[論文読み] Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation
ヒートマップフリーなkeypoint detectionを提案。すべてBounding Box(BBox)で表現。

導入
既存のヒートマップ形式のkeypoint detectionは
1) ヒートマップの解像度が大きくないと正確な予測ができないが、ヒートマップの解像度が大きいとコストが大きい
2) 同じクラスのkeypointが近くにあるとヒートマップが重なり1つのkeypointに扱われる
なのでヒートマップフリーなkeypoint detectionが求められる。
既存手法でkeypointを小さいBBoxの中心で捉える手法がある。
これはローカルな特徴で捉えられるkeypointにはうまく作用する。例えば"目"は小さく切り取ってもわかる。
逆に"腰"はそこだけ切り取られてもわからず、よりグローバルな特徴が必要。
そこでpose objectを導入する。
手法
提案手法はKAPAO(Keypoints And Poses As Objects)。発音は“Ka-Pow!”。
仕組みとしては後述のkeypoint objectの集合とpose objectの集合
を合わせた
を予測する。
keypoint objectは各keypointの中心を小さいBBox で表現する。
はkeypointの座標、
はBBoxの縦横のサイズ(サイズに関してはハイパーパラメータとして与える)。
単純に座標だけじゃなくBBoxにして幅を持たせる理由はなんだろう? -> ablation studyで検証。
pose objectは人間全体を検出するためのもので、keypointの集合を持つ。
keypoint objectはローカルな特徴に紐付いた個々のkeypoint(目や口など)の検出に強いが、複数のhuman poseを作るには対応関係を構築するためにボトムアップな手法が必要になる。
pose objectはボトムアップな手法を必要とせず、keypoint同士の関係を構築できる。
アーキテクチャ
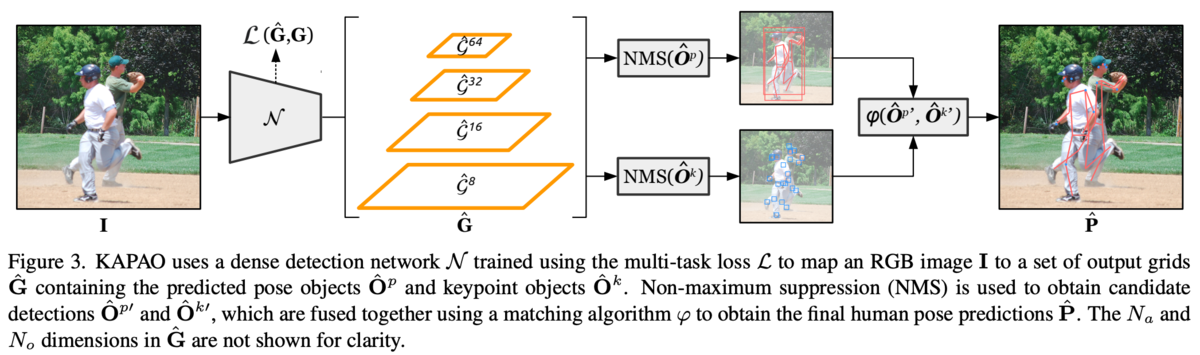
CNNを、入力のRGB画像を
とすると出力はグリッドの集合
として
となる。
なお、
。
はアンカー用のチャンネル数、
はオブジェクト用のチャンネル数。
各オブジェクトの中心が含まれるグリッドがそのオブジェクトの検出を担当する。
feature pyramidな出力になっているのでが大きいほど多段になり、出力グリッドが少ない分受容野が大きい。そのため大きなオブジェクトの検出に向いている。
アンカーは一つのグリッドが複数の異なる大きさのオブジェクトを検出するため。
また隣のグリッドのオブジェクトも検出する冗長な検出の仕組みも導入。
はオブジェクトに関する情報で各アンカー・グリッド毎。
objectness 、グリッド内部でのBBox
、クラススコア
、pose object用のkeypoint集合
。
なのでとなる。
詳しくは図4を参照。
損失関数
損失関数は式(5)~(8)の4つの重み付き和(式(9))。
がobjectness、
がグリッド内部のBBox、
がクラススコア、
がpose objectのkeypoint集合に対応する。
グリッドにターゲットが無いときはとなる。


予測
グリッド(i, j)におけるBBoxとkeypointそれぞれの予測と
を以下のように変換する。

objectnessとクラススコアの最大値の積がしきい値以上のときにポジティプとして扱われ、クラススコアが最大のクラスによってpose objectもしくはkeypoint objectとして扱われる。
余分なオブジェクトを削除するために検出されたpose object、keypoint objectに対してNMSを適用する。
pose objectからkeypoint objectの組み合わせ方はAlgorithm 1を参照。

実験・結果
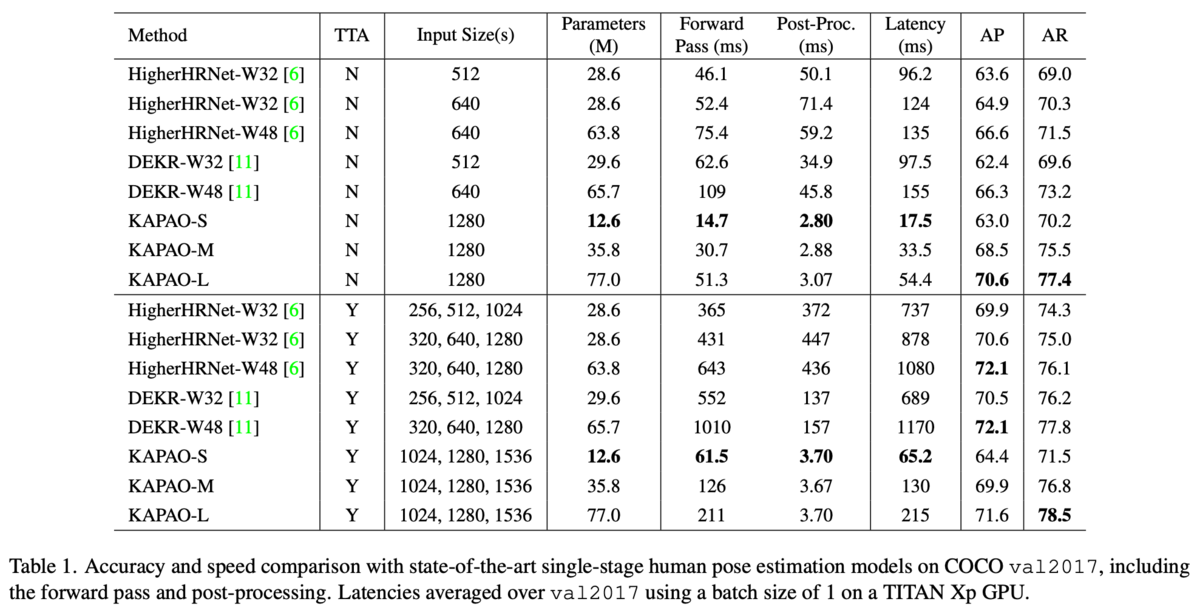
他のsingle-stageの手法に比べパラメータ数が少なく、速度も高速でAP・ARが同等以上くらい。ヒートマップを作成しない分Post-Procが速い。
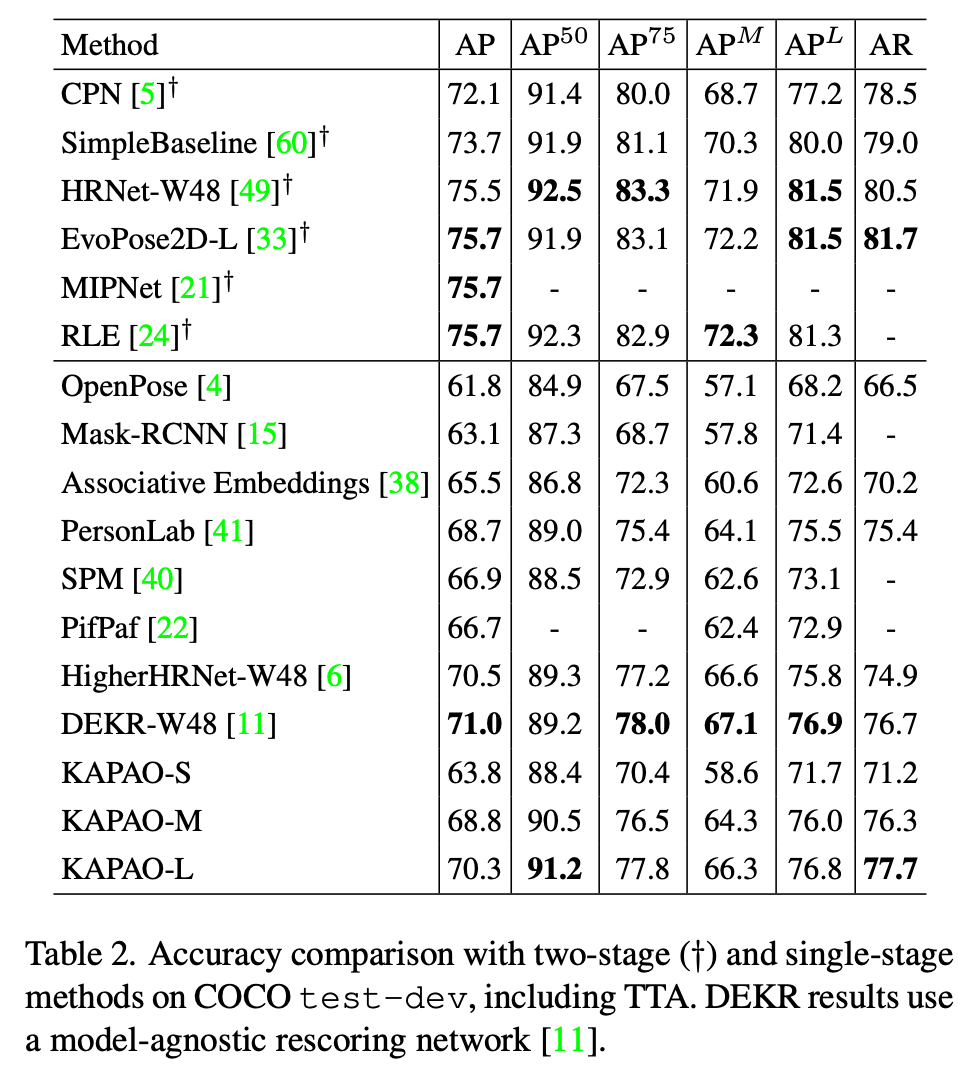
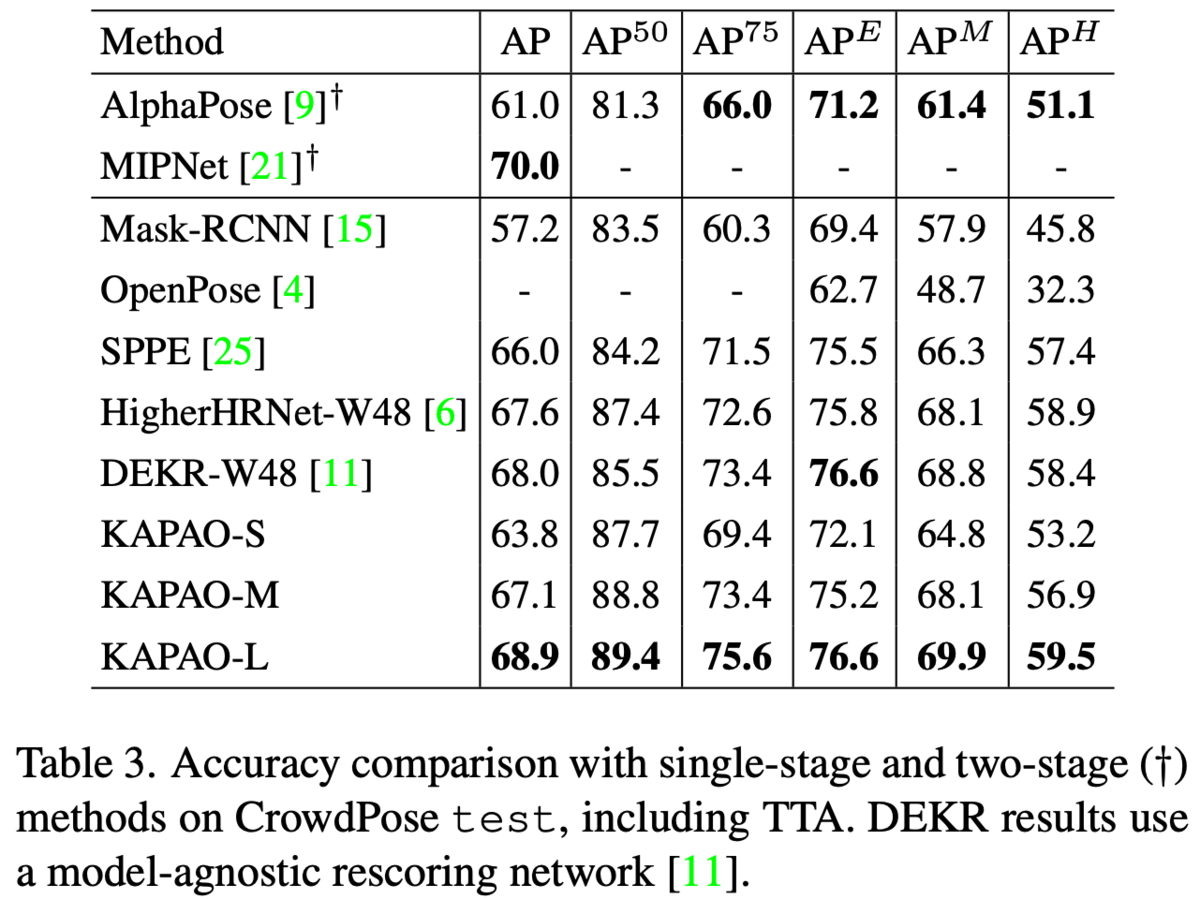
two-stageな手法とも比較。two-stageには劣る。
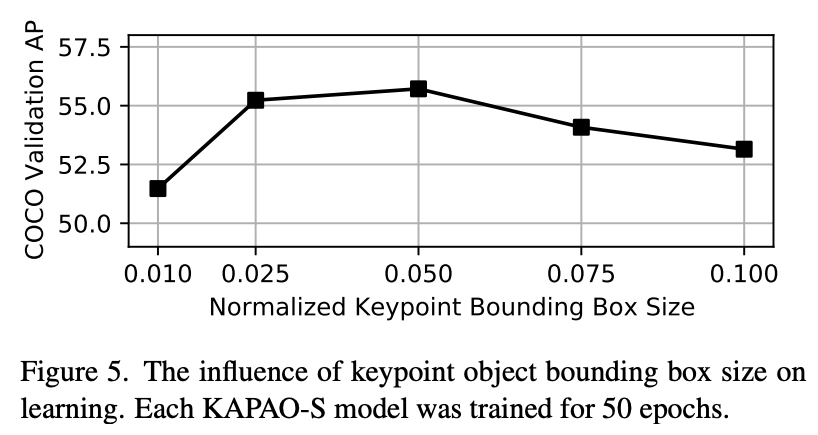
keypoint objectのBBoxサイズについて検証した結果が図5。横軸は。
は安定性が低下。
が最も良い結果だった。既存研究の報告結果と異なり
で急激に悪化。これはkeypoint objectだけでなくpose objectも予測しているためと予測。
所感
object detectionはあまり追っておらず、keypointをBBoxで捉えるという手法を知らなかった。
実験結果だけを見ると高速で良さそうな印象を受けるが、他の手法が現在のSOTAレベルなのか知らないので評価できない。
Rethinkingとあったのでどんなのかなと思い読んだ。