[論文メモ] TIME DOMAIN ADVERSARIAL VOICE CONVERSION FOR ADD 2022
ICASSP 2022
ADD2022のDeepFake検出のタスク用のVoice Conversionモデルを作成しトップになった
Audio Deep Synthesis Detection Challenge (ADD 2022)というのが行われた。近年のVoice Conversion(VC)やText-to-Speech(TTS)の発展により声のなりすましの問題が出てきているから。
ADD2022には以下の3部門がある。
(1) リアルなノイズやBGMのある環境での音声の真偽判定(偽音声はいろいろなTTSやVCで生成)
(2) 部分的に偽の音声に変換し、その部分を検出
(3) 2部門に別れミニマックスゲームを行う
(3)はGenerationとDetectionにの2部門に分かれる。Generation部門はDetection部門に見抜かれないような生成モデルを作り、Detection部門はその逆。まさにAdversarial Attack。
この論文では(3)のGeneration部門に参加しトップをとった。
手法
Detectorに見抜かれないために、対象の音声にできるだけ近づける必要がある。
しかしADD2022で使えるデータ(ターゲット音声、それ以外の音声)は少ないのでaugmentationなどの工夫が必要。
こちらの手法ではVCシステムとpost-processsingの2ステージに分けて処理する。
Voice Conversion
VCシステムの全体像は図2。
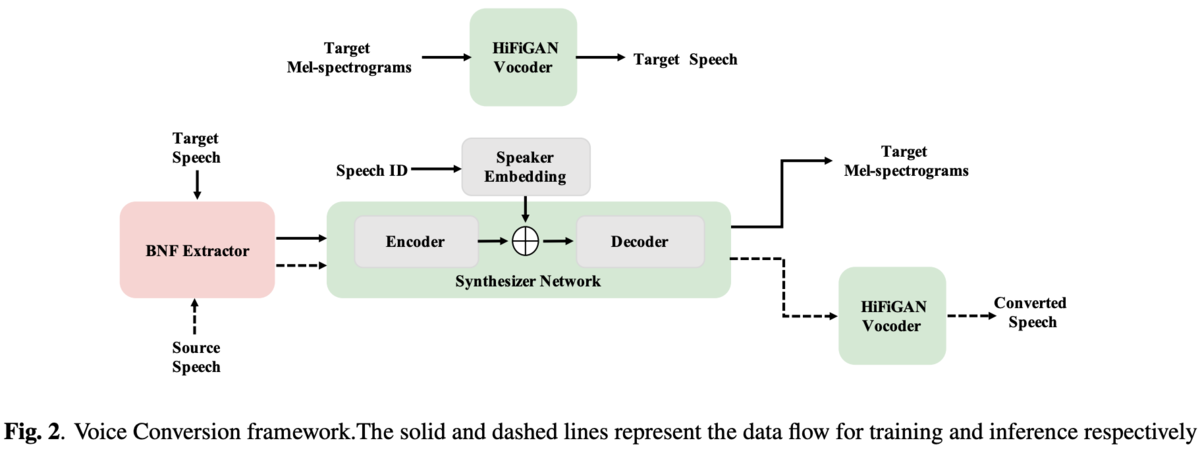
BNF extractor、synthesizer network、 vocoderに分かれる。
BNFはbottleneck featureの略でTDNN7層とLSTM3層のASRを自分たちで用意したデータで学習し、その中間特徴(512次元)を利用。
synthesizer networkはFastSpeech-VCのものを利用。
vocoderはHiFi-GANを利用。
Time-Domain Adversarial Post-Processing
システム全体像は図1。
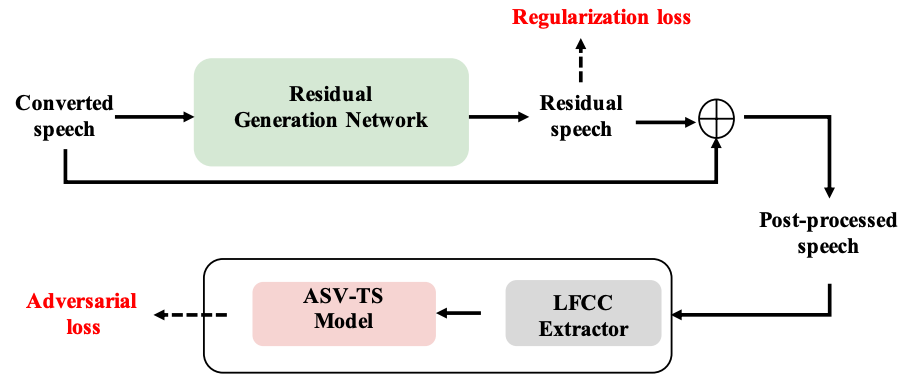
生成した音声にをwhite-box attackで調整する。
ざっくり説明すると、生成した音声を識別器がターゲット音声と間違えるような差分を学習する
まずターゲットの音声かどうかの識別器を作成する。
ResNet-34を使ったターゲット話者の識別機を学習。lossはbinary cross-entropy。
入力は linear frequency cepstrum coefficients (LFCCs) 。
次にターゲット音声との差分を予測するモデル、residual generation network (RGN)を学習する。
RGNはMelGANのようなFCNN。
RGNの出力はResBlockのように入力に加算される。
RGNの学習方法は
1) 生成した音声をRGNに通し差分音声を生成
2) 入力した生成音声に差分音声を足してPost-processed speechを得る
3) 識別器に入力するためにPost-processed speechをLFCCに変換する
3) ターゲット音声の識別器がPost-processed speechをターゲット音声と間違えるようにadversarial training
式的には以下。
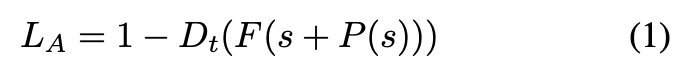
が入力音声、
がRGNで生成した差分音声、
がLFCC特徴抽出、
がターゲット音声識別器。
また以下の正則化のlossも導入する。
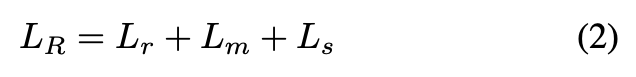
は差分音声の最大値と最小値の差、
は差分音声と0ベクトルとのMSE。
は以下の式。
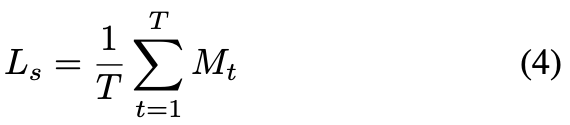
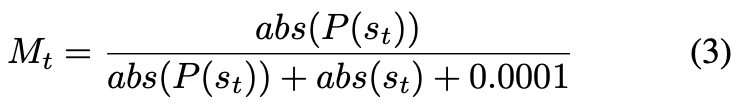
はt番目のサンプル、
は総サンプル数。本物の音声に関しては差分を出ないようにする?説明が少なくよくわからない。
実験・結果
AIShell-3データセットの10人がターゲット。
評価指標は以下の式のdeception success rate(DSR)。
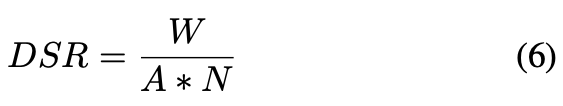
は各識別器が本物と識別したサンプル数、
が総サンプル数、
が識別器の総数。
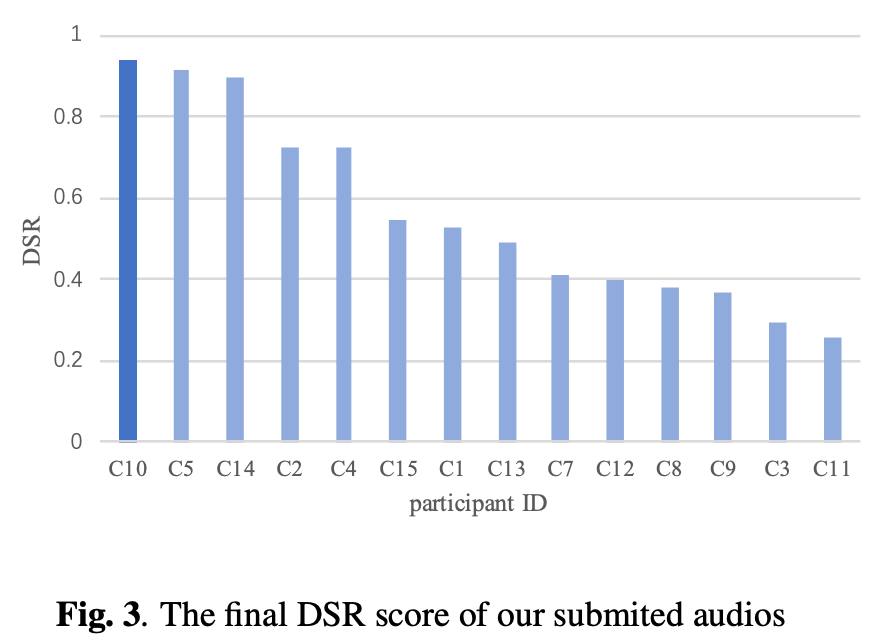
結果が図3、自分たちのチーム(C10)がトップ。
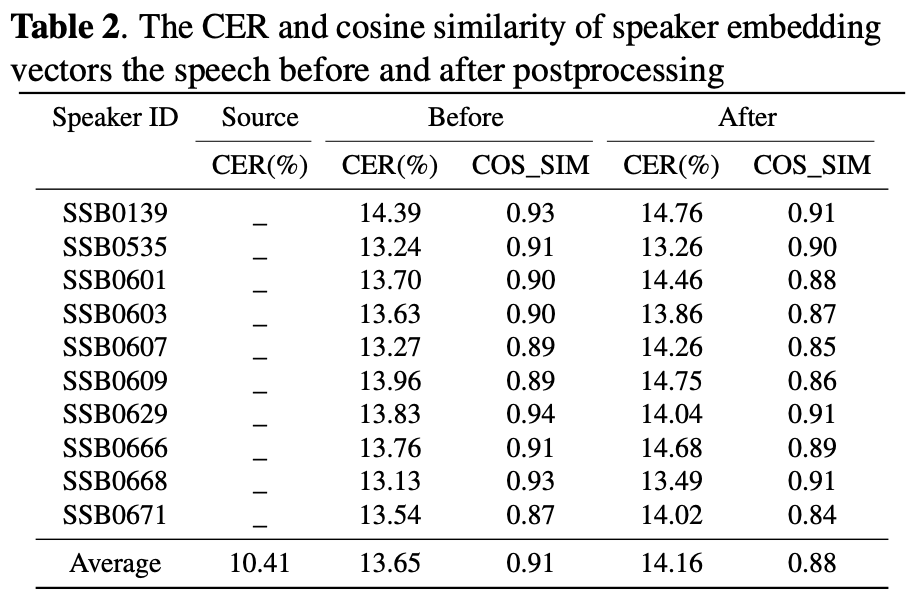
差分処理による話者埋め込みのコサイン類似度(COS_SIM)とcharacter error rate(CER)の変化。
CERは増加し音声として劣化するが、コサイン類似度も増加している。
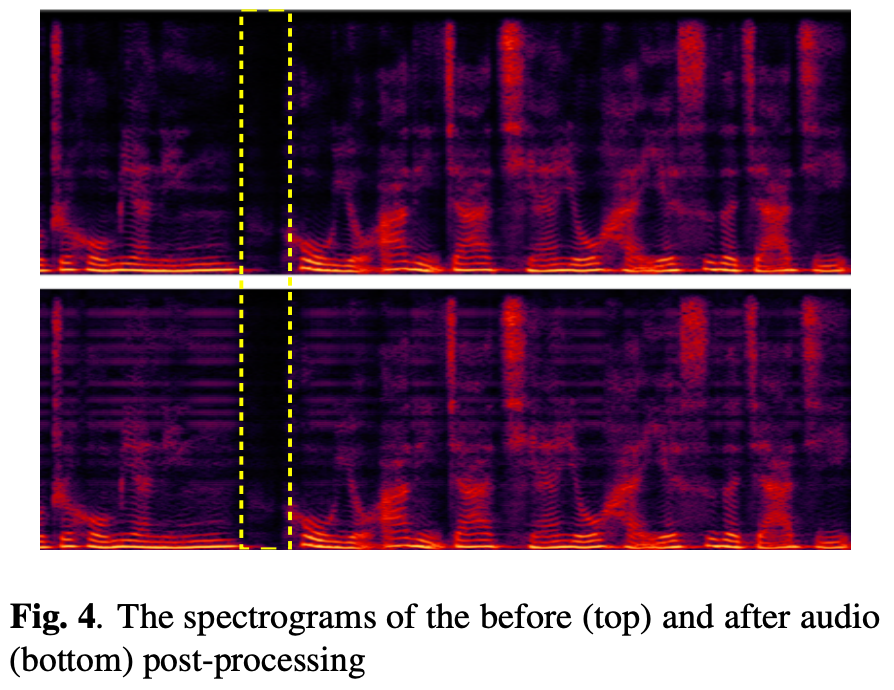
差分処理による変化の例(図4)。
上が処理前、下が処理後だがほぼほぼ変化がなく調整は僅か。
また無音部分(白い破線)には変化がなくRGNが音声にだけ作用しているのがわかる。
所感
ADD2022のタスクがそもそも面白い。
GeneratorとDetector(Discriminator)で別れて参加者同士で競い合うというのは単純な品質を求めるタスクより面白いし、Detectorを他人が作るのでDetectorの弱点がリークしないのもいい。
差分音声を使ったwhite-box attackはDetectorを騙すのには良さそうだが、品質が落ちるので現実では微妙かも。
Detectorが話者性だけでなく、品質てきな部分で合成音声か見抜けるように学習していた場合どうなのか。