[論文メモ] Visual Attention Network
画像系タスクに合わせたAttentionとしてLarge Kernel Attention(LKA)を提案

空間的に離れた情報同士を扱う方法として大きく2つの方法がある。
1爪がNLPで使われていたSelf-Attention(SA)を使う方法で、画像をパッチに分割しトークン列として処理するが
- 画像を1Dとして扱うため元の2D構造が無視される
- 解像度が大きいと計算量が膨大になる
- 空間方向を考慮したAttentionなので、画像にとって大切なチャンネル方向が考慮されていない
といった問題がある。
2つ目に画像全体をカバーする大きいカーネルサイズのConvolutionを使う方法がある。これは計算量が大きく、パラメータも多くなってしまう。
手法
提案するLKAは図2のように大きいカーネルサイズのConvolutionをDepth-wise Dilation Conv(DW-D-Conv)とDepth-wise Conv(DW-Conv)と Point-wise Conv(PW-Conv)に分解する。
カーネルサイズのConvolutionはカーネルサイズ
でdilation
のDW-D-Convとカーネルサイズ
のDW-Convと
のPW-Convとなる。
これによりSAと同じように離れた点同士の関係を低コストで計算できる。あとはこれをAttention Mapとして計算する(下記の式1, 2)。

は入力特徴量。
LKAは表1のようなConvolutionとAttentionの両方のアドバンテージを持つ

LKAを使ったネットワーク、Visual Attention Network(VAN)について。
VANはピラミッド構造で解像度が異なる4ステージからなる。
各ステージは図3(d)の構造。

各ステージ毎のチャンネル数や解像度は表2を参照

パラメータ数とFLOPs

実験・結果
ImageNet-1Kのクラス分類、COCOのObject Detec tion、ADE20KのSemantic Segmentation。
tion、ADE20KのSemantic Segmentation。




Grad-CAMで可視化

Ablation study

[論文メモ] SPEECH DENOISING IN THE WAVEFORM DOMAIN WITH SELF-ATTENTION
ICASSP 2022
波形データを入出力として扱うencoder-decoderのdenoisingモデル、CleanUNetを提案。
masked self-attentionが重要らしい。

手法
入力音声はモノラル。
ノイジーな長さの音声
はきれいな音声
と背景雑音
の合成とする(
)。
目的はきれいな音声を取り出す関数を学習すること(
)。
なお時間に対応する出力
は
以前の音声
から予測する。
アーキテクチャは図1の通り。
Convolutionを使ったUNetでボトルネック部分をmasked self-attentionにしている。ボトルネック部分だけなら計算コストも抑えられそう。
lossはきれいな音声との lossと複数解像度のSTFT loss。
スペクトラムを考える(
はhop size)。
複数解像度のSTFT lossは下記。

目的関数はとなるがまだ問題がある。
full-bandのM-STFT lossは無音領域に低周波ノイズが発生することがある。 lossだけだと無音部分はきれいだが、高周波帯がM-STFTに比べ良くない。
そこで16kHzなら4~8kHzといったの半分の部分のみを取り出した
を使った
に変更する。
最終的な目的関数はとなる。


[論文メモ] NOT ALL PATCHES ARE WHAT YOU NEED: EXPEDITING VISION TRANSFORMERS VIA TOKEN REORGANIZATIONS
ICLR2022
Vision Transformer(ViT)においてすべてのパッチ(トークン)は必要ないので注意の少ないトークンをマージすることで精度を保ちつつ高速化する。

図1(a)のようにランダムにパッチをマスクしてもViTの予測に影響しないが、図2(b)のようにメインとなるオブジェクト領域をマスクすると予測が狂う。
またViTは画像を切り出したパッチをSelf-Attention(SA)で処理するので固定長の必要がない、というのがお気持ち
手法
Attentionはいつもの通り

ViTは画像を切り出したパッチからのトークンと最後にクラス予測に使うCLSトークンからなる。
CLSトークンと他トークンとの相互作用は以下の式。

はCLSトークンのクエリベクトルで、Softmaxの部分をまとめ
とするとCLSトークンの出力
は
係数としたバリューベクトルの線形結合と見ることができる。
CLSトークンによるAttentionはクラス予測に影響を与えるトークンほど大きくなるという既存研究の報告がある(自己教師あり学習のDINOの論文の図1を参照)。
arxiv.org
なのでCLSトークンの注意の大きさを元に不要なトークンを削除すればよい、というわけにはいかなくて、削除すると精度が落ちる(表1)

ということで単純に削除するのではなくマージして、トークンの再構成を行う。
Multi-Head SAの各ヘッド]のCLSトークンによるAttentionベクトル
の平均
を使ってtop-k個のトークンを決め、それ以外のトークンをマージする(図2参照)。
正確にはマージではなく、Attention Weightを使った加重平均()

一定の割合のトークンを削除する手法だと、背景に対応するトークンは情報は少ないので削除しても影響は少ないが、画像全体に対してオブジェクトが占める割合が大きいと画像に対してはオブジェクトに関わるトークンを削除することになりパフォーマンスが落ちる。
提案手法のようにマージすれば情報の少ないトークンでも有効活用できる。
本手法を可視化したのが図3。

実験・結果
ImageNetで学習・検証。
提案手法名はEViT。比較対象はDeiTとLV-ViT。
表2のEViT with inattentive token fusionが提案手法で、EViT without inattentive token fusionは不要なトークンを削除するタイプ。
提案手法の方が精度低下が少ない、と言いたいところだが表2を見ると削除もマージも正直あまり差がない(一応標準偏差は小さい)。


学習済みDeiT-S/Bをオラクルにした(CLSトークンが学習済みだと大事なトークンがわかった状態である)。


なおmultiply-accumulate computations(MACs)メトリックはtorchprofileを使って測ったらしい(知らなかった)。
[デスクフリーなディスプレイ] 奥行きの小さいデスクでディスプレイと目の距離を離すために
ディスプレイと目の距離を離したいがデスクの奥行きは短い。かといってデスクの買い替えはしたくないといった欲求に答える手段としてデスクの上にディスプレイを置くのをやめ、専用台座にモニターアームごと設置し移動できるようにしたデスクフリーなディスプレイを提案する。
個人的に大成功だったので同じ悩みを抱えている人のためにもメモを残す。
導入
ディスプレイを見る時間が長くなり目のためにもなるべくディスプレイと目の距離を離したくなった。
だがデスクの奥行きが制限になりディスプレイを離すのにも限界がある。
モニターアームを使うのは悪くなかったが、モニターアームというのは基本的にディスプレイのx軸とy軸に自由を与えるものでz軸については基本近づける方向にのみ自由を与える。奥に押しやり離すこともできなくは無いが、重心がデスクの端になり不安定になるし、アームポールもそちらの方向には強くないのでおすすめはできない。
また、ディスプレイが増えた分デスクのスペースが減った。
普通にノートとか飲み物を置くにも狭い。
これらを解決する一番最もな手段は奥行きのあるデスクに買い替えかつ、モニターアームを使用することだが、この解決方法に対して自分は積極的ではない。
デスクの変更はコストが高い
個人的にデスクの変更は色々コストが高い。
まず既存のデスクを処分する必要がある。気に入っているデスクは処分したくないし、どうでもいいデスクだとしても処分は面倒だ。
新しいデスクに関しても制約が多い。
まずはサイズ。なかなかちょうどのサイズのデスクはない。高さ調整できるデスクは増えてきたが面積可変はほぼ見たことが無いので購入時に決める必要がある。
小さい場合はまだいい。追加するなり我慢するなりで対応できる。
問題は大きいときだ。デスクを削ったり切ったりするのは見た目やそもそものデスクとしての機能を損なう場合がある。
それに模様替えや引っ越しなどを考えるとその時その時で丁度なサイズのデスクは変わってくる。
デスクはあまり買い替えたくない。
モニターアームは便利だけどそこま便利でもない
モニターアームは便利だがそこまで便利でもないというのが使ってみての本音だ。
「モニターアームにしてデスクが広くなりました」というのを見つけるがモニターの下の空間なんで正直わずかで、ぶっちゃけモニターアームのポールの固定台が占める面積はモニター付属のスタンドの面積とほとんど変わらない(複数ディスプレイなら恩恵はある)。
モニターアームは適切なxyz軸にするためにアームを曲げて調整する。ポールの位置によっては理想のxyz軸にディスプレイを設置できずポールを移動する必要が出てくる。ポール自体の移動は頻度こそ少ないが面倒だ。ディスプレイを破損したりデスクを傷つけたりするリスクもある。
またモニターアームを使う場合、デスクがモニターアームを設置できる必要がある。
アームポールをつける箇所はある程度の強度ときれいに直角である(R加工されていてはだめ)必要がある。グロメットマウントすればいいという意見もあると思うが、グロメットマウントする場合はデスクに穴を開ける必要や、穴が開けられる必要がある(引き出しがあるとだめとか)。またポールの移動時には穴を開け直す必要があり、トライアンドエラーしにくい。
モニターアームはディスプレイを顔に近づけるのは得意だが、逆に遠ざけるのは苦手だ(と思っている)。
アームポールにぶつかったり、そもそもアームの長さが足りなかったり、重心がデスクの足から出てしまったり(不安定になる)と遠ざけるのは難しい。
以上のことから「奥行きのあるデスクに買い替え」and 「モニターアーム」は避けたい。
そもそものメインの目的は「ディスプレイから目を離すこと」だ。よく考えると「デスクを大きくする」のは「ディスプレイから目を離すこと」を達成するための一つの手段であって目的ではない。他の目的(ものを置きたい)とかを同時に解決できるからそれしか考えられなかったが他にも手段があることに気がついた。
自分の欲求を整理しよう
- 既存のデスクを使いたい(買い替えはコストが高い)
- ディスプレイから目を離したい。最低でも90cmくらい(一番の目的)
- ディスプレイはxyz軸全てに常識的な範囲で自由であってほしい(可能であれば)
これらを解決する手段として思いつくのはディスプレイとデスクを独立させることだ。
とりあえずこの方法を「デスクフリーなディスプレイ」と呼ぶことにする。
既存手法
デスクフリーなディスプレイを実現できる既成の製品は存在する。
こういうキャスター付きのテレビスタンドだ。

複数ディスプレイに対応した製品もないわけじゃない。
これとかは複数のディスプレイに対応している。
ただ高い。10万近くは流石に試すにも厳しいし、ディスプレイの位置についても自由度も低そうだ。縦に2枚並べるとかしたいんだ!
そこでこれに近いものを自作することにした。
提案手法(デスクフリーなディスプレイ)
ということで作ったのが結果がこれ

必要なものはキャスター付きの台座とモニターアーム。
要するにモニターアームを設置できてかつ移動できるものを作れればいい。
まずは台座としてメタルラックを選択。メタルラックである必要はなく、次の条件を満たせばいい。
- モニターアームのポールがつけられる(安定もする)
- ディスプレイを複数載せられる耐荷重があること。メタルラックならそれなりに大丈夫
- キャスターで移動できる。地震対策やレイアウト変更、用途を幅を広げるのに役立つ
今回は小さいやつを買った。

重心バランスは悪くなるが小回りがきくし、床面積も取らない。結論から言うと耐荷重も問題なかった。
より重いものを乗せるなら22mmではなく35mmとかのメタルラックにしたほうがよい。
背が高いのを買ったのは半分にして別々に使うため。
そしてモニターアームとポール。
まで対応 45-241-224")
アームは有名なエルゴトロンのLXデスクマウントモニターアーム。AmazonやHPのOEM製品も同じなので色や値段で決めていい。
今回はこれを2つ購入。
また長いアームポールがほしいのでこちらを購入。径が35mmなのでエルゴトロンも問題なく使用できた。
 MARMP194E")
今更だが、エルゴトロンにはロングポールがあるのでこちらをおすすめする。
まで対応 45-549-026")
ぶっちゃけ70cmのところにアームをつけることはないだろうし(バランスが悪すぎ)、安定感も違うので少々高くてもエルゴトロンのロングボールを購入することをおすすめする。
また、ポールを短くして台座のメタルラックを高くするのもありだったが、モニターの下方向への自由度が減るのでそれは棄却した。
メタルラックを組み立て、アームポールをメタルラックに取り付ける。取り付けるときは木の板やアームポールの補強板を使った方がいい。
")
なくてもいいかもだが、あったほうが圧倒的に安心だ。事故ってディスプレイを修理するのに比べれば安い。
自分はメタルラック用の板とホームセンターで買った木の板、そして補強板を利用した。

補強板やアームポール、木の板にはそれぞれ両面テープを貼った。滑り止めのゴムは付いてるが意外と滑る。両面テープのが安心。
メタルラックの重心を安定させるために下を物置にして荷物を置いたほうがいい(なるべく重いもの)。
自分は使わなくなった裁断機を置いてる。デスクトップPCを置いてもいいかもしれない
これで移動式のモニター台が完成した。

使っているディスプレイはEIZOのEV2736という骨董品(右側)と下記の2つ。
")
")
EV2736と上のEV3895をモニターアームにつけ、下のU4919はEV2736のスタンドに取り替えてメタルラックの上に置いた。
U4919の純正スタンドは下までディスプレイを下げられなかったのでEV2736のスタンドに変更した。
なおU4919はエルゴトロンLXでは少々きつかった(締めてもお辞儀しそうだった)のを報告しておく。
EV3895はエルゴトロンLXで安定してる。エルゴトロンLXの対象の大きさではないので自己責任で。
3つとも重量級のディスプレイだが安定している。
結果
このデスクフリーなディスプレイにしたことで様々なメリットがある。
既存のデスクのままディスプレイから目を離せる
モニター台を移動することでディスプレイから目を離すことができるようになったのでデスクの買い替えは必要ない。
なんならテレビの視聴距離まで離すことも可能だ。
お気に入りのデスクとかをそのまま流用できるし、買い替えのリスクから開放された。
デスクを広く使える
モニターアームを使ってもアームポールをつけた部分に面積を取られるし、浮かせたとはいえディスプレイとデスクの間はそこまで大きくないので下におけるものは限られている。
ディスプレイがデスクから独立したのでデスクを完全に自由に使えるようになった。
ディスプレイを置かないならデスクは奥行き60cmもあれば十二分だ。
デスクの制約から開放される
モニターアームをつけることも無いので天板強度やポールをつけるための形、倒れないための重量等必要ない。
言ってしまえば折りたたみの簡易デスクだって問題ない。
デスクは引っ越し・模様替え等色々制約になる。
ディスプレイの用途の幅を広げられる
移動ができるので、例えばランニングマシーンとかの前に持っていくもよし、ベッドの横に持っていくもよし。
必要なときに必要な場所に持っていける。モニターアームなので高さ調整もそれなりに簡単だ
ディスプレイをデスクより下げられる
ディスプレイは並べても縦横2枚が最大だと思っている。つまり最大4枚だ。
一時期横に3台並べたこともあったが、見た目はそれっぽいが端から端までの移動は正直辛く実用的ではなかった。
目線の移動はディスプレイ2枚までが現実的だ。
横は制約もすくなく2枚は難しくない。問題は縦2枚でこれが以外と厳しいと気がついた。
自分が大きめのディスプレイを使っているせいもあってか縦に2枚並べるとどうしても正面にディスプレイを持ってこれないのだ。
個人的に1枚は顔の真正面に、もう一枚は多少傾けてその下に欲しい。しかし、ディスプレイの縦が大きいと下のディスプレイの傾きが顔のに向かず天井を向いてしまいどうにも使い勝手が悪い。
そこでこのデスクから独立したディスプレイが役にたつ。
デスクから少々離れると、ディスプレイがデスクより多少低い位置にあっても見える(角度的に)。
こんな感じ。

なので大型(ここでは27インチの縦幅を想定)ディスプレイでも縦に並べることができる。
デメリットについても書いておかないとフェアじゃないので書くが、正直ほとんどない。
見た目
メタルラックに棒が生えててそこにディスプレイがうようよしている。決して見た目は良くない。
まあでも基本的にデスクの奥に置くのでメタルラックもポールもそんなには目立たない。なにより仕事部屋におくものなので仕方がないだろう。
自分は見た目を気にしない(デスクの奥で気にもならない)。
地震対策
重量のあるデスクにモニターアームでくっつけてるわけでは無いし、重心がかなり上にあるのでバランスも悪く地震に強いとは言えない。
ただ足がキャスターなので揺れに多少は強いはず。メタルラックを大きくすれば多分地震耐性が上がるだろうが床の専有面積も増える。
このあたりはバランスだろう。
逆にデスクにものが置けないかも(ディスプレイをデスクより低くすると)
デスクより下にディスプレイをおけるようになったのは良かったがあまり背の高いものを置くとディスプレイが見えなくなる。
まあそんなに背の高いものを置かなければいいんだけど。
置くにしても手前にすればよい。
正直デメリットはこれだけで(地震は少々見過ごせないが)メリットのほうが大きく上回る。
おわりに
個人的にこのデスクフリーなディスプレイ環境は非常に気に入っている。
机が広くなったし、机の移動もしやすくなった分、掃除もしやすくなった。
作業用デスクとディスプレイを置く場所は別にすべきだ。
- ディスプレイを顔から離したい
- デスクの買い替えはしたくない
といった方は是非とも試してみて欲しい。


ケーブル周りはなんとかしたい(やらないだけ)。
[論文メモ] NNSPEECH: SPEAKER-GUIDED CONDITIONAL VARIATIONAL AUTOENCODER FOR ZERO-SHOT MULTI-SPEAKER TEXT-TO-SPEECH
arxiv.org
間違えてるかもしれないので注意。
Conditional VAE(CVAE)を使ったzero-shot text-to-speech(TTS)の提案。
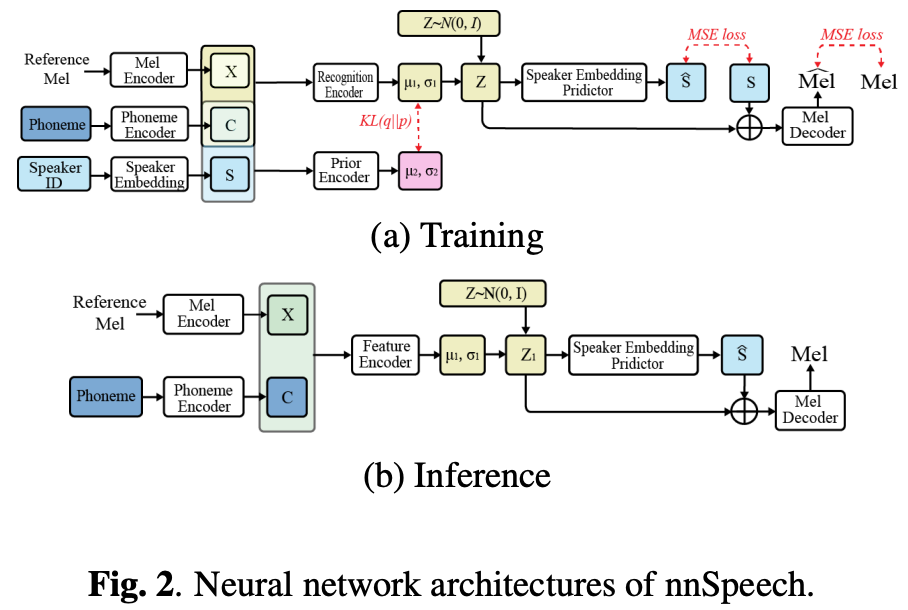
既存手法だとほかfine-tuningしたりタスクで学習したSpeaker Encoderを使ったりする方法があるが、fine-tuningはデータの保存や学習コストが高い(ユーザーが多いと更に大変)、Encoderを使うのはクオリティが低い(Encoderの解像度だと表現しきれない)。
なので提案するnnSpeech(no new speech)ではSpeakerをガイドとしたCVAEを利用してzero-shot化する。
手法
CVAEは条件付きのVAEで下記の条件付きの対数尤度で学習する。
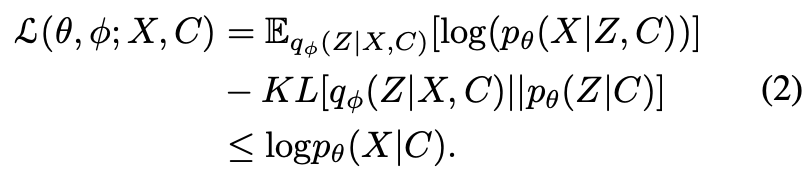
をメルスペクトログラムEncoderの出力、
を音素Encoderの出力とする。
メルスペクトログラムEncoderはAdaIN-VCのものを、音素EncoderはFastSpeech2のものを利用する。
条件付き分布を考える(
、
はネットワークでモデリング)。
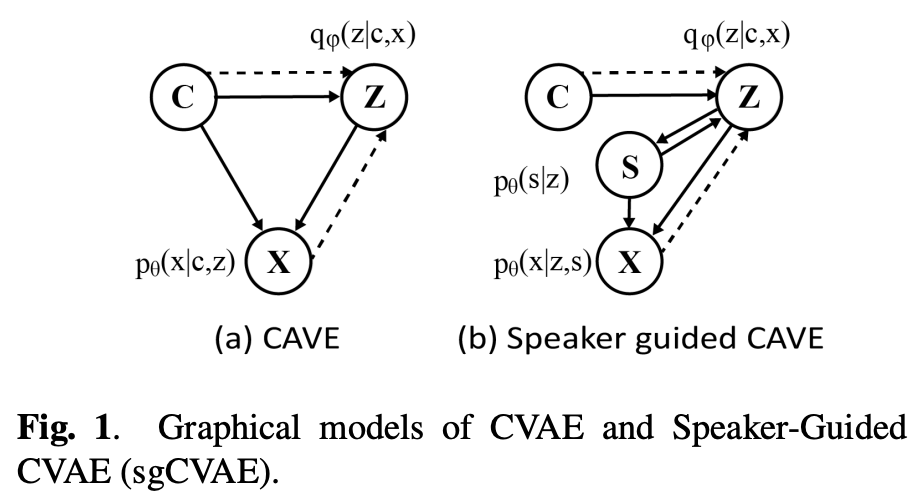
図1(a)のように真のを
でモデリングすると、メルスペクトログラム
を再構成するときに潜在変数
が話者情報を持つ必要があるため直感に反する。
そこでspeaker-guided CVAEを提案する。が話者情報
に基づいていると仮定する(
)。そして
を
で予測する。
は
の情報を含んでいるので
とできる。
もとの条件付き分布を書き換えて、になる。
と
はガウシアンに従うと仮定して、それらの平均、分散は
からMLPで予測する。
lossは話者情報で変更したELBOの最大化

一項目と二項目のは生成したメルスペクトログラムと話者埋め込みに関するものでELBOの最大化のためにはMLEを最小化すれば良い。

三項目はKLの最小化。
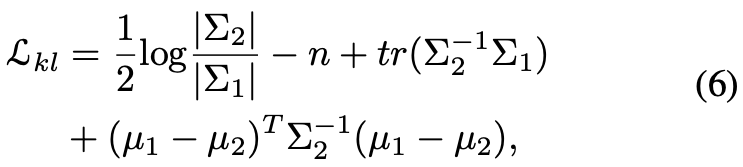
最終的なlossは下記ではハイパラ。

なおボコーダはHifiGANを利用。
実験・結果
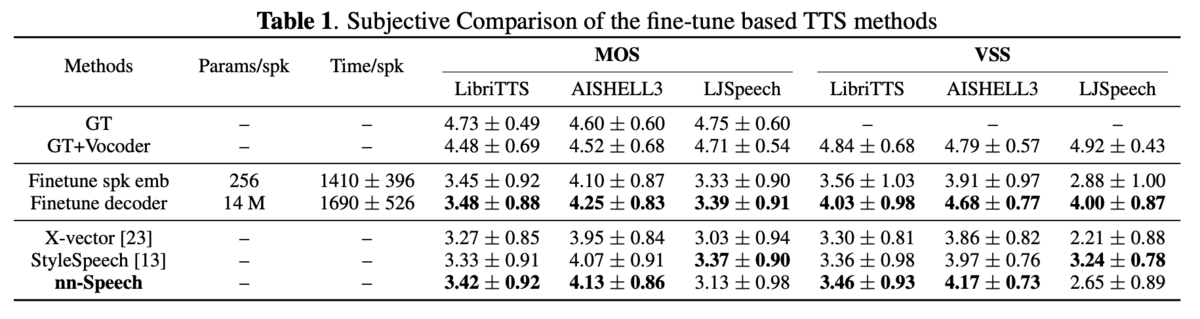
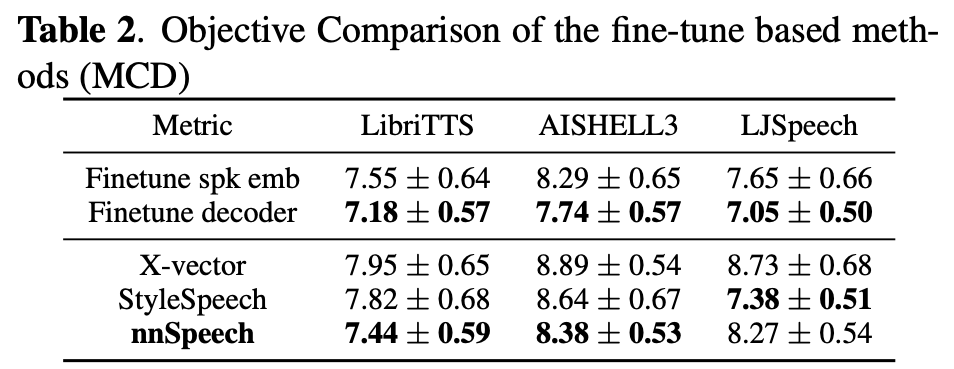
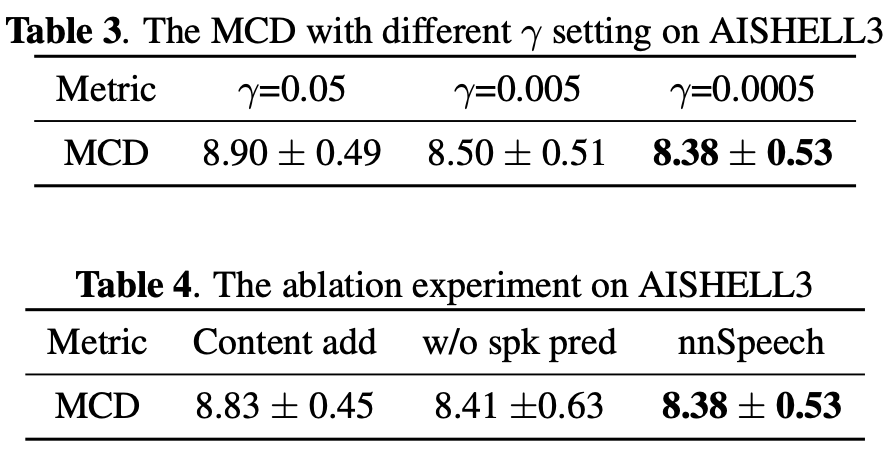
所感
paper内でデモや結果のリンクがなかったのは珍しい(VC系は最近デモの公開が多いので)。
それ故に少々結果は懐疑的。ぶっちゃけ数字だけでは何もわからない。
[論文メモ] Multimodal Conditional Image Synthesis with Product-of-Experts GANs
スケッチやテキストなどのマルチモーダルを条件としたProduct-of-Experts Generative Adversarial Networks (PoE-GAN) の提案。

既存のConditional GANは条件としてスケッチやテキストなど1種類の入力を条件としていた。しかし、それだとスケッチのが説明しやすいときや逆にテキストのが説明しやすいときなどの場合に対応ができないよねというお気持ち。
手法
個モダリティ
と画像がペアになったデータセット
が与えられたとき、これらのモダリティの部分集合を入力として画像を生成する生成モデルを学習する(
)。
条件が個あるので
通りの条件での生成が可能で、当然モダリティが1つの場合(
)や空の場合(
)でも生成できる必要がある。
モダリティとしてはテキスト、スケッチ、セグメンテーションマップ、画像(スタイルのリファレンス)を採用するが、フレームワーク的には他のモダリティも簡単に導入できる。
Product-of-experts modeling
条件として入力するモダリティは画像生成時に満たすべき制約であり、与えられた条件を満たす画像集合はそれらの条件を1つずつ満たす画像集合の積集合の部分になる(図2)。

ということで同時分布がある1つのモダリティ条件とした分布
、
の積として表現できると仮定する。
このように個々モダリティから生成する”エキスパート”を"掛ける"のでproduct-of-experts(PoE)と呼ばれる。
Generatorはlatent code を入力して画像
を生成するが、
は
に対して一意に決定するので
を求めるのは
を求めるのに等しい。
をpriorとして
を構成するのにPoEを下記のようにモデリングする。

は一つのモダリティを条件としたエンコーダ。
Multiscale and hierarchical latent space
テキストとスケッチなどでモダリティの解像度が異なるのでlatent spaceもそれに合わせて階層化する。
とし、
は特徴ベクトル、
を解像度ごとの特徴マップ(
,
は画像と同じ解像度)とする。
したがって先程の式(1)の各要素が分解でき、下記の式(2)のようにできる。

より解像度の低い、抽象度の高いを条件として、その積の形式になる。
ここで、
は平均と分散をニューラルネットでパラメータ化された独立したガウシアン。
なおはガウシアンの積なのでガウシアンになる(下記の式3)。
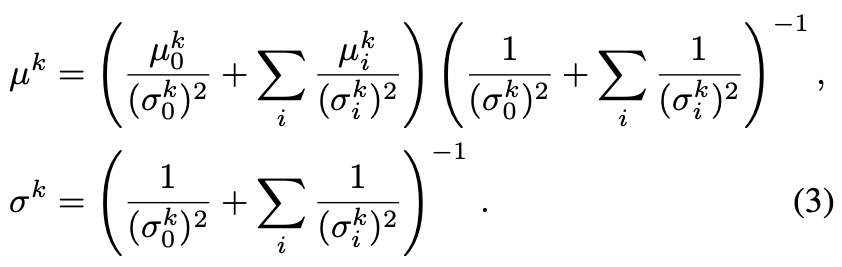
. Generator architecture
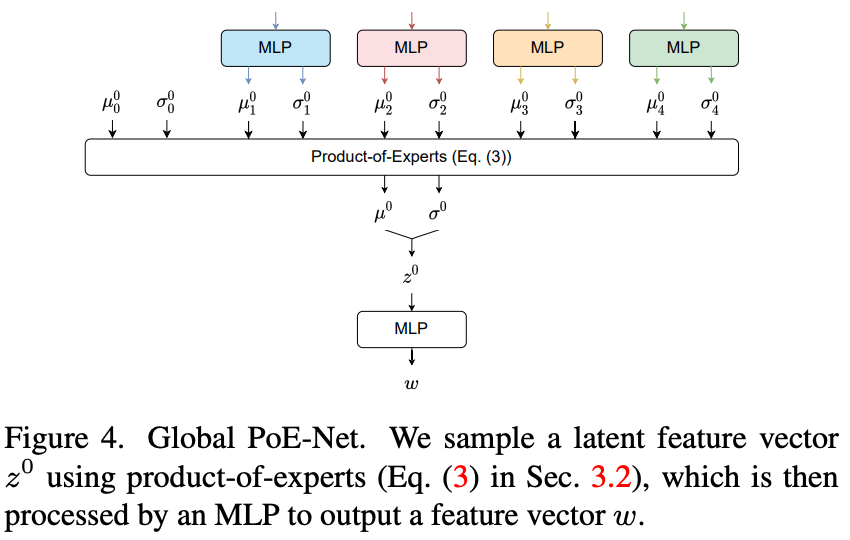
アーキテクチャは図3を参照。各モダリティをエンコード後、Global PoE-Netで集約する。

セグメンテーションマップとスケッチは入力をskip connectしたCNNで、スタイルはResNet、テキストはCLIPを使ってそれぞれエンコードする(図11)。

Global PoE-Netは図4参照。
MLPでガウシアンを予測し、
をサンプリング。これがdecoderのメインの入力になる。
decoderはResBlockからなる(図5を参照)。

を入力としてそれに対してconvolutionをするのがメインだが、途中で解像度毎のセグメンテーションマップとスケッチを式(3)のPoEで処理した
を使ったSPADEと
をMLPに入れて得た特徴ベクトル
を使ったAdaINを行うlocal-global adaptive instance normalization(LG-AdaIN) レイヤーを挟む。

テキストやスタイル情報は画像全体の大まかな情報を持っているのに対して、セグメンテーションマップやスケッチは画像の詳細も含んでいることを考えると、セグメンテーションマップとスケッチのみ途中で注入するのは理解できる。
Multiscale multimodal projection discriminator
Discriminatorは画像と条件
を受け取り本物かどうかのスコア
を出力する。
各モダリティが独立と仮定すると下記の式。

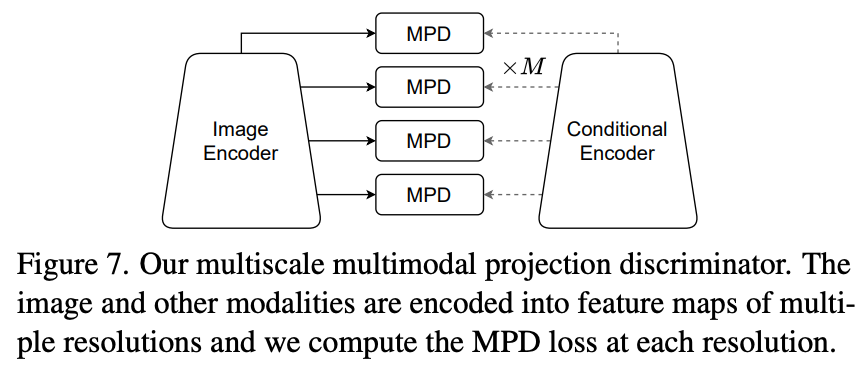
Projection Discriminator(PD)をマルチモーダル用に一般化したMultimodal PD(MPD)を提案(図6)。

画像、条件それぞれを特徴空間に埋め込み、条件なし項に関しては画像埋め込みをLinearで出力、条件ありの項に関しては条件の埋め込みと内積を取り、それらの和として表現するのがPDだが、MPDでは条件ありの部分を条件の数だけ増やす(式6)。

セグメンテーションマップとスケッチに関しては空間的なモダリティなのでそれぞれの解像度毎でMPDを行う(Multiscale MPD)
Losses and training procedure
Latent regularization
PoEの仮定(式1)の元、条件について周辺化したpriorと条件なしのpriorは一致する。

なので各解像度でKLを最小化。はモダリティに対して、
は解像度に対しての重み。

Contrastive losses
contrastive lossはペアデータのバッチが与えられたとき、式9のように、ペアでないものに関しては離したままペア同士は似るようにするloss。

ここでは画像に関してと条件に関しての2種類のcontrastive lossを利用。
画像に関しては学習済みのVGG encoderを用いて本物の画像と、その条件から生成した画像
について類似度を最大化する。

perceptual lossに似てるが、それよりパフォーマンスが良いらしい。
条件に関しては2つあり、1つ目は本物の画像と条件
それぞれの埋め込みに対してで下記。

はDiscriminatorの中間表現で式6と図6(b)を参照。
このlossはあくまでDiscriminatorのupdate用で、Generatorには本物の画像ではなく生成画像に関してlossをとる。

最終的なlossは以下。

は重み、
は
のgradient penalty。
実験・結果





所感
複数のモダリティを条件としたときのcGANの提案。
思っていたよりシンプルだった(全部埋め込みにして生成)。
確かに、テキストやスタイルのが表現しやすいこともあるし、スケッチで表現したいときもある。
参考になった点は
1つ目はモダリティによって入力する場所を分割すること。確かにスケッチやセグメンテーションマップは生成結果の詳細部分への制約になるのでそれなりの解像度を保ったまま入力したい。逆にテキストやスタイルは画像全体に関わることなので入力で十分。StyleGANの生成結果制御でも似た議論があった。
2つ目はKL loss。確かに周辺化すれば一致するよね。
3つ目はLG-AdaIN(AdaINとSPADEの融合)。取り扱う情報の解像度に合わせて2種類を使い分けるのはなるほどとなる。
自分でcGANを使うにあたって参考になることが多かった。
[論文メモ] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
StyleGAN3でImageNetのような多様な画像を生成できるようにした。

SIGGRAPH 2022
StyleGANはハイクオリティかつある程度の制御可能なGANだが、制御可能にできる分、構造が一定でない分散の大きいデータセットの学習には適さない。提案するStyleGAN-XLはこれを解決してImageNetのような分散の大きなデータの生成を可能にした。
既存手法ではImageNetを学習できるものもあるが、少なくともStyleGAN3をナイーブに学習しても厳しい(図1参照)。
特に高解像度の生成(1024x1024)になると安定しない。
目的はStyleGAN3でImageNetを生成できるようにすること。「生成できる」とはISやFIDといった既存の評価指標で定義。
手法
既存のStyleGAN3のデフォルト設定をConfig-AとしてConfig-Fに至るまで変更を加えていく。

正則化
StyleGAN3ではstyle mixingやpath lengths regularizationは廃止された。
特にpath lengths regularizationは分散の大きなデータセットには不向きと報告されている。
しかし、モデルの学習が十分に進んだ後(200k枚くらい学習したら)に適用するとこれを回避できることがわかった。
Discriminatorにはspectral normalization(gradient penaltyなし)と、始めの200k枚の入力にはのガウシアンフィルタを適用する。
Discriminator blurringはStyleGAN3-Rの学習で利用され、Discriminatorが高周波に注目するのを防ぐ。
低次元の潜在空間
ProjectedGANの適用を考える。ProjectedGANについては以前のメモを参照。
ninhydrin.hatenablog.com
ProjectedGANはStyleGANよりもFastGANの構造に有効で、その大きな違いは潜在空間の大きさであると考える。
潜在空間 はFastGANが
、BigGANが
、StyleGANが
と大きすぎる。
近年の研究では自然画像は実は低次元に内在しているという主張があり、ImageNetは40前後と推測されている。
512次元でProjectedGANを適用するとその高速化の恩恵を受けられなかった。
そこでを512から64に変更すると、学習が安定し高速の恩恵も得られた。
ベースモデル(Config-A)に対して上記の正則化とProjectedGANを適用したのがConfig-Bとなる。
事前学習したクラス埋め込み
Config-Bだと各クラスで同じような画像が生成される(recallが0.004と低い)。
これはProjectedGANの影響と考え、クラス埋め込みを事前学習した。
Efficientnet-lite0の最小の解像度の特徴をImageNetのクラス毎に平均し、それをconditionとして利用する。
これによりrecallが0.15に上昇。この設定をConfig-Cとする。
Progressive Growingの再導入
Progressive Growingはネットワークを徐々に大きくして高解像度の生成を可能にした手法だがアーティファクトが出る等の問題でStyleGAN2で消えた。StyleGAN3ではアーティファクトの原因はエイリアシングであるとわかり、アーキテクチャでそれを回避した。
そこでProgressive Growingを再度考える必要が出てきた。
開始の解像度を16x16として11層使って開始、最終的な1024x1024の解像度のときには39層に成長。
成長時、低解像度の層はmode collapseを回避するために固定される。
これがConfig-D。
Exploiting Multiple Feature Networks
ProjectedGANのablationではFeature Networkとして色々試しているが複数の組み合わせはない。
EfficientNet-lite0を基本として、追加の2つめのFeature Networkのタスク(クラス分類 or 自己教師あり学習)、アーキテクチャ(CNN or ViT)が与える影響を調査。
追加のCNNはタスクが教師あり or 自己教師ありのどちらでもFIDをわずかに下げるにとどまったが、ViTとの組み合わせは大きくパフォーマンスを向上。
これは「教師あり学習と自己教師あり学習で得られる特徴表現は類似している」「CNNとViTは異なる表現を学習している」という既存研究の結果を裏付けている。
これより多くFeature Networkを追加しても大きな改善は得られなかったのでEfficientNetとDeiT-MをFeature NetworkとしたものをConfig-Eとする。
なお特徴表現の参考文献は下記。
教師あり学習と自己教師あり学習の特徴表現について
arxiv.org
CNNとViTの特徴表現について
arxiv.org
Classifier Guidance for GANs
diffusion modelにクラス分類器をガイドとして導入した手法がある。
生成画像を学習済みクラス分類器
に通してクラスの予測
を得る。そしてcross-entropy loss
を
でスケールしたものをGeneratorの追加のlossとする。クラス分類器としてはDeiT-Sを採用。
これによりISが大きく向上。
この設定をConfig-Fとする。
なお、ぐらいがよく、解像度が大きく無いと効果がない(>
)。
各Configでの実験結果はひょう1を参照。

実験・結果
解像度のImageNetの生成。




所感
ImageNetレベルの分散の大きいデータをある程度生成できるのはすごい。
以前DanbooruデータセットでGANを学習した記事を読んだが、そこでもPath lengths lossをやめたとあり顔等のドメインがある程度固定されたもの以外ではそれなりにアーキテクチャやlossを考える必要がある。
ProjectedGANでCNNとViTの2つを利用するというのは使えそう。CNNとViTが獲得する特徴表現はことなることを調べた論文は読んでいたが、こういう利用方法は考えなかった。なるほど。
Progressive Growingは面倒なのでやりたくない。