[論文メモ] ECAPA-TDNN for Multi-speaker Text-to-speech Synthesis
より強い話者エンコーダを用いることで、複数話者のText-to-speech(TTS)の精度を向上させた。

既存のTTSでは話者エンコーダとしてd-vectorやx-vectorといった話者分類タスクを事前に学習したモデルの中間特徴を用いるが、これらだと自然性や話者性があまりよくない(特にデータセットに無い話者)。
その理由は既存の話者エンコーダのキャパシティが低いこと。だからもっと強くすればいいよねというお気持ち。
手法
話者エンコーダとしてECAPA-TDNNを用いる。これはTDNNでVoxcelebデータセットのSOTA的モデル。
ECAPA-TDNNの特徴は
- Squeeze-and-Excitation (SE) blockの利用
- Res2Netのskip connection
- 複数階層の特徴を集約
Res2Netはこちら
arxiv.org
acoustic modelはFastSpeech2を利用。
vocoder modelはHifiGANを利用
学習についてはまずECAPA-TDNNの発話レベルの話者分類の学習を行う。
TTSの学習時はこの発話レベルの話者特徴をacoustic modelの形に合うように線形変換し、足し合わせる。
実験・結果
データセットはVCTKとLibriTTS。
サンプリングレートは22050Hzにし、80次元のメルスペクトログラムを利用した。
比較対象はx-vector。
x-vectorとECAPA-TDNNはVoxceleb1とVoxceleb2で事前学習。
結果は以下。

各話者エンコーダで抽出した10人の200の発話特徴量をt-SNEで可視化。
両エンコーダともに分離はできている。ただECAPA-TDNNのが連続的な分布で、これは同じ話者でも各発話の僅かな違いが反映されているとのこと。
既存研究で話者埋め込みは連続的な分布の方がより良いパフォーマンスが出るという報告もある。
なにより、話者分類とTTSは目的が違うのを忘れてはいけない。

所感
よくあるTTSの論文で話者エンコーダのアーキテクチャを変更したもの。
確かに、話者エンコーダの目的が話者分類ではなく音声にしたときに話者性を高めるものであることを忘れてはいけない。
[論文メモ] InsetGAN for Full-Body Image Generation
arxiv.org
afruehstueck.github.io
CVPR2022
Adobe Research
GANで全身生成を可能にした。

一つのGANで全身レベルの多様性のあるドメインを学習するのは難しい。全身生成と顔生成の学習済みGANを使ってそれぞれを生成しシームレスに結合する。
手法
Full-Body GAN
大雑把に全身を生成するのが目的。数万の全身サンプルを使ってStyleGAN2を学習。解像度は1024x1024。
全身は服装や各パーツ(手や足)の位置等がバラバラで精密に生成するのが難しくどうしてもアーティファクトが出てしまう(図1(a))。
それでも、肌の色の一貫性や、アクセサリもそれっぽく全身が生成出来るレベルは学習できた(図3)。よく見るとおかしいだろうがそれは後々改善する。

Multi-GAN Optimization
顔生成モデルが生成した結果をFull-Body GANによって生成された全身画像に貼り付ける形できれいな全身画像を生成していく。

このときの一番の問題は条件なしで生成した顔画像を貼り付けたときに一貫性があるようにしなければならないこと。
Full-Body GANをとし、生成した全身画像を
とする。
顔画像を生成するGeneratorをとし、生成した顔画像を
とする。
この顔画像を全身画像に貼り付けるためにBounding Box(BBox)を検出する必要がある。
全身画像から検出したBBoxでクロップしたピクセルをとする。
これを貼り付けるわけだが、これはクロップしたところにを貼り付けたときに連続的になるような
のペアを見つけることに相当する。
最終的な出力を得るためにの領域を
で直接置き換え以下の最適化を行う。

、
は境界の滑らかさと
と
が似ているかを測る指標。
Optimization Objectives
と
の片方、または両方を最適化する必要がありそのときに満たしてほしい点が3つ。
(1) 顔画像と全身画像の顔は粗く似ていてる必要がある(肌の色とか)
(2) コピーアンドペーストするので境界は継ぎ目ができないように
(3) 見た目がリアルであること
(1)についてはダウンサンプリングした結果に対して lossとperceptual loss(
)をとる。これにより粗く似ているようにできる。

、
で
は64x64へのダウンサンプリング。
(2)については(1)と同様の lossとperceptual loss
を境界部分についてとる。

は領域
との境界部分の周り
ピクセルの領域。
(3)については下記式の正則化で担保する。

第一項目はlatent codeが学習に使ったlatent codeの平均からあまり離れないようにするもの。
第二項目も同じようなもので、StyleGAN2のを使った既存のImage manipulationでは一つのを使うのではなく、各ブロックに注入する
を分けて
として
個の
を最適化するが、それに倣ってここでも
次元の
に分割する。
をベース、各ブロックへ注入するときのオフセット
とする。なのでブロック
に注入するときは
になる。
Face Refinement versus Face Swap
Full-Body GANの生成した画像の顔部分をより精細化するために生成した全身画像に対して、顔専用のGANで生成した顔画像を違和感なく貼り付ける。
このとき、元の全身画像の顔を保ちつつ、かつ境界部分が違和感ないようにしたい。
以下の式を最適化することでほぼ満足出来る結果が得られるがそれでも境界部分が不連続になることがある。

そこで対象領域以外の状態を保ったままを最適化する。

は元の生成画像、
は対象領域以外。つまり顔以外の部分は元の画像をなるべく保ちつつ多少の変更を許容する感じ。
最終的な目的関数は以下。

図1(b)と図5が結果。Full-Body GANの生成した顔より自然に見える。

Body Generation for an Existing Face
今までは全身生成してからの精細化だったが、顔画像からの全身生成もやりたい。
BBoxからはみ出るような複雑な髪型の場合など、境界部分の調整のためわずかな顔画像の変化も許容する。
なるべく顔を保存するために以下のface reconstruction lossを追加。

は
目的関数は以下。

先程は全身を保存しつつ顔を最適化だったが、今度は逆に顔を保存しつつ全身を最適化という感じ。
結果が図6で、顔のアイデンティティは保ちつつ3つの体を生成した。

Face Body Montage
既存のGAN Inversion手法でリアル画像を潜在空間に埋め込むことができ、これを使うことで顔、全身それぞれをの潜在空間埋め込み操作出来る。
ただ、全身は多様なのできれいに再現するのは難しい。そこで先程の目的関数2つをあわせたような以下の目的関数を利用する。

図7が顔と全身を組み合わせた結果。肌の色を揃えるようなlossは無いが、顔と体で同じ色になるように変化している。

また、と
の両方を最適化したことで図1(d)のように髪の毛の境界部分が切れにつながるように肩の部分に髪が生成されている。
のみの最適化した場合と
と
の両方を最適化した場合の比較を図2右に示す。
Optimization Details
僅かだがより
のほうが良い結果だった。
ダウンサンプリングしたや
に対してlossをとることで柔軟かつアーティファクトに適合するリスクを減らした。
また、と
の最適化は
に依存した境界部分
を利用している。
これに対処するためにと
を交互に最適化し
の最適化毎に
を再計算する。
データセット・実装
1,024x1,024の全身画像を83,972枚で、これらは他から購入した100,718枚の画像から作成した。
しかも手作業で付けたセグメンテーションマスク付き。すごい...。

そして既存のポーズ検出で外れ値的なポーズの画像を取り除いた。
FFHQの学習等でもわかるようにアライメントは重要なのでポーズアライメントも調整。
Generatorの生成能力を背景に割きたくないのでreflection paddingして27x27のガウシアンフィルターで背景をぼかす。
セグメンテーションマスクがあるので背景を削除しても良かったのだがそうしなかったのは
1) セグメンテーションが完全ではない(特に背景との境界部分)
2) 現在のGANは一様な色の広い領域生成が得意ではなかった(実験的に)
なおDeepFashionデータセットでも実験した。こちらはクリーニング後10,145枚で1024x768、背景は始めから一様に塗りつぶされている。
学習はStyleGAN2-ADAアーキテクチャでaugmentationはすべて採用。
自作データセットは4 Titan V GPUで28日と18時間。バッチサイズは4。
DeepFashionは4 V100 GPUで9日でバッチサイズは8。
実験結果は今までの図を参照。
CoModGANとの比較。


[論文メモ] UVCGAN: UNET VISION TRANSFORMER CYCLE-CONSISTENT GAN FOR UNPAIRED IMAGE-TO-IMAGE TRANSLATION
Vision Transformer(ViT)を使ったunpaired image-to-image translation。
unpaired image-to-image translationでは既存手法としてCycleGAN、ACL-GAN、Council-GANなどがある(U-GAT-ITも)。
CycleGANはone-to-oneだが、ACL-GANとConucil-GANはone-to-manyで多様性に重きをおいている。
現代のニューラルネットアーキテクチャにCycle consistency lossを使ってone-to-one translationを改善できるのでは?というお気持ち
手法
提案するUNet ViT Cycle-consistent GAN(UVCGAN)のアーキテクチャ、学習フローは以下の図1。

2つの画像ドメインを相互に変換するGeneratorをそれぞれ
とする。
そして、どちらのドメイン由来かを識別するDiscriminatorをとする。
アーキテクチャはUNetをベースとし、ボトルネック部分にピクセルレベルのViTを導入。pre-process部分はconv + leakyReLU、post-process部分は1x1 conv + sigmoid。
ViT部分ではピクセルレベルのパッチ化をしてpositional encodingをconcatしてる。足さなかった理由があるのだろうか。
事前学習とloss
Bidirectional Encoder Representations from Transformers (BERT)-like self-supervised pre-trainingを行った。
BERT likeな事前学習はランダムに初期化された大規模ネットワークの事前学習に効果的で、マスクされた画像から元画像を予測するタスクを行う(ピクセルレベルの loss)。
事前学習に本タスクの学習を行うが最終的なlossは以下。

はadversarial loss、
はidentity loss、
はcycle-consistency loss。Discriminator用lossの右辺第二項目はGradient penalty(GP)。
はそれぞれハイパラ。
実験・結果
データセットはselfie⇔anime、male⇔femail、メガネの有無。
BERT likeな事前学習では256x256の画像を32x32ピクセルのパッチにして40%をマスクする。


Ablation studies。
BERT likeな事前学習で用いるデータセットについて
のどちらがいいかを調べるとともに、identity lossとGPの有無についても調べた。データセットはmale-to-femaleとselfie-to-animeの2つ。
Noneは事前学習なし。

- identity lossとGPは組み合わせると改善
- GPなしidentity lossありはなんとも
- 事前学習はGPとidentity lossと組み合わせると向上につながる
事前学習+identity lossはそうでも無いが、+GPは大きな改善もたらす。
これはGeneratorは事前学習したパラメータに対してDiscriminatorは初期値のままなので、意味不明な情報をGeneratorに流して事前学習済みパラメータを破壊するからではと予測。
もしそうならDiscriminatorも事前学習すればもっと改善するかも...とのこと。
所感
久々のunpaired I2I translation。U-GAT-IT以降あまり追ってなかった。
この間のdenoisingでもそうだったがUNetのボトルネックにAttentionモジュールを組み込むアーキテクチャが流行っている?パフォーマンスが良い?
ninhydrin.hatenablog.com
機会があればUNet+ViTをいろんなタスクに試して見たいところ。
[論文メモ] Screentone-Preserved Manga Retargeting
スクリーントーンの見た目を保存したまま画像をリサイズする。

bilinearやbicubicでリサンプリングするとスクリーントーン部分にブラーやアーティファクトが起きる(特に縮小)。
スクリーントーンは漫画の見た目に大きく影響する。
全体の構造を保ったままリサイズしつつ、スクリーントーンの解像度や細かさは元のまま保存したい。
手法
サイズのターゲット画像
をスクリーントーンの解像度を保ったまま、サイズ
の画像
にしたい。
既存手法のScreentoneVAEを使ってスクリーントーン部分を検出する。
ScreentoneVAEは漫画画像と潜在空間との双方向マップで、潜在空間からスクリーントーンの復元ができる。ただし、元のスクリーントーンから少し変化してしまうことがあるらしい(特に大きいパターンのスクリーントーン)。
なのであくまでScreentoneVAEスクリーントーン部分の検出のみに使い、元画像のスクリーントーンを流用する手法をとる。
提案手法の全体の流れは図6の通り。

元画像から既存手法を使って線画構造のマップとスクリーントーン画像
を抽出しスクリーントーン画像はさらにScreentoneVAEマップ
に変換される。
と
をそれぞれターゲットの画像サイズにリサイズし
と
を得る。
これらをEncoder-Decoder型のscreentone reconstruction network に入力して目的の画像を得るがボトルネックの部分に領域毎のスクリーントーン特徴
を注入する。
は特徴抽出のためのネットワーク
に
と
を入力して得られる(
)。
とボトルネック部分は解像度が異なるので後述する階層化したアンカーを用いて解像度をあわせる。
Hierarchical anchor-based proposal sampling
screentone reconstruction network のエンコーダ部分を
としてボトルネック部分の特徴を
とする。
の解像度とスクリーントーン特徴
の解像度は異なるので合わせる必要があるが、単純にリサンプリングとかするとスクリーントーンのパターン情報等が壊れる。
そこでのグリッドのアンカー
を用意する。
そして各アンカーを中心としてクロップする。クロップ関数をとして
。
図8に2x2グリッドの例を示す。
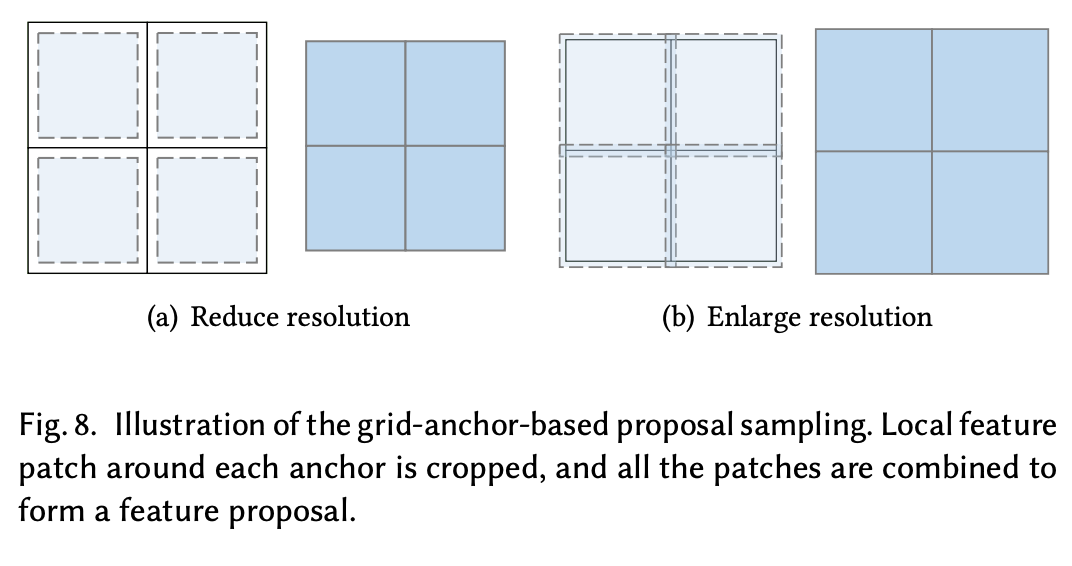
グリッドが1x1の場合アンカーは1つでクロップサイズはターゲットの解像度と同じ。グリッドが2x2の場合、アンカー1つあたりのクロップサイズは1x1のときの半分といった感じ。
必ずしも縮小ではなく拡大のときもあり、そのときは逆にアンカー毎にパディングをして拡張する。
リサンプリングと違って不整合が起きており、1x1のアンカーによるクロップでは端の方は明らかにもとの特徴と一致しない。だからといってたくさんのアンカーを使ってクロップしたものでは局所的な断裂が大量に発生している。
複数のグリッドサイズでクロップした特徴マップを利用することでそのあたりの不整合を解消するガイドを作る。
このクロップした特徴マップを候補特徴と呼ぶことにする。
Recurrent selection of hierarchical proposals
同じ解像度のボトルネック部分の特徴とスクリーントーン特徴
をクロップした
個の候補特徴集合
が手に入ったのでこれらをconcatしてデコードして終わり、というわけにはいかない。
デコーダネットワークはconcatした候補特徴集合の内どれを採用すればいいかわからず元のスクリーントーンと異なるものになる(図9(b)参照)。

そこで各特徴マップを再帰的に選択するRecurrent Proposal Selection Module (RPSM)を採用する。
RPSMモジュールのアルゴリズムは以下。
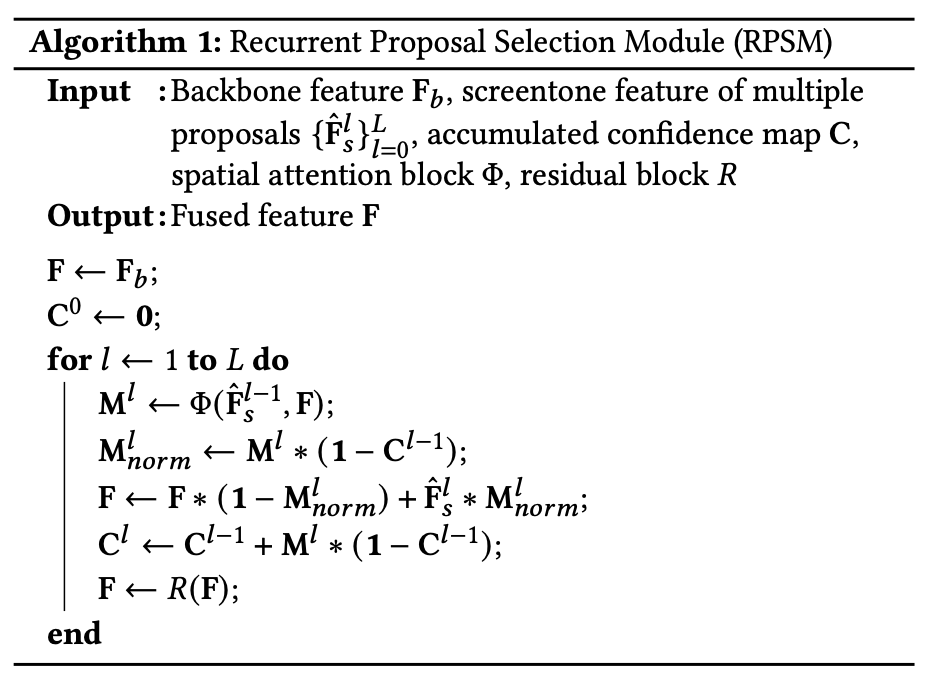
画像の各領域は候補特徴の集合からなるべく1つを採用するように強制する。
が確信度マップの累積。
アルゴリズムを上から見ていくと
forで候補特徴を一つずつに注目していく。
現在のベースとなる特徴マップ(最初はエンコーダ後のボトルネック特徴)と注目している候補特徴からマスク
を作る。
から累積確信度マップを引いたもの、つまりまだ候補を採用していない領域に絞り込む(
)。
絞り込んだマスクを使って候補マップをブレンドしベースの特徴マップを更新する()。
確信度マップを更新(累積)()
ResBlockでfoward()
という感じ。
Loss function
lossは
- translationinvariant screentone loss
- ScreenVAE map loss
- attention loss
- adversarial loss
Translation-invariant screentone loss
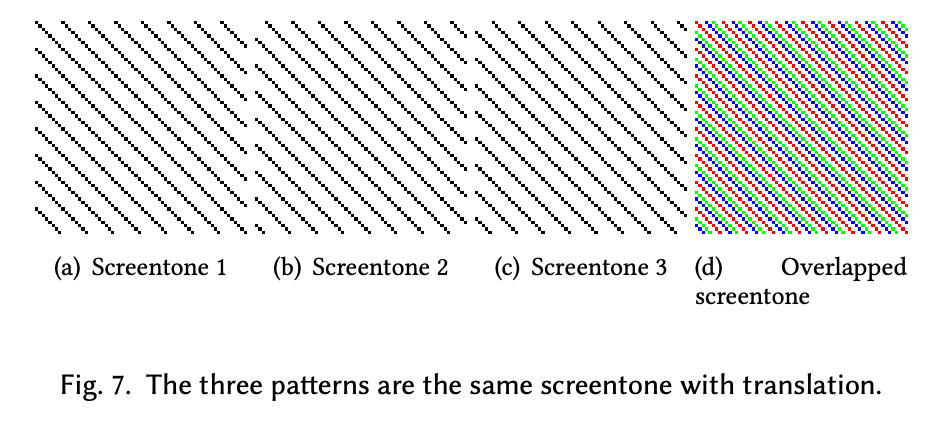
スクリーントーンのズレは人間にとって影響せず、正解は一つではない。図7の(a)が正解だとしても(a)(b)(c)のどれでもさほど問題ではない。
生成した画像をとしてTranslation-invariant screentone lossは以下の式(1)。
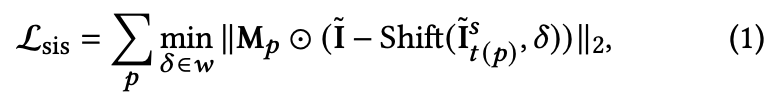
は領域、
は領域
の正解のスクリーントーンの種類、
は正解のスクリーントーン画像、
は(たぶん)領域
のマスク、
はオフセット、
は11 x 11のウィンドウでオフセットの探索範囲、Shift
は
だけシフトする演算子。
図7で示した通りスクリーントーンのパターンのズレはさほど問題ないので、正解のスクリーントーンのパターンで最も誤差の少ない移動を見つけて誤差を取る。
ただ、で繰り返しが見つけられないようなスクリーントーンに対応できない。
そこで生成画像と正解のスクリーントーン画像を半分のサイズにしてを探索し、それによって移動したものを新たな正解のスクリーントーン画像にする。
ScreenVAE map loss
Translation-invariant screentone lossは視覚的に似ていても空間的に一貫性のないパターンを持つスクリーントーンを生成することがある。
そこでもとの画像と同じスクリーントーンで埋めるようにScreenVAE map lossを追加。
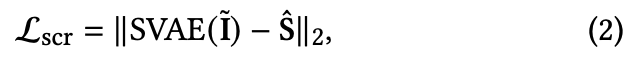
は正解のScreenVAE map。
Attention loss
複数の候補特徴があるが同じ領域でも各候補特徴同士に一貫性はないため、1つの領域は複数の候補特徴の中から1つを選ぶようにさせる。

[tesx: |\cdot|]は絶対値で、0.5引いた絶対値から更に0.5引いたものをlossとしてるので、lossが最小になるのはマスクの各値が1か0のときになる。
ただ、正解がわかっている場合はそのラベルを直接正解に用いる。


Adversarial loss
実際の漫画の分布に近づけるため。
適当に漫画っぽい画像を生成しても困るので、線画構造のマップとScreentoneVAEマップをConditionとする。

最終的なlossは以下。

各係数は。かなり職人的だ。
実験・結果
まずはデータセット。手作業で100枚の線画と125枚のスクリーントーンを用意し既存手法でスクリーントーンを貼って6000枚の漫画画像を用意した。
これらはと
用で、これとは別に20,000枚の漫画画像も用意した。
既存手法との比較


各lossの影響


小さい領域や、不規則なパターンに弱い

所感
確かに、スクリーントーンをリサイズすると雰囲気が変わり、作者の意図したものが変わってしまう。元のスクリーントーンの解像度を維持するのは大事。面白いタスク。
複数の候補があったときに、単純にconcatするのではなく、選択的に1つを採用するという仕組みは面白い。
ただReccurrentにやる必要があるのか少々疑問。バイナリなAttention Mapさえ生成できれば再帰的にやる必要はなさそうな気もする。
スクリーントーンの種類がある程度有限なら、わざわざ本家から持ってこなくてもスクリーントーンのサンプルから引っ張ってきても良さそうだが、多分そうでは無いのだろう。似たようなスクリーントーンでは作者の意図は反映できないだろうし。それに不規則なスクリーントーンはどこを切り出すかの問題がありそう。
スクリーントーン同士の視覚的効果が似ている判定とかはできないのかな?
[論文メモ] LEARNING TO MERGE TOKENS IN VISION TRANSFORMERS
Google Research
Vision Transformer(ViT)の内部でパッチを結合するPatch Margerを提案。
Transformerはアーキテクチャの大きさに(ある程度)比例してパフォーマンスが向上するがその分計算コストがかかる。
パッチを減らせれば計算コストを抑えられる。
手法
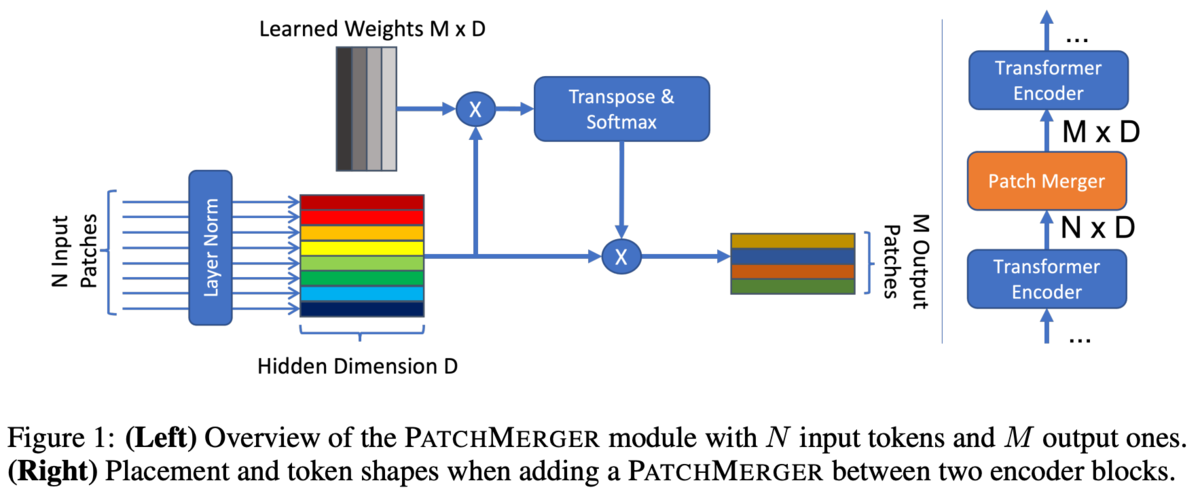
PatchMagerでは個のパッチを出力する。
あるパッチが入力されると、PatchMargerはそのパッチに対する
個のスコアを出力する(
)。これは線形変換で行われる。
スコアの合計が1になるようにSoftmax()で正規化する(
)。
このスコアは出力の個のパッチへのパッチ
の寄与度。
各パッチについて寄与度を計算し、寄与度で重み付けすることで新しいパッチとする。
考察
PatchMagerはパッチに対する線形変換でスコアを算出するため似たパッチは同じ寄与度になり、同じ背景から生まれた冗長なパッチはマージされパッチが減る(後の計算コストが減る)。
新しいパッチは古いパッチの線形結合で、もとの位置情報とは無関係。
入力パッチは可変長だが、学習時とあまりにもかけ離れたパッチ数だとスケールが壊れる恐れがある。そのために、PatchMargerの前にLayer Normを挟むことでその影響を軽減している。
PatchMagerはクエリ部分を学習可能パラメータにしスケーリングをなくしたAttentionと似ている。


なのでTransformer Blockの一部を置き換えようと思ったが不安定だったのでPatchMargerモジュールにした。
実験・結果
基本のアーキテクチャは偶数のTransformer Blockを持っているので、基本的にPatchMargerはその中間に設置し、出力するパッチは8。
Small、Base、Large、Hugeの4つの異なる設定で実験。
各設定のepoch数、パッチサイズ、トークン数は
Small : 5epoch、(32, 32)、49トークン
Base: 7epoch、(32, 32)、49トークン
Large: 14epoch、(16, 16)、196トークン
Huge: 14epoch、(14, 14)、256トークン
なお、CLSトークンは別。



12BlocksのモデルでPatchMargerの設置する位置の変化。基本後ろの方が良いが計算コストの問題がある。
10~11の間で落ちるのが面白い


所感
この間読んだのによく似ている。
ninhydrin.hatenablog.com
流行りなのか似たようなのが出たので急いで出したのかは不明。
あちらはAttentionを使い出力がある程度可変なのに対して、こちらは単純な重み付けで出力は固定長。どちらも一長一短な気がして、どちらが良いのかはわからない。
どのパッチがどれくらいの寄与度なのかの可視化とか見てみたい。あちらは出していた。
またこちらは寄与度からパッチ同士の類似度も計算できるはずなのでそれも見てみたかった。
[論文メモ] BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
CVPR2022
サンプル間の関係をネットワーク内部で学習するフレームワークを提案。
サンプル間の関係を調査するフレームワークは色々あるが、基本的に入力や出力時点で行う。
ミニバッチの中でのインタラクションはテスト時等を考えると適用は難しい(Batch Normもドメインシフトの問題とか)。
学習時はサンプル間のインタラクションを使い、テスト時にはインタラクション不要なモジュールが好ましい。
手法
ネットワーク内部で自発的にミニバッチ内のサンプル間関係を学習させる。

backboneネットワークは個々のサンプルの特徴を学習する。このときはサンプル間のインタラクションはない。
この特徴に対してサンプル間の関係を学習するために、バッチ方向についてAttentionを行うBatch Transformer(BatchFormer)モジュールを導入する
BatchFormerは式(1), (2)で表されるPost Norm LNのTransformer Blockからなる。

バッチ方向でAttentionするためCross-Attentionと見れなくもない。
BatchFormerの出力をClassifierに入力しクラス予測を行う。
しかし、BatchFormerはバッチ内の統計情報を使うのでテスト時には適さない。そこでテスト時はBatchFormerモジュールを取り除く。
しかし、BatchFormerモジュールを取り除くと予測ができなくなるので、Classifierをbackboneの出力を入力としても学習する。
図2にはClassifierが2つあるが、2つはパラメータ等を共有した同じネットワークで、テスト時は入力画像 -> backbone -> Classifierという流れで予測を行う。
このようにBatchFormerモジュールは取り外し可能なモジュールで、学習もEnd2Endで行える。
図3はBatchFormerの有無での勾配の伝播を図示したもの。

普通の学習だと個のサンプル
が与えられたとき、それぞれのloss
についての勾配(図の実線)が流れるが、BatchFormerでは
も流れる。
実験・結果
Long-Tailed RecognitionやZero-shotについて実験。
詳細等は省略。







所感
バッチ方向でのAttentionとテスト時の実行方法の提案。
BatchFormer自体は特徴量を入力として特徴量を出力する追加モジュールなので、既存のResNetでもViTでも追加できるのはよい。とりあえず試してみるか的な使い方ができそう。コードとしての分離もやりやすそう。
ただ、ミニバッチサイズの大きさがある程度確保できないと効果は薄そう。
また、ミニバッチ内のサンプル間でのAttentionがどういった影響があるのか少々懐疑的。
StyleGAN2のDiscriminatorで採用していたminibatch standard deviation layerと同じように、Discriminatorに使うとmode collapseを抑えられるかも?(そもそも学習ができなくなりそうだが)
[論文メモ] OUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
一枚の画像から単純な繰り返しではないUltra-high-resolution(UHR)な画像を生成するフレームワーク。
ここでのUHRな画像はここでの8K(8192 x 5456)や16K(16384 x 10912)。

SinGANとかone-shotでの画像生成はあるが解像度は1K(1024 x 1024)ぐらいが現状。
繰り返し構造を見つけて拡大する方法もあるが、それだと大きな形を生成できないし学習データも大量に必要。UHRな画像を集めるのも大変。
また、UHRな画像を生成するにはかなりのGPUメモリが必要という問題もある。
手法
- 大まかな構成を生成するGlobal Structure Generation
- 画像全体の解像度を上げるIn-memory super-resolution
- GPUメモリの限界を迎えたとき画像をパッチにして解像度を上げるSeamless subregion-wise super-resolution

Global structure generation
大まかな構成となる画像をノイズから生成する。
アーキテクチャはHP-VAE-GANを採用。
HP-VAE-GANは多様な画像を生成できるが画像全体の一貫性が少々弱い(だから大まかな画像生成に使う)。
生成過程は下記式。

はGenerator、
は生成した画像、
はノイズ、
はアップサンプリング。
始めノイズから生成し、のときはpatch VAEで、
のときはpatch GANでで生成する。
風景画像には垂直方向に強いバイアスがある。空は上に海は下とか。水平方向はほとんどない。
だからといって座標も入力すると、1枚の画像からの学習では生成結果が座標と強く結びついて多様性が失われる。
そこで垂直方向のみの位置埋め込みを入力する(図4)。

In-memory super-resolution
画像をそのまま受け取り解像度を上げるコンポーネント。
学習済みのESRGANを調整して利用する。zero-shotの超解像系の既存手法も存在するが学習済みESRGANを使ったほうが結果が良かった。
DIV2KとFlickr2Kで事前学習する。
前のステップ(Global structure generation)で生成した画像 にノイズを加えてより高解像度な画像
を得る。
はこのステップでのGenerator、
はノイズ。
subregion-wise super-resolution
前のステップのように画像全体を入力とするとGPUメモリが不足するようになってからのステップ。
画像をパッチに切り分け、それぞれの解像度を上げていく。

単純に超解像するとパッチを戻したときにパッチ同士の境界の連続性が失われるので工夫する必要がある。
この不連続性の原因はzero paddingにあるとして、既存手法ではパッチ切り出し時点でオーバーラップして切り出すことでzero paddingをなくす手法やzero paddingをなくすためにconvolutionを作り変えるものなどがあるが、ここでは簡単な前者を選択。
オーバーラップは受容野のサイズより大きい必要があるが、理論的な受容野のサイズ(TRF)はネットワークの深さに比例する。
ただ、実際に有効な受容野のサイズ(ERF)を分析するとネットワークの深さの平方根に比例するという既存研究の報告がある。
そこでERFの半径分をオーバーラップした。
オーバーラップのありなしの結果が図7。

Global structure generationのステップのlossは、再構成loss(MSE)、adversarial loss、WGAN-GP lossとKL loss。まさかのAppendix。
次の2つのステップのlossは、再構成loss(L1)、RaGANという手法のadversarial lossとperceptual loss。




所感
既存手法の組み合わせがメイン。
超解像のために学習済みのESRGANを使うのは確かに良さそう。
また、風景画像のバイアスとして垂直方向方向のみの位置埋め込みを使うのはなるほどと思った。今回は1枚の画像からの生成なので座標を位置埋め込みにするのは確かによくなさそう。