[論文メモ] Speech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion
arxiv.org
INTERSPEECH 2022
間違っているかもしれないので注意。
ピッチやコンテンツなどを相互情報量を最小化することによって分離させOne-shot Voice Conversionの精度を向上させる。
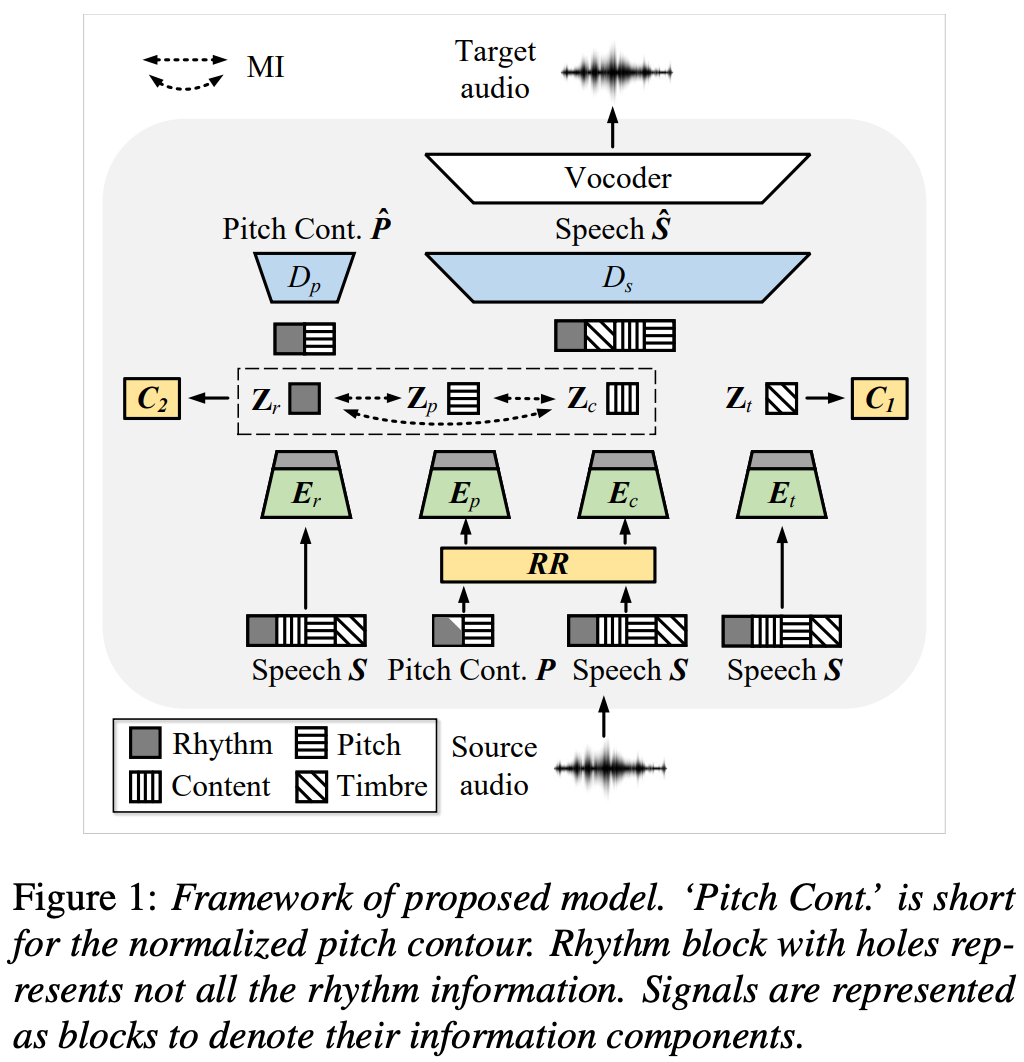
Voice Conversion(VC)の精度向上のためには発話に含まれるピッチやコンテンツなどといった情報をきれいに分離するのが一番効果的で、そのために相互情報量ベースの分離手法を提案。
手法
リズム、ピッチ、コンテンツ、話者の4つに分離するために4つのエンコーダを用意しそれぞれの出力に制約を設ける。
各エンコーダはリズムエンコーダ、ピッチエンコーダ
、コンテンツエンコーダ
、話者エンコーダ
。
ピッチ以外各特徴はメルスペクトログラムをエンコーダに入力して得られる。
ピッチ特徴は正規化したピッチによって得られる。

が各特徴で
はランダムリサンプリング。
メインのデコーダは上記4つの特徴を入力としてメルスペクトログラムを生成する。

はピッチデコーダで学習時のみ利用する。
また各エンコーダの出力した特徴に役割をもたせるために2つの話者分類のモジュールを追加する。

メインのlossはメルスペクトログラムの再構成とピッチの再構成。

各特徴に関しては以下
 について
について
話者エンコーダには話者についての情報のみがエンコードされて欲しいのでクラス分類を学習する。

は
のパラメータ、
はクラス分類モジュールのパラメータ、
はカッコ内がTrueのとき1になる2値関数、
はクラス確率。







