の重みを共有して空間方向の位置で動的に重みを決定するためチャンネル方向のモデリング能力が低い。
逆にdepth-wise convはチャンネルに注目して空間方向の重みを共有している。
そこでこれらを双方向にインタラクション(bi-directional interactions)することでお互いの弱点を補う。

depth-wise convの出力はchannel interactionモジュールを通してlocal window self-attention(図だとW-Attention)に伝えられる。
local window self-attentionの出力はSpartial Interactionモジュールを通してdepth-wise convの出力に混ぜられる。
channel interactionモジュールは Squeeze-and-excitation NetのSEレイヤー。global average pooling(GAP)レイヤーで1x1の解像度に落として最後にsigmoidに通してチャンネル方向のattention的なものにする。そしてそれをself-attentionのvalue部分に掛ける。
spatial interactionモジュールはconv1x1を組み合わせてチャンネル方向を1にし、最後にsigmoidを通して空間方向のattention的なものにする。そしてdepth-wise convの出力に掛ける。
これがMixing Blockでこれを使ったViTをMixFormerとする(図3)。

例のごとく複数のサイズを用意(表2)。

実験・結果
224x224入力のImageNet-1Kのクラス分類。AdamWで300epochの学習。結果が表3。

これの前に読んだMaxViTとモデルサイズ等で良さげなペアがなく比較は難しかった。MixFormerのほうがFLOPsが小さそう。
Object DetectionやSemantic Segmentationのbackboneとしたときの比較。


Ablations。
並列化とインタラクションの影響。並列化の効果が高そう?

depth-wise convのカーネルサイズの違い。

アーキテクチャデザイン。

他のアーキテクチャにMixing Blockを適用。

所感
最近では「Swin Transformerのlocal window self-attentionは局所的な特徴しか扱えないのでなんとかしたい」から「local window self-attentionとグローバル情報をどうやって組み合わせるか」という問題設定に変化している。
前回読んだMaxViTはchannel shufflerの逆操作で、今回のMixFormerでは並列したdepth-wise convとの双方向インタラクション。
MixFormerのほうが1ブロックに付きself-attentionが1回少ない分計算量が少なそう。その代わり精度がわずかに劣っている印象。
正直self-attention使わなくても、pixel shufflerの逆操作とconvで十分な気がする。attention使わないからViTにはなれないけど。
[論文メモ] MaxViT: Multi-Axis Vision Transformer
Google Research
入力画像サイズにスケーラブルなVision Transformer(ViT)の提案
ViTはモデルの能力が高く過学習しやすい。それを抑えるため大量の学習データを必要とした。
Swin Transformerはwindow-baseにしてうまく制御したが、window-baseにしたことで大域へのattentionが失われた。
global attentionとlocal attentionの相互作用のためには高解像度(階層ネットワークの場合は入力に近い層)でglobal attentionを行う必要があるがattentionはの計算コストがかかる。どうにか軽量なglobal attentionをしたいというお気持ち。
手法
localとglobalのインタラクションを可能にするmulti-axis self-attention(Max-SA)をつかったMaxViTを提案。
MaxViTのアーキテクチャの全体像は図2参照。

はじめにConvしたあと(Stem)は基本Max-SAブロックを積むだけ。
Max-SAブロックはMBConv、BlockAttention、GridAttentionの3つのモジュールからなる。
MBConvはMobileNetv2で提案されたInverted Residual Block。Conv1x1でDepthwiseConv3x3とSqueeze-and-Excitationモジュールを挟んだもの。
MBConvを前に入れたのは、入れたほうが汎化性能が高くなり学習もしやすくなったから(実験による観測)。
またDepthwiseConvにはconditional position encoding (CPE)とみなすことができるので明示的なPEは入れてない。
メインはBlockAttention、GridAttention。
BlockAttentionがlocalなattentionでGridAttentionがglobalなattentionを担う。
まずBlockAttentionについて
画像を普通のViTなら
のシーケンスとしてattentionを行うが、BlockAttentionでは
にreshapeして
の次元、つまり
のwindowに分割してそのwindow内でattentionを行う。これはSwin Transformerと同じ。
window内でのattentionになるのでlocal。
globalなattentionを担うGridAttentionについて。
画像を
にreshapeして
の次元でattentionを行う。
これ故にMulti axis。
BlockAttentionとGridAttentionを図にしたのが図3。

Swin Transformerのattention部分の片方をGridAttentionで置き換えても計算量やパラメータは一切変わらないがglobalとのインタラクションが可能になる。
GridAttentionの実装も全然大変ではない。
例のごとくサイズ違いのモデルを複数用意(表1)

実験・結果
データセットはImageNet-1K(1.28M)、ImageNet-21K (12.7M)、JFT (300M)。細かい設定は論文参照。

パラメータや計算量でのスケールも良い。

ImageNet-21Kの結果。

MaxViTをバックボーンに使ったCOCO2017のObject Detectionの結果。

Ablations。結構色々試してる。GridAttentionの恩恵よりMBConvの恩恵のが大きく見える。

各階層でのブロック数のレイアウトをSwin Transformerに合わせて比較。MaxViTのレイアウトのが良い。

所感
attentionの次元を変えるのはたしかに良さそう。DilatedConvでよくない?と言われればそのとおりだが。
ぶっちゃけPixel Shufflerの逆操作。
気持ち的にglobal attentionに興味があったが、実験の結果的にはMBConvの結果が興味深かった。
[論文メモ] Fine-tuning Image Transformers using Learnable Memory
Vision Transformer(ViT)の入力トークンに学習可能なメモリトークンを追加することで新規タスクにスケーラブルなfine tuning方法を提案。

ViTは大量のデータで学習することで高い精度を得られる。そしてそれをfine tuningすることで画像分類等のタスクに応用する。
しかしViTは大量のパラメータがあり、タスク毎にすべてのパラメータを保存するのは高コスト。またfine tuning時の学習率に対しての敏感さもある。
そしてタスク毎にモデルを作ると保存のコストや実行時のコスト(タスク分forwardする)が必要。
これらを解決したい。
手法
既存の学習済みViTにメモリとなるトークンを追加する。
ここではクラス分類について考える。
ViTの入力は画像を個のパッチ(トークン)化してPositional Encoding(PE)を追加したものと最終的なクラス分類に使われるクラストークン。
なので合計のトークン列が入力となる。

ははじめの画像パッチの変換(MLPとか)、
がPE、
がクラストークン。
ここにfine tuning用のメモリトークンをconcatする(
はトークンの次元数)。
ViTはのトークンを入力として受け取ることになる。
そしてこのメモリトークンは次のブロックに伝わらない。
つまりブロックの出力を
とすると
は
個のトークンに切り捨てられ、次のブロックに入力する際は再度メモリトークンをconcatする。

切り捨てないもの等も実験したがこれが良かったらしい。
ランダムに初期化したメモリとクラストークン、そしてクラス分類のヘッド部分のみをfine tuningすると良いパフォーマンスを得られるが、ヘッド等が変化するため元タスクの予測はできなくなる。
元タスクを予測する必要がないなら問題ないが、元タスクと新タスクの両方が必要なことも多い。両方保存するのは単純だが新タスクが増えていくと破綻する。また計算コストも新タスク分だけ増える。
すべてのタスクを1つのモデルで学習する方法もあるがこれは常に可能なわけではない。
そこでメモリトークン、クラストークン、ヘッド部分のみ付け替えAttention Maskで対応する。適切なAttention maskを利用すればトークンへの注意を制御出来る。
元の入力トークンとクラストークンに対するattentionを同じく入力トークンとクラストークンに依存するようにする。
そして新たなタスクのためのクラストークンが追加された場合、そのクラストークンは入力トークンとクラストークンに加え自身のクラストークンとメモリトークンに依存するようにする。言い換えると他のタスクに依存しないようにする。
表1がそのマスク。

このようなマスクを設計することで同時に複数のタスクをfowardすることが出来る。
入力に各タスクのメモリトークンをconcatしforwardする。マスクにより入力トークンや元のクラストークンはメモリトークンの影響を受けず、各タスクのクラストークンも互いに独立しているので問題ない。最後に各クラストークンを各々のタスクのヘッドにつなげれば各タスクの出力を得られる。

実験・結果
基本アーキテクチャはViT-B/32でImagenet-21Kで学習されたViTの論文元が公開している事前学習モデルを利用。
学習率のスケジューリングはコサインでその他の設定はViTの論文参照。
最適化手法としてMomentum SGD + Gradient Clipping、5step warmupあり。
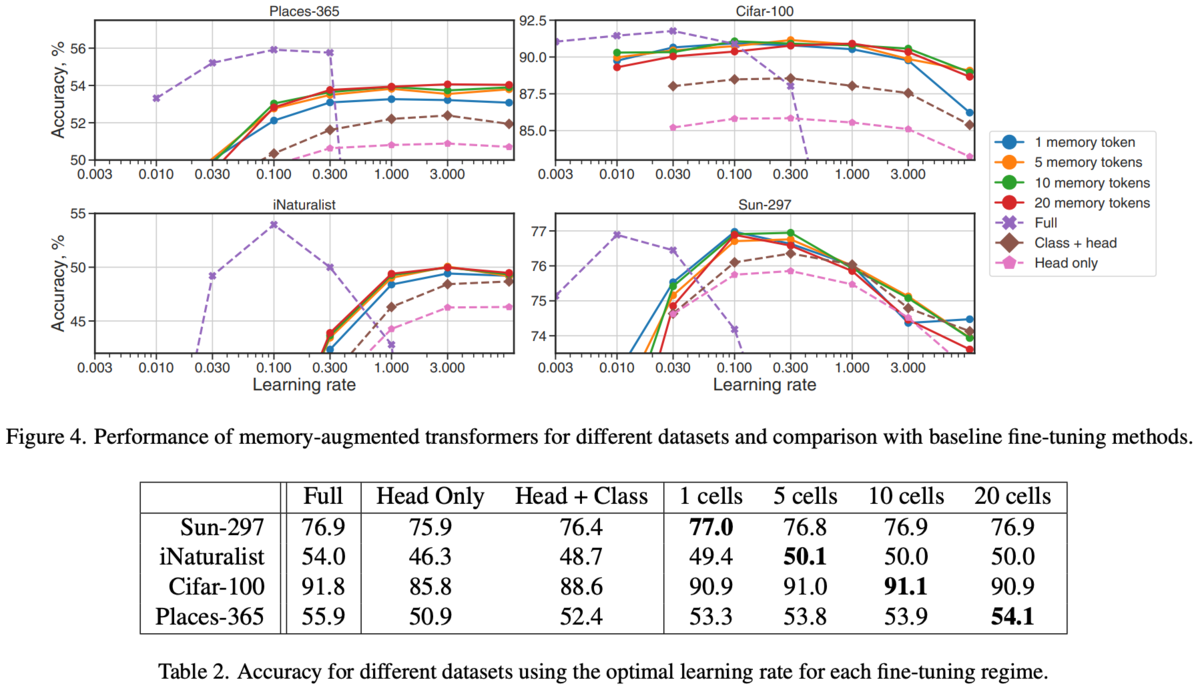
各データセットについて試した結果が以下の図4と表2。
Fullはモデル全体のfine tuningで一番良いが一番コストが高い(モデルをすべて別々に保存する必要がある)。
ヘッドやクラストークンの学習に比べ提案手法のが良い(メモリトークンの分の多少のオーバーヘッドはあるが)。
新規タスクのために増加したパラメータと計算コスト。もとのViTのパラメータが80MでFullは当然丸々1ViT分増える。

Ablations。
メモリトークンの扱いについて。
メモリトークンはブロックに入力する際に追加され、出力時に切り捨てているが他についても調査。
追加・切り捨ては図2の左から2番目。
ブロック毎に追加していく(切り捨てしない)パターン(図2左から3番目)とはじめのメモリトークンを伝播していく(図2右はし)を実験。
結果が図6。Full memory(追加・切り捨て)がよい。


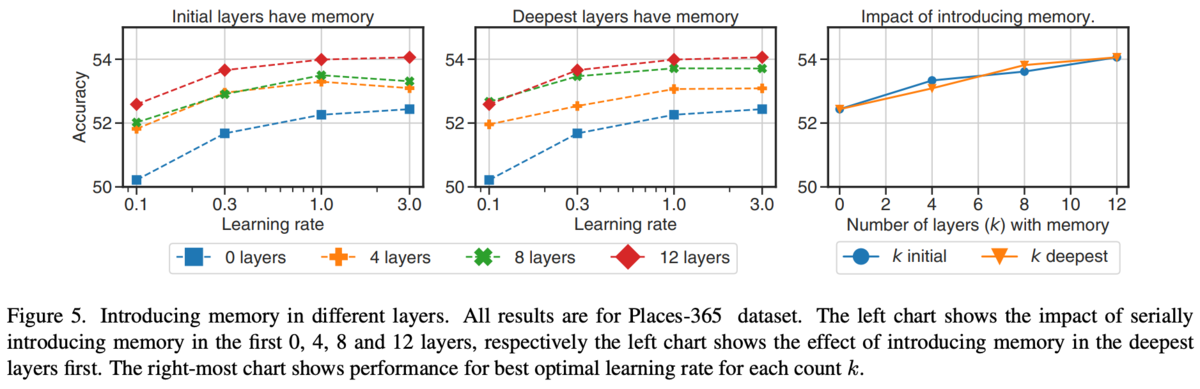
どのブロックでメモリトークンを追加するといいのか。
[論文メモ] DISENTANGLING CONTENT AND FINE-GRAINED PROSODY INFORMATION VIA HYBRID ASR BOTTLENECK FEATURES FOR VOICE CONVERSION
ICASSP 2022
Cross Entropy(CE) lossとConnectionist Temporal Classification(CTC) lossそれぞれで学習した音声認識モデルの特徴量を使ったany-to-oneのVoice Conversion(VC)モデルの提案。
CElossで学習した音声認識モデルの特徴量を使うと音色が劣化し、CTClossで学習した音声認識モデルの特徴量を使うと自然性が劣化する。
そこで2つの特徴を利用したハイブリッドなモデルを構築する。
手法
全体図は以下の図2参照。5つのモジュールからなる。

音声認識はconformerベースのものを利用。transformerとCNNを合わせたモデルで最近のSOTAらしい。
同じアーキテクチャの2つモデルをCE lossとCTC lossそれぞれで学習し、中間から抽出した256次元の特徴を利用する。
図2の左、CE-BNFsとCTC-BNFsがそれ。BNFはBottleneck featureの略。
VCモデルとしては2つのエンコーダと1つのデコーダからなる。
2つのエンコーダはコンテンツ用と韻律用でコンテンツエンコーダはCTC-BNFsを、韻律エンコーダはCE-BNFsを受け取り特徴量に埋め込まれる。
そして得られた2つの埋め込み特徴はconcatされデコーダに入力される。図のはconcatらしい(紛らわしい)。
韻律エンコーダはConv1dとGroupNormを含むBLSTMを使った構造。
韻律埋め込みはInstance Normしたり、コンテンツ埋め込みに比べ次元を非常に小さくしたりして情報を制限する。

が韻律埋め込みで
がInstance Norm、
が韻律エンコーダ、
がCE-BNFs。
この韻律埋め込みはProsody Predictor、Adversarial Content Predictor、デコーダの3つに使われる。
Prosody Predictor は韻律埋め込みからエネルギー
、ピッチ
を予測し、正解のエネルギー
とピッチ
とのL1 lossをとる。
は韻律関係の最終的なloss。
はハイパラ。

Adversarial Content Predictorはコンテンツ埋め込みと韻律埋め込みの情報がかぶらないようにするためのもの。
図2の通りContent Predictorの前にgradient reversal layer(GRL)をおく。
GRLはバックプロパゲーション時に勾配を反転させる層。
Content Predictorは韻律埋め込みからコンテンツ埋め込みを予測するように学習をする(L1 loss)。
通常なら韻律埋め込みがContent Predictorがコンテンツ埋め込みを予測しやすくなる方向への勾配を韻律エンコーダに流すはずだが、GRLで勾配が反転するのでContent Predictorがコンテンツ埋め込みを予測できなくなるような方向へ韻律エンコーダは学習する。
これにより韻律埋め込みとコンテンツ埋め込みの情報のオーバーラップを減らせる。

一番の目的であるVCのlossは再構成loss。デコーダで生成したメルスペクトログラムと正解のメルスペクトログラム
とのL1 loss。

最終的なlossは以下。




[論文メモ] CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Adobe Research
間違いがあるかもしれないので注意。
大きな欠損のある画像の補完が出来る、cascaded modulation GAN (CM-GAN)の提案。
大きな欠損を補完出来る既存手法としてLaMaやCoModGANがあるが、それでもまだ厳しい。
それはマスクされた補完箇所からの画像の空間的距離依存やグローバルなセマンティクスを扱えないからでそれを解決したい。
なお下記画像はgithubから引用(論文中の画像は当時、貼り忘れられていた)。
多分図2。

手法
欠損箇所をglobal contextによって作った特徴マップで埋めることカスケード構造を提案
アーキテクチャ
アーキテクチャの全体像は図2を参照。
エンコーダと2つのデコーダからなる。
エンコーダは欠損画像と欠損のマスクを受け取り、マルチスケールの特徴マップを出力する。
はスケールの数で
が最も小さい解像度の特徴マップ。
全体構造をキャプチャするためのglobal style code を
を
正則化付きの線形変換によって取得する。
これを潜在変数 をMapping Networkによって変換して得られた
とconcatしてglobal code
]を作る。global codeはデコーダに利用される。
Global-Spatial Cascaded Modulation
decode時にglobal contextをうまく扱うためにglobal-spatial Cascaded Modulation (CM)を提案。
図2の右側の2つのモジュール、Global Modulation Block (GB)とSpatial Modulation Block (SB) がそれにあたる。
GB、SBともに各ブロックは、
を入力として受け取り
、
を出力する(
と
が次の
と
になる)。詳しく書かれていないが多分
は
を2Dに変換したものがはじめで、2ブロック以降は前ブロックの出力を受け取る。
も同じく
を2Dにしたものとエンコーダの同じ解像度の特徴(
)をconcatしたものを受け取ると思われる。このあたりは抜け落ちている図に書いてあるのかも。
エンコーダの出力は欠損箇所の特徴がノイジーなのでglobal contextと合わせて単純にデコードしても欠損箇所にアーティファクトが出る(図7参照)。

そこで欠損箇所の影響をあまり受けない特徴も同時にデコードするカスケードなモデルにする。
2D化したとglobal code
からデコードするGBのデコーダを用意し、その中間特徴をSBのデコーダに注入する。
SBの各ブロックでは入力をglobal code でmodulationした後、GBの中間特徴
を加工したもので特徴を更新する。
加工はAffine Parameters Network(APN)を通す。擬似コードが以下(間違ってるけどなんとなくわかる)。詳しくは論文参照。

これによりグローバルな特徴を常に意識しつつ、空間的な特徴もきれいに捉えることが出来る。
Expanding the Receptive Field at Early Stages
エンコーダについて。
単純なFCNだと浅い層の有効な受容野(effective receptive field)の成長が遅い(らしい)。これは既存研究のLaMaでも言及されている。
そのため、欠損部分についておかしな特徴ができてデコーダが苦しむ。
既存手法としてfast Fourier convolution (FFC)があり、FFCを使うと浅い層でも画像全体をカバーできる大きな受容野となる。
既存手法ではFFCをボトルネック部分でスタックしていて計算量が多く、ボトルネックは浅めなためglobal contextをうまく処理できず欠損を処理しきれない。
そこで本手法ではエンコーダ自体をFFCで構成することで浅い層の段階で欠損部分を処理して、欠損部分に変な特徴が出ることを防ぐ。
Object-aware Training
実際にアプリケーションとして使う場合、既存手法のようなランダムマスクではなく画像中の不要なオブジェクトを塗りつぶしたようなマスクになる(図4)。

そこでPanopticFCNを用いてセグメンテーションを学習し、それをマスクに利用する。
FCNによるオブジェクトレベルのセグメンテーションからのサンプリングとランダムな欠損を生成しオーバーラップを計算。しきい値異常のオーバーラップがあった場合はオブジェクトをマスクする(人間が入力する場合のobject removalに相当するマスク)。
それ以下の場合はランダムな欠損を利用する(人間が入力する場合の補完に相当するマスク)。
Training Objective and Masked-R1 Regularization
adversarial lossだけでも良いパフォーマンスだがperceptual lossを追加すると更に改善した。
またマスク以外の領域でgradient penaltyを計算しないことで学習が安定化。

はマスク。
実験・結果
512x512のPlaces2データセット。
詳細は論文参照。

CM-GANは既存手法と比べぼやけておらず細かく生成している印象を受ける。GBとSBの恩恵か。


Ablation。各モジュールの有用性。

所感
メモを書いた当時、論文も投稿されて間もないため論文が正直不十分だった(図の貼り忘れ、図にある特徴が不明 or 間違っている、擬似コードも間違っているなど)。なんか急いでいた感がある。
グローバルな特徴でのみデコードするモデルと空間的な特徴も扱うモデルでのカスケード構造は良さそう。
以前CoModGANを試したとき、たしかに大きな欠損にアーティファクトが出ていた。それを補うためにマスクの影響をあまり受けないグローバルな特徴のみから生成した特徴マップを欠損箇所の補完に利用することでなんとなくグローバルに正しいものが生成できそう。
欠損箇所の特徴がアーティファクトの原因になりそうなのもよく分かる(3x3とかのConvoolutionならなおさら)。