[論文メモ] MIIPHER: A ROBUST SPEECH RESTORATION MODEL INTEGRATING SELF-SUPERVISED SPEECH AND TEXT REPRESENTATIONS
WASPAA
劣化音声をスタジオ品質にするspeech restoration (SR) の提案
deep learning系の音声合成(TTSなど)の性能はASRなどと異なり、学習に利用する音声の品質と量に大きく依存する。
学習元音声が低品質だと、生成される音声も当然品質が悪くなる。
SRで音声の品質を向上できれば音声合成の品質も向上できる。
しかし、SRでアーティファクトなどが出てしまうと合成結果にも反映されてしまう。
そこで、そういった失敗の少ない学習で利用できる音声を生成できるロバストなモデルを目指す。
手法
提案手法名はMiipher。multiple features integrated speech restorationとのこと。
調査の結果、SRにおいて失敗を引き起こす2つ原因に焦点を当てる
1) Phoneme masking: ノイズやリバーブがかかり音声がマスクされている状態
2) Phoneme deletion: コーデックやダウンサンプリングで音素の重要な周波数帯が消えている状態
これらを解決するために2つの工夫を加える
1) SSL features domain cleaning: メルスペクトログラム入力のかわりにSSL(w2v-BERT)特徴を入力する。
2) Transcript conditioning: テキスト情報を用いて消えた音素をインペイントする
Miipherの全体像は図1。
劣化音声とテキスト情報を入力として修復した音声を出力する。音声は24kHz。
アーキテクチャとしては feature cleaner(b)と neural vocoder(c)の2つから成る。

実験結果
w2v-BERT XLを採用し、8層目の量子化前のconformer特徴を利用。
PnG-BERTはWikipediaで学習済みのものを利用。
話者埋め込みは12層のconformerベースモデルを利用。
データセットは2680時間のノイジー音声とスタジオ品質音声のペア。
ノイジー音声はノイズBGMと発話音声から合成。
またaugmentationとしてリバーブやコーデック劣化を適用。
コーデック劣化については表1を参照。
ターゲット音声は670時間の複数の国の英語音声。

実験結果が表2。ほぼほぼ元音声と同じレベルに復元できていそう。

クラウドソーシングによる高品質でない音声データをMiipherを使って高品質化しTTSモデルを作成。
結果が表3。
TTS用データセットのLJspeechレベルのTTSが作成できた。
なおMiipherを使わなかった場合はノイズにより収束しなかったそう。

[論文メモ] RMVPE: A Robust Model for Vocal Pitch Estimation in Polyphonic Music
INTERSPEECH 2023
音楽からボーカルのピッチを推定する
ボーカルのピッチ推定は他の楽器の音が入っているため推定が難しい。
音源分離を利用してボーカルを抜き出してピッチ推定する方法があるが、音源分離の品質に大きく影響を受ける。
そこで音楽から直接ピッチを推定する手法、RMVPEを提案する。RMVPEはRobust Model for Vocal Pitch Estimationの頭文字から。
手法
ネットワークアーキテクチャとloss関数で解決する。
アーキテクチャ
入力はlog mel-spectrogram で、
がフレーム長、
がmelの特徴量次元数でここでは256。
出力は。
アーキテクチャの全体像は図1参照。基本構造としてはU-Netに近い。
RMVPEは主に4つのコンポーネントから成る。
各コンポーネントを構成するREB、RCB、RDBについては図2参照。ICBはREBからAvgpoolを除いただけの構造。
構成するレイヤーに特別なレイヤーはない。


loss関数
出力はで、各フレームのピッチを360次元のセント値で予測する。
なおとした。
360次元はC1(32.7Hz)からB6(1975.5Hz)を20セント間隔に相当する。
ピッチ推定は以下の式のように、max値周辺の加重平均を利用。


はボーカル有無の確信度でしきい値
とした。
学習はシンプルにcorss entropy。

360次元でデータのバランスも悪いので重みを利用。
実験・結果
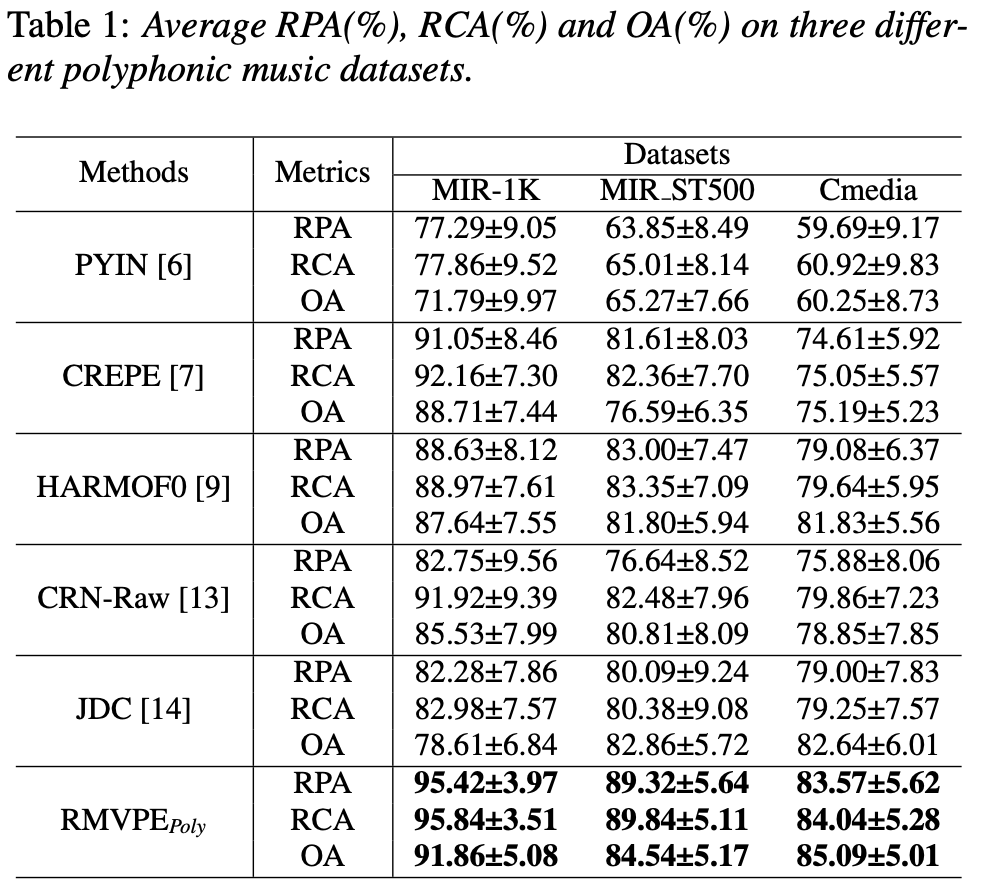
データセットとしてMDB-stem-synth、 MIR-1K、Cmedia 1 and MIR ST500というパブリックなものを利用。
これらはボーカルについてのピッチラベルが付いている。
評価指標は3つ。
raw pitch accuracy (RPA):±50セント以内のピッチ精度
raw chroma accuracy (RCA):オクターブを無視したピッチ精度
Overall accuracy (OA) :ボーカル有無含めたすべてのフレームについての精度
比較対象は5つ。
PYIN、CREPE、HARMOF0は音声のみからのピッチ推定なのでSpleeterを用いて伴奏を削除。
JDCとCRN-Rawはend-to-end。
CRN-Rawは提案手法と同じデータセットで再学習した。
結果が表1。既存手法に比べて良さげ。
encoder-decoderの形がボーカルのピッチ推定に必要な情報だけを取り出しているからと主張しているが、真偽は不明。
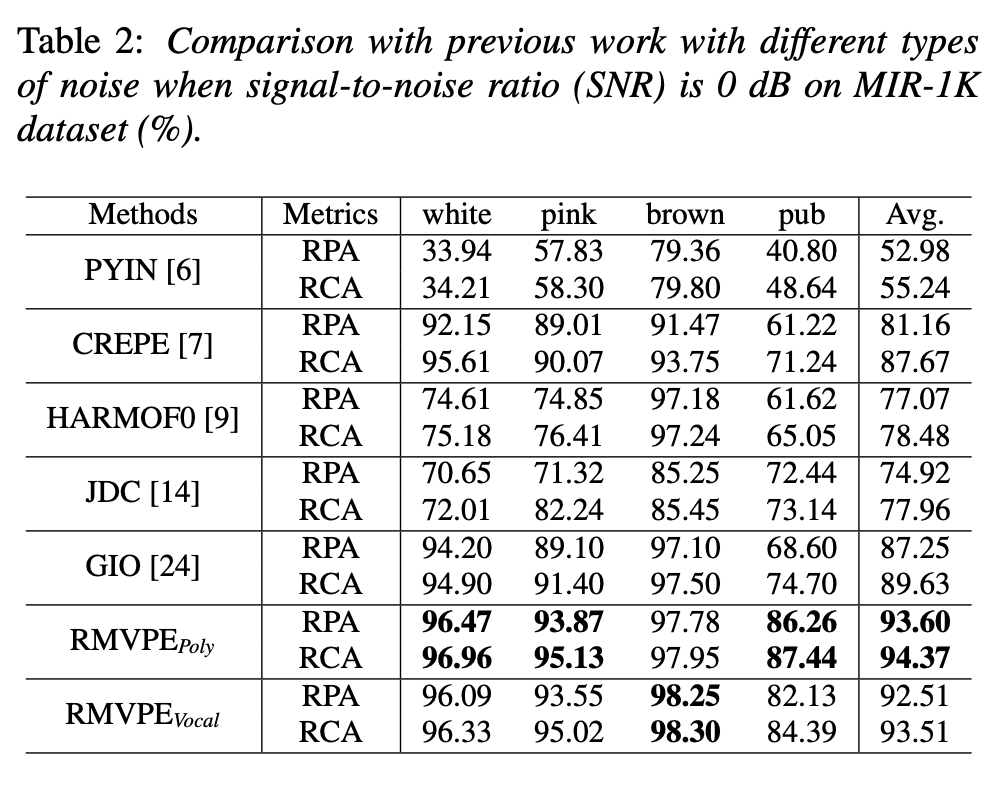
ノイズ耐性もチェック(表2)。
は伴奏なしのボーカルのみで学習したモデル。
GIOという既存手法と同じ設定なので、論文からGIOの結果も引用。
ノイズ強度に対しての耐性

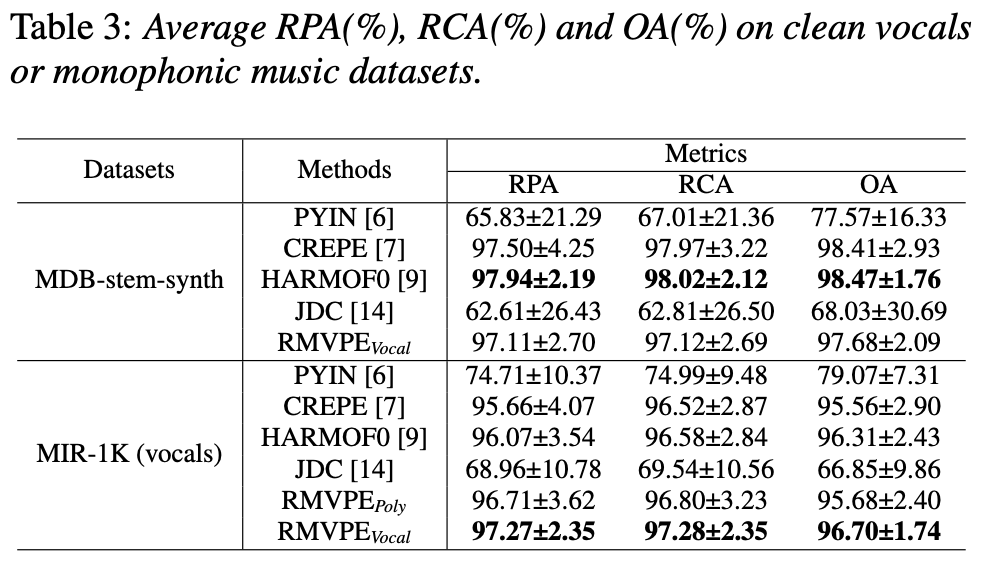
ボーカルのみの音源に対しての精度評価(表3)。
一部実験で負けているが全体としては高精度。
[論文メモ] SNAC: Speaker-normalized affine coupling layer in flow-based architecture for zero-shot multi-speaker text-to-speech
zero-shot multi-speaker TTSのための話者を明示的に正規化するSNAC layerの提案
既存のzero-shot multi-speaker TTS (ZMS-TTS)では話者専用のエンコーダを用意してstyle transferの要領で変換することが多い。
またそのときにはFastSpeech系のfeed-forwardモデルが採用されやすい。
最近話題のVITSのようなflow-basedな手法ではreverse flowが必要なのであまり検討されていない。
そこで話者情報を正規化するaffine coupling layerを提案。
手法
affine coupling layerは入力を2つに分けて片方を普通の入力、片方をアフィン変換のパラメータの計算に用いる。
入力を、
として
これで得られたと
]をconcatして出力とする。
逆変換は以下でできる。
アフィン変換のパラメータがわかっているので単純に正規化するだけ。
このaffine coupling layerについて話者情報を条件とし、話者情報について明示的に正規化したい。ここで話者情報
は固定長の埋め込みベクトルとする。
戦略としては入力される話者に依存した特徴からの情報を抜き取るように正規化し、逆変換時に指定した話者の分布になるように。
そこで speaker-normalized affine coupling (SNAC) layerを提案。
正規化時、シンプルにを使って入力を正規化を行う。
を
に置き換えただけ。
逆変換も同じ感じで
log-determinantの計算も普通にできる。
SNAC layerのイメージが図1

実験・結果
ベースのモデルはVITSでデータセットはVCTK。
VCTKの109話者のうち、11人をin-domainの、LibriTTSから20人をout-of-domainのテスト話者として利用。
話者埋め込みにはスペクトログラムを入力としたconv2dとGRUを積んだネットワークを利用。出力は256次元の埋め込み。
これをreference encoder(REF)とする。
以下3つのベースラインを用意
Baseline+REF+ALL :REFを利用したVITS
Baseline+REF+FLOW :Flowとduration predictorにのみ話者埋め込み(REF)を利用。generatorは埋め込みを利用しない
Baseline+PRETRAINED+FLOW :Baseline+REF+FLOWにおいてREFを事前に学習し固定して利用
上記3つのベースラインのflow layerをSNACに置き換えてそれぞれ比較。
評価指標はMOSと話者類似度MOS(SMOS)と話者埋め込みのコサイン類似度(SECS)
話者埋め込みの計測は SpeechBrain toolkitを利用。
結果が表1。MOS、SMOSは高いがSECSが既存手法(YourTTS)より小さい。
YourTTSは話者埋め込みが近くなるような学習をしているかららしい。
正直、既存のVITSと大きな差がなく見える。
話者埋め込みは学習済みではなく、同時に学習したほうが良さそう。特徴量のドメインシフトの問題か?

所感
手法自体はシンプルでそこそこ納得感もある。実験結果的に悪くはなさそうだが、劇的な改善もなさそうに見える。
generatorが話者非依存にできそうなのは良いかも。
実際試した感じあまり効果は感じなかった。が曲者でこいつのせいですぐにnanになることが多かった。
非公式の実装ではを利用しておらず、気持ちはわかる。
[論文メモ] Class Adaptive Network Calibration
CVPR2023
クラス不均衡なデータを効率的に学習する手法を提案。
クラスの分布が不均衡・裾が長い場合にDNNは自身過剰な予測を出すことがある。これを調整することをここではキャリブレーションと呼ぶ。
このキャリブレーション方法としては主に2種類ある。
1つ目は事後処理でキャリブレーションする方法で、検証セットを使ってlogitを調整するパラメータを設定する。低コストで効果的だが学習したモデルや検証セットの影響を受けやすい。
2つ目は学習中に同時にキャリブレーションを行う方法。メインの目的関数に加えてキャリブレーションの目的関数も追加するというもの。Label SmoothingやFocal lossなんかがこれに該当する。
これらはlogit距離を0に近づけるペナルティ項として定式化できる() nOTE
ただこれにも問題があり、
1) 各クラスの重みが同じで難しいクラスに対応できない
2) 重みの調整は適応的ではなく事前に行われるため、最適な結果が得られない
これらをなんとかするための拡張ラグランジュ乗数アルゴリズムに基づいたlabel smoothing手法、CALS-ALMを提案。
手法
をサンプル数、サンプルを
、ラベルを
とするとデータセットは
になる。なおクラス数は個。
パラメータを持つDNNを
とするとlogitは
。
softmaxで確率にすると。
クロスエントロピーlossは
となる。なお、基本的にはone-hotエンコーディングなことに注意。
既存のMargin-based Label Smoothing (MbLS)
Margin-basedな手法のlossは
の形式。なお。
CE lossに追加しマージンの制約を設けた感じ。マージンの制約は各サンプルについてのlogitの各値と最大logitとのマージンがm以下になるようにする。各クラスのlogit同士にあまり大きなマージンができないようにするという感じ?
これも非常に強力なキャリブレーションだが、すべてのサンプル・クラスに対して均一のペナルティを与えることになり最適ではない。
最適にするなら以下の式のようにをサンプル・クラスについて分ける必要がある
ただし。
最適化の観点からははラグランジュ定数で、最適なパラメータ
とのペア、
が存在する。
当然だがImageNetのようなサンプルもクラスも巨大なデータセットや、ピクセルにクラスを割り当てるセグメンテーション問題を考えればこの最適化は現実的ではない。
そこでサンプルレベルのペナルティを緩和し、クラスレベルとする。
ただし、
それでもImageNetではで少々複雑。
Class Adaptive Network Calibration
が大きいときでも適応できるためにAugmented Lagrangian Multiplier(ALM)法 (拡張ラグランジュ乗数法)を利用する。
一般的なALM法はラグランジュ関数にペナルティ項を追加したもので、最適化の条件を満たすまで最適化とラグランジュ乗数とペナルティ項の係数を更新を繰り返すアルゴリズム。ここでは詳しくは省略。
j回目のラグランジュ関数は以下の式。
は制約。
ペナルティ項と制約を合わせたペナルティ関数をここではとし以下を満たす。
と各パラメータの関係を図にしたのが図2

ALM法は凸最適化で非凸のときは保証が無いが、非凸でも効果的なのがよく知られている。にも関わらずDNNの文脈ではほとんど検討されない。
そこでALM法をキャリブレーションに利用する。
なお。
ペナルティ項を足し合わせるのではなく平均化し、マージンで制約を正規化し、最終的なloss関数を得る。
ただ、すぐに過適合してしまうので各エポック毎検証データを使ってラグランジュ乗数を更新する。
については制約が満たされておらず、かつ制約項の値が現象していない場合に
倍する。
既存研究と実際に実験した結果から、として以下のPHR関数を利用する。

実験・結果
データセットはTiny-ImageNetとImageNetとImageNetLT。
ImageNet-LTは裾が長い分布をしている。
またセグメンテーションタスクとしてPASCAL VOC2012、NLPタスクとして 20 Newsgroups。
評価指標としてよく使われているExpected Calibration Error (ECE)を採用。
はbinの数、
はテストサンプル数(ここでは15に固定)、
は
番目のbinの予測確信度、
は
番目のサンプルのacuuracy、
は
番目のサンプルの平均確信度。
またAdaptive ECEも。
先程提案した手法をCALS-ALM、の更新を以下のヒューリスティックにしたものをCALS-HRとする。

画像分類の結果。提案手法がキャリブレーション指標では優れている。

ablationとして学習中のの変化とペナルティ関数
とマージン
の影響をグラフ化(図3)。

はじめは精度を上げるためにECEもも上昇するが、途中で調整が始まりECE、
ともに減少し始める。
ペナルティ関数とマージンについてはPHRが最もよく、が良さそう。
セグメンテーションとNLPの結果は表2、3を参照。

ただ、この手法の制限として学習データセットと同じ分布の検証データセットが必要なこと。
検証データがi.i.dのときについては今後検証予定だそう。
[論文メモ] Voice Conversion With Just Nearest Neighbors
INTERSPEECH2023
k-NNを用いたシンプルなany-to-anyな声変換の提案
最近のVoice Conversion(VC)は精度を出すために手法複雑になっており、再現や構築が難しい。
高品質なVCを実現するためにそれほど複雑な必要は無いのでは?ということでk-NN回帰によるVCを提案。
手法
手法名はk-NNを用いたVCなのでシンプルに k-nearest neighbors voice conversion (kNN-VC)という名前。
kNN-VCは3つのコンポーネント(encoder、converter、vocoder)から成る。
音声の生成フローは3段階
1) encoderを使ってソース音声とターゲット音声を特徴量化
2) ソース音声とターゲット音声を入力としてconverterが変換した特徴量を生成
3) vocoderが音声波形を合成
手法の全体像は図1参照。

Encoder
Encoderとしては既存の学習済みモデルを利用し、fine tuning等の追加の学習はしない。
学習済みモデルとしては音素分類のスコアが高いものを利用する。
この学習済みEncoderを利用してソース音声とターゲット音声から特徴ベクトルを取り出す。
ソース音声から取り出した特徴ベクトル列をquery sequence、1つ以上のターゲット音声から取り出した特徴ベクトルの集合をmatching setと呼ぶ。
matching setは集合であり順序関係はない。
k-nearest neighbors matching
query sequenceの各特徴ベクトルに近い特徴ベクトルをmatching set からk-NNで検索し置き換える。
既存モデルで得た特徴ベクトルは音素が似ていると近い性質があるので、置き換えることでコンテンツを保存したまま話者を変換できる。
またk-NNはノンパラメトリックな手法で追加の学習も不要で再現がし易い特徴もある。
Vocoder
特徴ベクトル列を音声波形にするためのものでここではHiFi-GAN V1を採用する。
普通のVocoderはスペクトログラムから音声波形を生成するが、ここでは特徴ベクトル列から音声波形を生成するため学習が必要になる。
Prematched vocoder training
vocoderの入力は学習時は音声から生成した特徴ベクトル列だが、予測時は変換した特徴ベクトル列でありドメインが異なる。
また、変換した特徴ベクトル列はmatching setから選出されるため時間的に連続の保証はなく、これをそのまま音声にしてもアーティファクトが出る。
そこでmatching setで置き換えた特徴ベクトル列にロバストにするためにvocoderの学習を工夫する。
学習に使うquery sequenceと同じ話者で作成したmatching setを使って特徴ベクトル列を変換し、これを入力として学習を行う。
これにより時間的な不連続性に対してロバストになる。
実験・結果
学習済みEncoderとしてWavLM-Largeを採用する。
どの層から特徴ベクトルを取り出すかは事前実験の結果6層目とした。後半の層だと音素分類は良いがピッチや話者性の再現が難しい(既存研究あり)。
1つの特徴ベクトルは16kHzの20msに相当。
k-NNについてはとし、距離はコサイン類似度を用いた。
vocoderの学習にはLibriSpeechの学習データセットを利用。
テストは同じくLibriSpeechのテストセットの一部を利用。
他手法との比較結果が表1。

ほぼすべての指標についても提案手法が既存手法を上回っている(MOSがなぜが太字...)。
また、話者埋め込みを利用していないので言語等の縛りが無い。
学習は英語で行っているが、ドイツ語話者から日本語話者への変換についても試してみたデモが公開されている。
ablationとしてprematched vocoder trainingの効果とmatching setの大きさ(ターゲット音声の長さ)について調査。
結果が図2。同じmatching setのサイズならprematched vocoder trainingしたほうが全てにおいてよく、matching setも基本的に大きい方が良い。
また、ターゲット音声が30sより少ない場合は既存のany-to-any手法に劣る。

所感
非常にシンプルなany-to-anyで面白かった。
ターゲット話者の音声集合で置き換えは正直誰でも思いつきそうだったが、案外珍しい?
WavLMができたからこそなのだろうか?
これをEncodecのVQでやってみたらどうなるのか気になる。EncodecのVQはコンテンツ特徴と音響特徴に別れているのでうまいこと転写できないだろうか?
[論文メモ] THE SINGING VOICE CONVERSION CHALLENGE 2023
歌声変換チャレンジ
概要
2016年から開始されたVoice Conversion Challenge(VCC)は対象話者への声変換をベース目標としてやってきた。VCC2020では自然性についてはまだ人間レベルではないにしろ正解話者との類似度は非常に高くなった。そこで音声変換ではなく、より難しい歌声変換を目標としSinging VCC(SVCC)に変更した。
歌声変換が声変換より難しいと考えられる理由は
1) 普通の発話と異なり様々なピッチ、音圧、表現や歌唱のスタイルがある
2) ピッチについては曲の音符に従いつつも、歌い方は歌手によって異なるのでそれらの情報を適切に扱う必要がある
簡単な結果の概要が図1
参加者と手法概要
参加者は以下の表2の24チーム。
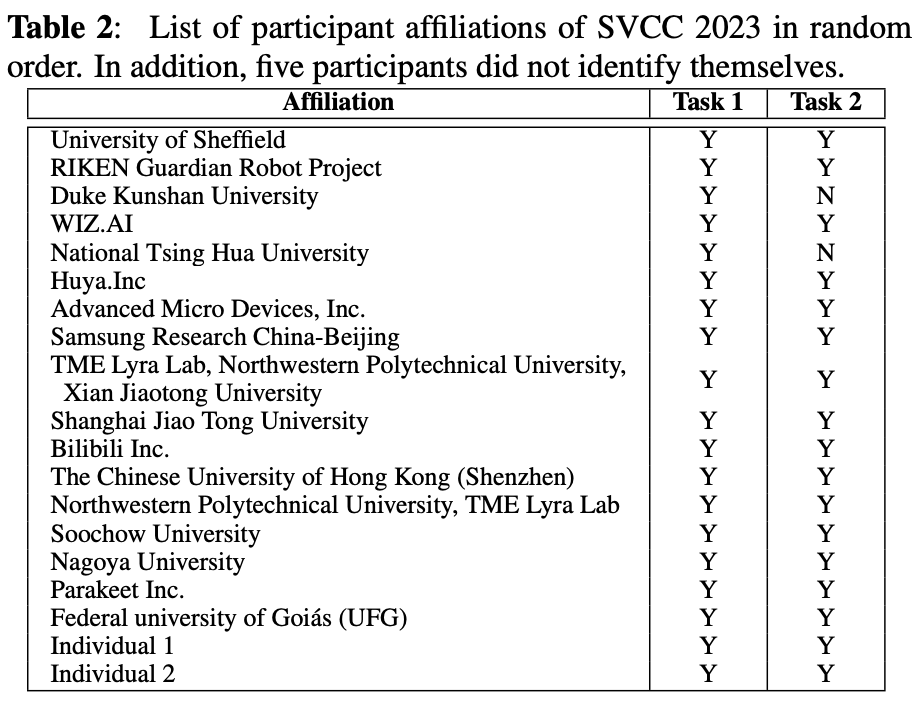
ベースラインの手法としてDiffSVC(B01)とDecomposed FastSVC(B02)を導入。
手法をVAEの有無、コンテンツ特徴、ボコーダについて分類してみたのが表3。
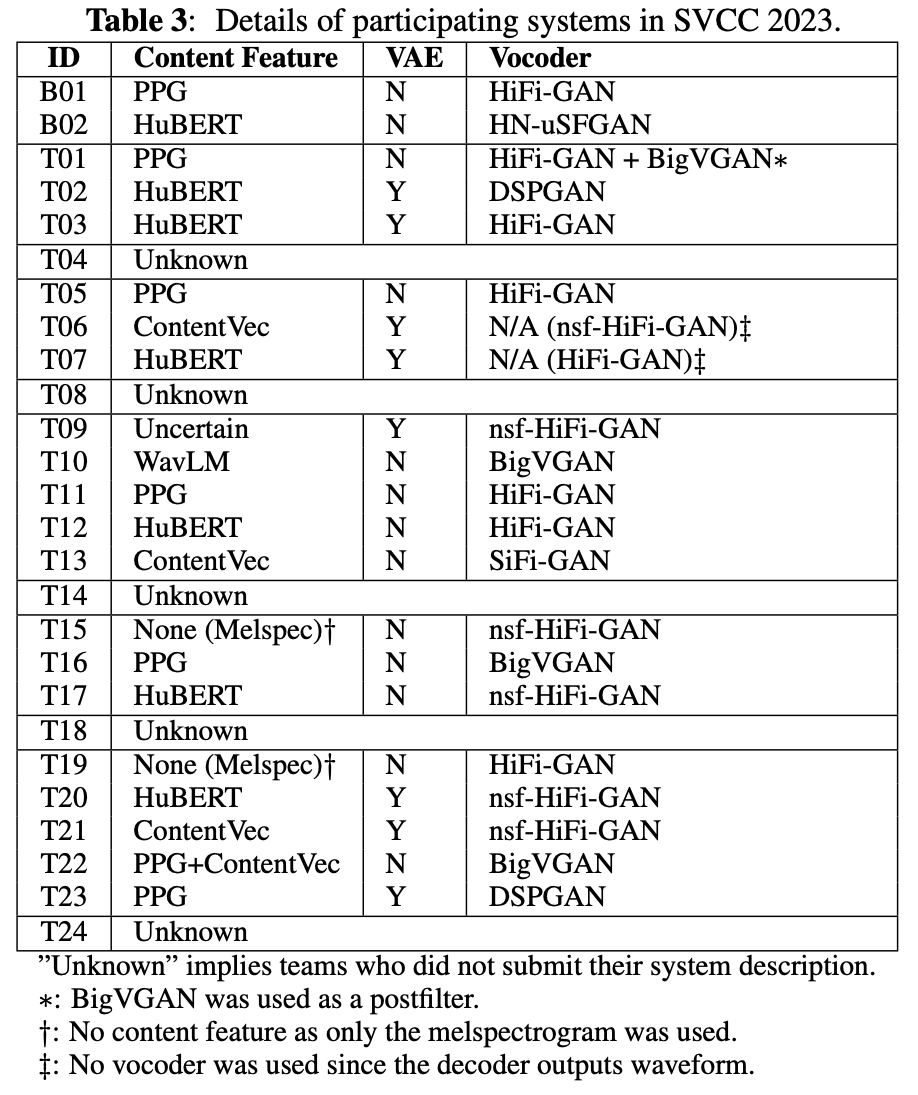
コンテンツはContentVec、HuBERT、PPGが多そう。
VAEは多くないが、トップに食い込んだ手法はVAEを採用している。
ボコーダはHiFi-GANやその派生が多い。自然性トップの手法はDSPGANだったが、サンプルが少なくDSPGANが自然性向上に有効かは判断できない。
評価と結果
評価指標は自然性と類似性。
評価者はAmazon Mechanical Turkではなく、2つの企業から日本語と英語のリスナーを募集した。70万円かかったらしい。
自然性
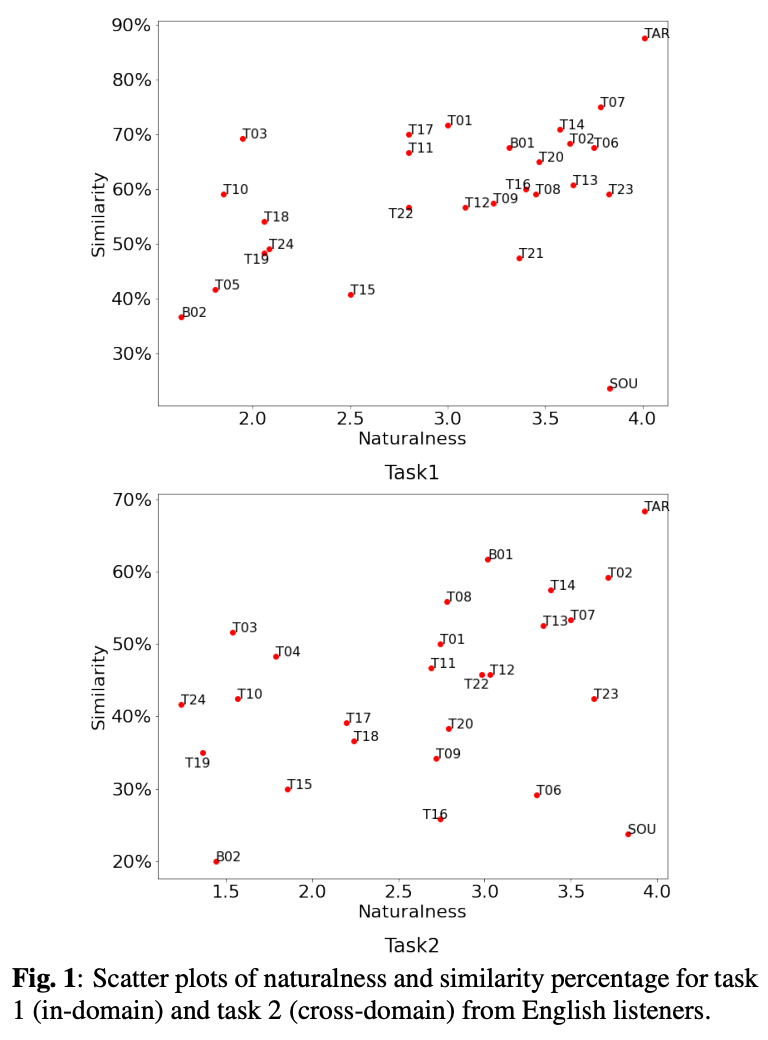
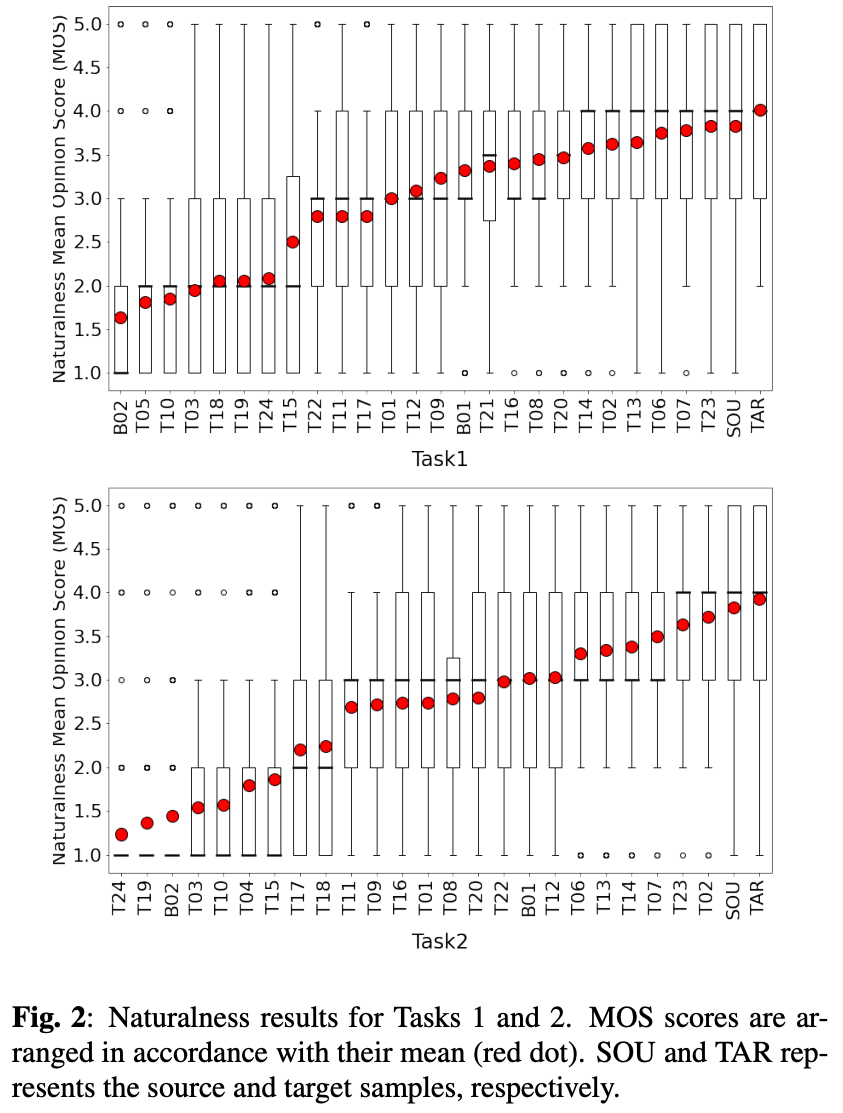
図2が自然性の結果。
タスク1ではT23がトップでタスク2はT02がトップ。どちらのタスクでもトップは同じ感じ。
どの手法もソースやターゲットを超えられなかった。
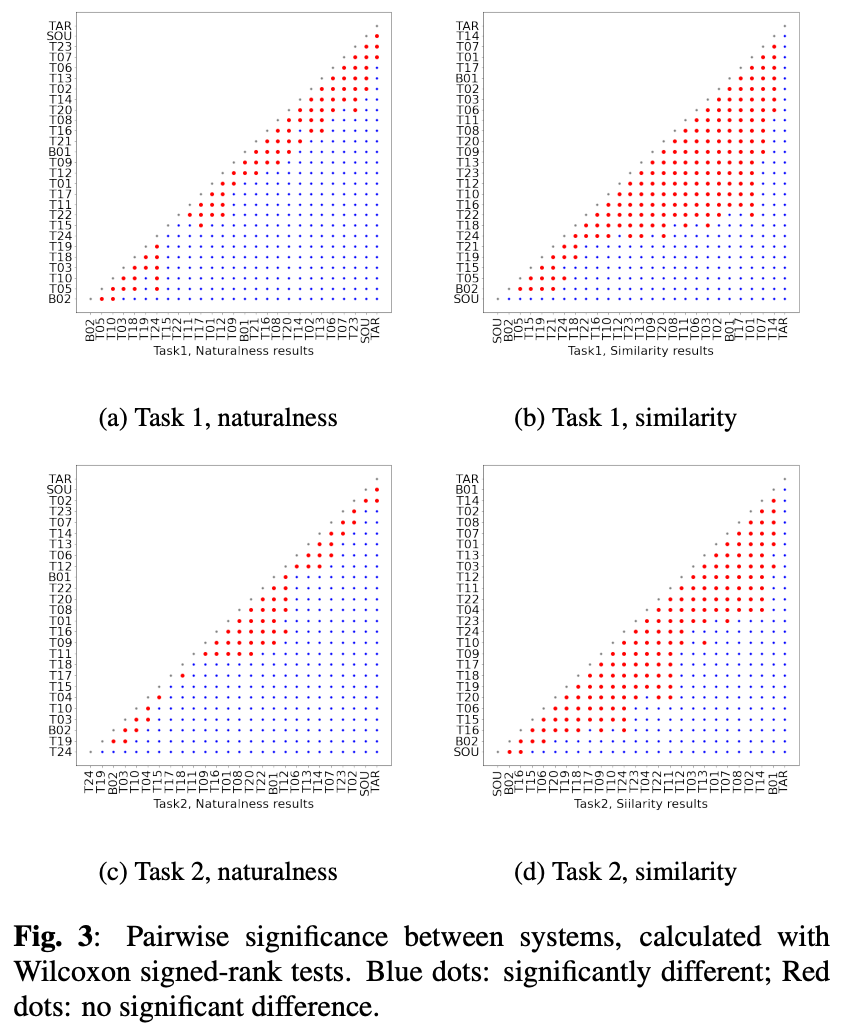
ただ図3(a)と(c)から、T23、T07、T02については実サンプルと優位な差がなく、トップシステムについては人間レベルの自然性と言えそう。
また、タスク2はスコア3.0を超えるのが8チームしかなく、タスク2のが難しいというのが確認できた。
類似性
結果が図4。ベースラインB01が上位に来ている。
トップの手法とターゲットには0.4ポイントも開きがある。
図3(b)(d)を見ても、現状では類似性はまだ改善の余地がありそう。
また、類似性についてもタスク2のが難しいことがわかる。
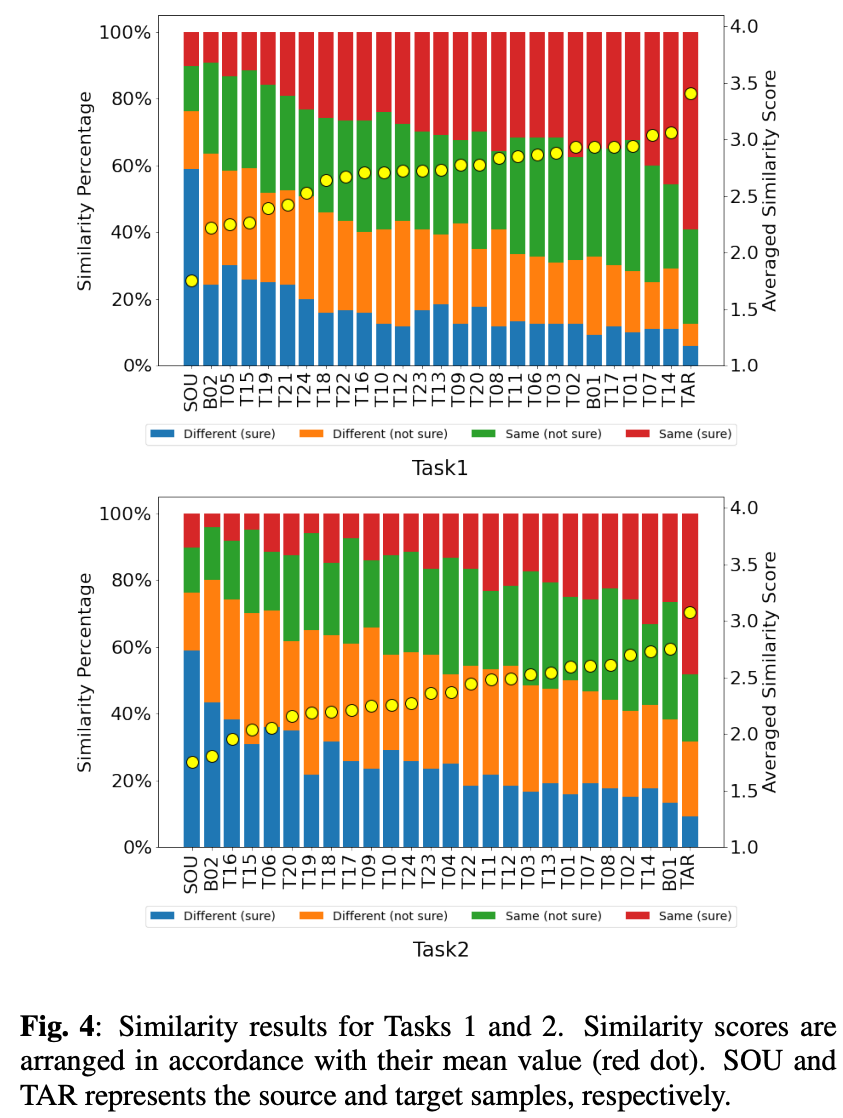
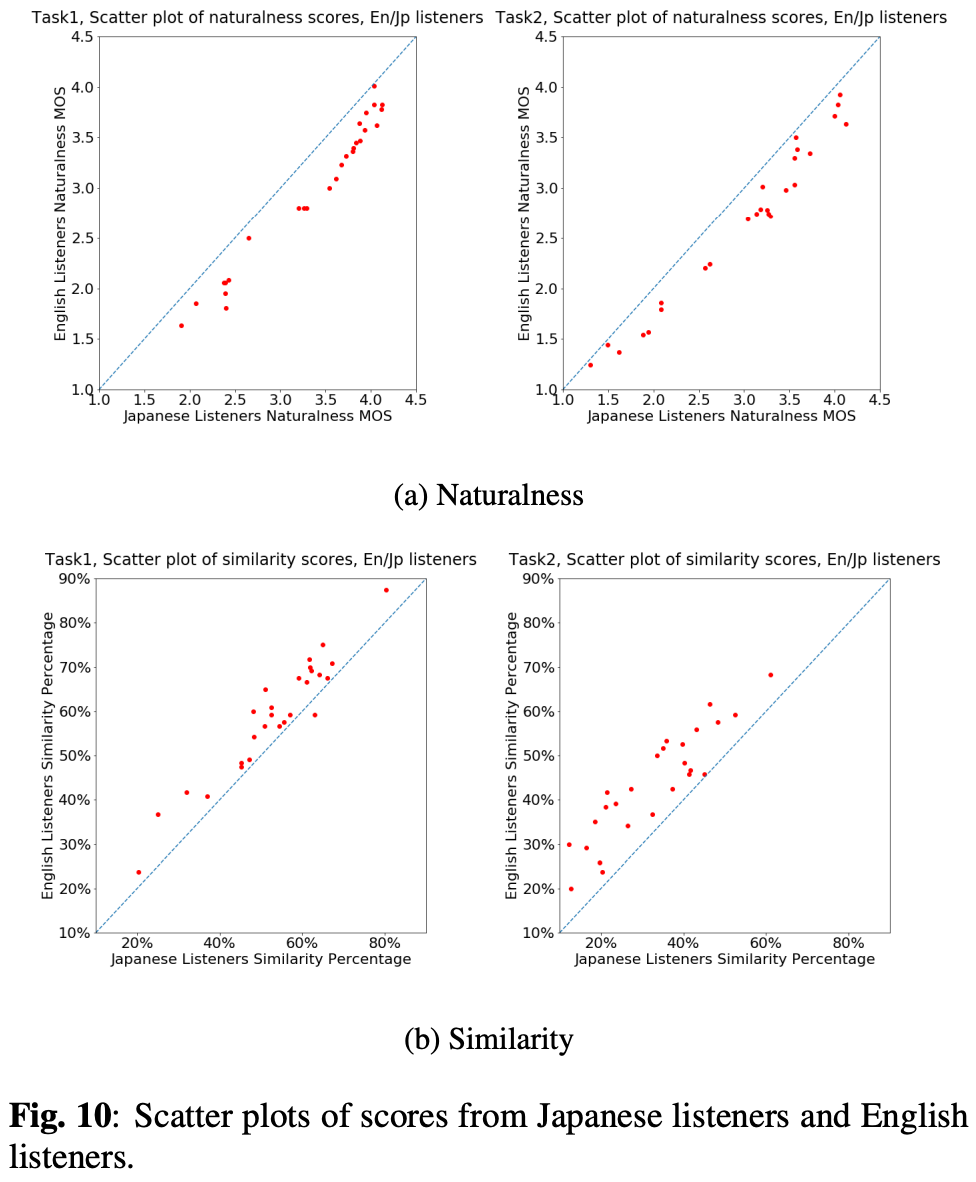
日本語リスナーと英語リスナーの判断の違い
今回は英語音声なので日本語リスナーにとっては非ネイティブとなる。
タスク1の自然性、類似性、タスク2の自然性、類似性について、英語リスナーとの相関係数を計算するとe 0.985、0.975、 0.985、0.924だった。
図10が散布図相関係数は大きいものの日本語・英語リスナーで傾向の違いが見られた。
- 日本語リスナーは自然性に高スコアをつける傾向
- 英語リスナーは類似性に高スコアをつける傾向
その結果日本語リスナーは変換した歌声を区別できない。
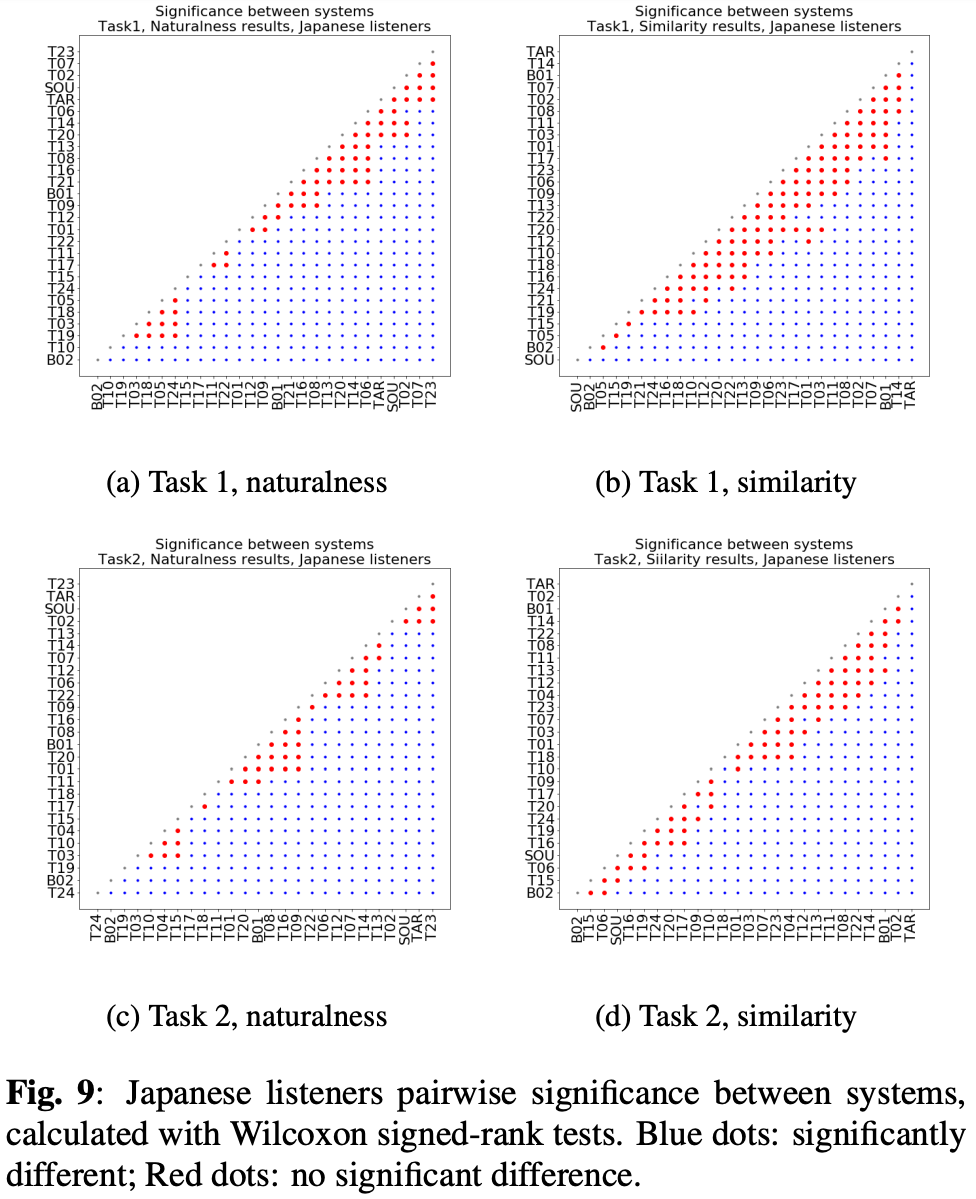
また、スコアの数が多いほどシステム間の統計的に有意な差異を観察しやすくなるという仮説を立てていたが類似性と自然性で異なる結果が得られた。
図3は英語リスナーについて、図9は日本語リスナーについての結果。
類似性についてはスコアが多いほど差が観測できたが、自然性は少ない英語リスナーで十分に信頼性のある結果が得られた。
自然性についてはスコアの数だけではなく、他の要素(文化や個人の趣向)の影響がありそう。
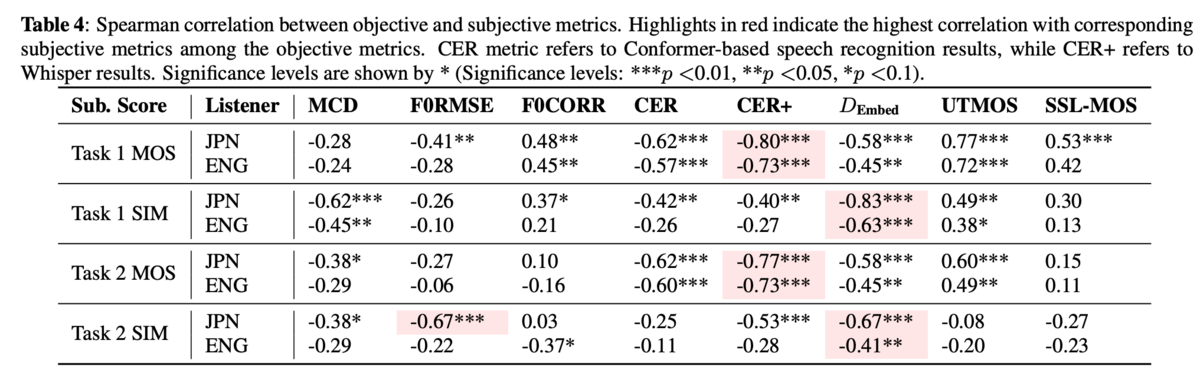
客観評価と主観評価の関係
mel cepstral distortion (MCD)、F0、歌詞(CER、CER+)、話者類似性()、MOSについて比較。
- スペクトログラムやF0は客観評価と主観評価に優位な相関はない
- 歌詞については相関がありそう
- 埋め込みによる話者類似性の評価は統計的に優位性を示したが、ネイティブとの類似性評価には微妙
- 音声コーパスで学習したMOS予測モデルでも中程度の相関がありそれなりの汎化能力
所感
音声変換ではなく歌声変換でのチャレンジ。普通の発話では出てこないピッチがあるので確かに難しそう。
リスナーの言語による評価の違いはわかる気がする。英語はまだしもあまり聞かない中国語のサンプルとか聞いても全く違いが分からなかったりする。
so-vits-svcがそこそこ使われているのもなるほどとなる。日本ではなぜかRVCが流行っているが海外ではやはりso-vits系か。
VAEの重要性が再認識できた。
[論文メモ] CYFI-TTS: CYCLIC NORMALIZING FLOW WITH FINE-GRAINED REPRESENTATION FOR END-TO-END TEXT-TO-SPEECH
ICASSP2023
https://ieeexplore.ieee.org/document/10095323
VITSの改良
VITSはE2EなTTS(VCもできるけど)モデルでテキストから複数話者の発話を生成できるが、テキストが同じでも発音は人によって異なるためここに情報のギャップが発生する。それをなんとかしたいというお気持ち。
手法
テキストと音声のギャップを解決するためにcyclic normalizing flow(CNF)とtemporal multiresolution upsampler(TMRU)を使ったCyFi-TTSを提案。
CyFi-TTSのCyはcycleから、FiはTMRUがfine-grained representationsを取得するもので、そのfineから(なんでじゃ)。
全体像は図1参照

TMRU
TMRUはprior(テキスト)からより細かい特徴を得るためのモジュール。これによって音声とのギャップを埋める。
TMRUとCyFI-TTSのアーキテクチャは図2参照。

アライメントを、prior encoderの出力を
とする。
はテキスト(音素)長、
は音声の長さ、
は特徴量の次元。
アライメントをガウシアンで平滑化しにし、それをtex: \boldsymbol{z}_{c}]に適用することで
を得る。
このままだと音声長が合わないのでアップサンプリングを含むブロックを回適用することで徐々に大きくし特徴量間のギャップを減らす。
各ブロックはアップサンプリングとカーネルサイズの異なるconv、そしてsnake1dを持つ。
snake1dはBigVGANで提案されたモジュールで以下のsnake functionを使った1dのconv。
は学習可能なパラメータ。
Cyclic Normalizing Flow
Cyclic Normalizing Flow(CNF)は学習のlossの1つ。
VITSは発話からのフレームレベル特徴
からフレームレベルの発話
を生成する学習時のメインフロー(図2(a)の左側)と実行時に利用するテキスト
から特徴
を生成するフロー(図2(a)のTRMUを除く右側)の2つからなる。
学習時、normalizing flow(NF)により情報を落としたと
を近づけるためにKLダイバージェンスを利用する。
]
実行時はNFのreverse flowでを
にしてHifiGAN部分に入力しTTSを実現する。
しかし、NFはは学習しているが、
は学習していない(結果的にできるが)。
そこでテキストからの特徴についてNFを通したcycle consistencyを導入する。
をNFにreverse flowした
を再度NFで得られた
が元の
に一致するようにするKLダイバージェンス。
NFをとして
]
これがCNF。
ただよくわからないのがはNFなので、
と
は一致するのでは?ということ。
ちょっと意味がわからない。
他のlossはVITSと同じで、最終的なlossは以下

はdurationの、
はGANの、
は再構成、
はfeature-matchingのそれぞれloss。
は係数。
実験・結果
学習用データセットはLJSpeechでサンプリングレートは22050Hz。
比較対象はVITS、PortaSpeech、BVAE-TTS。
学習データセットの内挿データセットについての結果が表1

CERやWERはGT等に劣るが、MOSはGT相当。他手法よりはどの指標も良い結果。
外挿データセットについての結果が表2。

他手法よりはどの指標も良い結果。
VITSとのCMOS評価

スペクトラムの可視化結果が以下の図4。

VITSに比べ高周波の構造がきれいに見える。低周波はあまり変わらないように見える。
ablation studyとしてTRMUとCNFの効果を確認。

これを見る限りどちらも性能に貢献している。
所感
TRMUはそれなりに理解できる。テキストからの特徴をVITSのようにただ並べるとテキストの接続部分や終端のフィードアウト等が上手く表現できなそう。TRMUほどでは無いが平滑化だけでも効果がありそう。
CNFは正直意味がわからない。NFなのに行って帰って来くると値が異なるとはこれ如何に。Githubでも質問が飛んでいる(2023/6/9)。
github.com
Dropoutの可能性を聞いている。確かに可能性はありそう。
ablation studyでもCNFの効果が示されているのでなにかはありそう。
また少し似た手法としてNaturalSpeechがあり(2じゃないほう)、これについて触れてはいるが比較に入れてないのが少々気になる(ソースコードは公開されてる)。