[論文メモ] ZERO-SHOT TEXT-TO-SPEECH SYNTHESIS CONDITIONED USING SELF-SUPERVISED SPEECH REPRESENTATION MODEL
NTT
ICASSP 2023
自己教師あり学習(SSL)による特徴を条件としたzero-shotのtext-to-speech(TTS)の提案
既存手法の多人数話者TTSでは少量データでのfine-tuningが必要で計算コストや時間がかかる。
既存のzero-shot TTSでは話者認識ベースのd-vectorやx-vectorを使う方法や同時にエンコーダを学習してその埋め込みを利用する2タイプがある。
話者認識ベースは未知の話者にロバストだが、リズムなどの話者重要な個性が反映できない。
同時にエンコーダを学習するタイプは学習データがTTS用で規模が比較的小さいので未知話者に弱い。
SSLモデルを使ってこれらの問題を解決したいというお気持ち。
手法
アーキテクチャ全体像は図1参照。
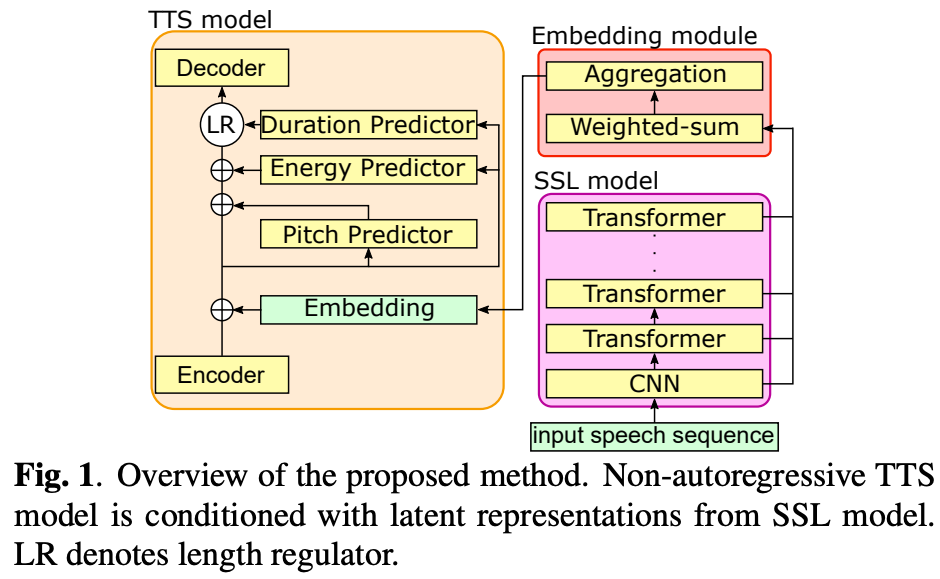
FastSpeech2のような自己回帰では無いTTSとSSLモデル、埋め込みモジュールの3つからなる。
他のzero-shot TTSと似た構造をしているが主な違いは埋め込みをx-vector等を使わずSSLモデルから取得しているところ
SSLモデル
発話から話者埋め込みを取得する。
発話をSSLモデルに入力して各レイヤーから中間特徴を取り出すことでフレームレベルの特徴ベクトルを取得する。
をレイヤー
の特徴量の次元数、
をレイヤー数、
をフレーム数として
の特徴量ベクトルを得る。
SSLモデルとしては主にwav2vecとHuBERTを利用する。
この特徴量は可変長なので次の埋め込みモジュールで固定長に変換する。
Embedding module
SSLモデルにより得られたフレームレベル特徴を固定長に変換する。
まずweighted-sumモジュールにより、各レイヤーに対応する重み
をかけてsumするをすることで
の特徴に集約する(各レイヤーの次元数
は同じなのでsumできる)。
固定長にするために2種類の方法を試す。
- average pooling
- LSTM + soft-attention
average poolingはそのままでフレーム方向についてaverage poolingする。
LSTM + soft-attentionではLSTMに通したあとにattentionを行い集約する。
average poolingはすべてのフレームが同じ重みとして集約するが、attentionは重要なフレームに重みを付けての集約できるのでこちらのほうが有効そう。
Separate conditioning
自己回帰ではないTTSモデルにおいてduration predictorと他の音響predictorは基本的に独立している。
そこでconditionについても duration predictorと他のpredictorで分ける。
これによりduration predictor側ではリズム等の特徴を、他のpredictor側では音響特徴を捉えやすくなった。
また、リズム等の特徴が分離したので、リズムだけ他話者等も可能になる。
conditionを分離したアーキテクチャは図2参照。

実験・結果
データセットは社内製の1083話者の日本語のデータセット。話者は声優やアマチュア、ニュースキャスターなど様々。
サンプリングレートは22.05kHz。
vocoderはHiFI-GAN。
SSLモデル(wav2vec, HuBERT)はfairseqを利用して新しく学習。このときはCSJデータセットを利用。
評価指標は
- GTのdurationを使って生成したメルスペクトログラムでのmean absolute error(MAE)
- 音素のdurationのroot mean square error(RMSE)
data-parallelとnon-parallelは参照発話をテキストと対応する発話にするか否か。non-parallelだと同じ話者の異なる発話を参照にする。
比較する既存手法はx-vectorでのTTS。
SSLモデル、集約方法、アーキテクチャ毎、data-parallelとnon-parallelの実験結果。

総合的にはHuBERT + LSTM + separateが良さそう。
ただ、提案手法のほうが既存手法に比べparallelとnon-parallelとの差が大きいのは少々気になる。
non-parallelでの主観評価(MOS)

話者の類似性は提案手法のがかなり良さそう。
リズムの変更

x-vectorは反映できていないが、HuBERTは反映できてそう
weighted-sumの重みを可視化したのが図3

0番目(convの直後)の特徴に重みが集中している。つまりスペクトログラムに近いところから話者情報を取得しようとしている。
それに対して分離したアーキテクチャでは音響特徴のSpec.はcommonとほとんど同じ感じだがDur.はcommonと異なる。
Spec.とDur.で必要な情報が異なるのでアーキテクチャを分けるのは正解っぽい。
学習に使用する言語とモデルサイズによる違い。SSLはパブリックに利用可能なLibriSpeechで学習されたSSLモデルを利用。

CSJで学習したSSLを使ったのと比較しても大きな差は無いことから、SSLで利用する言語はなんでも良さそう。
図3でも音響特徴はスペクトログラムに近い浅いレイヤーに重みをおいていることからも言語依存は少なそう。
所感
SSLモデルを話者情報にしたモデルでそこまで感動的ではなかった。実験結果の比較がいくつかあったのは学びがあった。
HuBERTはMFCCを教師に使っていて音響情報は少なそうだがそれでも良いのか?
HuBERTを使ってるとはいえ、結局浅いレイヤーから特徴を抽出しているので目的関数はあまり関係無いのかもしれない(ContentVecでも同じことができそう)。HuBERTの最終層付近だけしか利用できないとかだと話は変わりそう。実験してほしい。
提案手法は既存手法に比べparallelとnon-parallelの差が大きかったのも気になる(表1)。
ここの差が出るということは、参照音声の話者ではない情報に大きく依存しているということなので安定性が少々低そう。
[論文メモ] Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
Google Research
比較的少量のラベルありデータで学習できるmulti-speaker TTSの提案

TTSを学習するには音声と発話のペアデータが大量に必要でペアデータはコストが高いため少量しか手に入らない。
それに対して音声のみのデータは大量にあるので、それを使ってTTSの学習コストを下げたいというお気持ち。
提案手法
TTSのタスクを"reading"と"speaking"に分割して考える。
"reading"はテキストをセマンティック特徴に変換するseq2seqタスク。
"speaking"はセマンティック特徴を音響特徴に変換するseq2seqタスク。
この2つのseq2seqを組み合わせた SPEAR-TTSを提案。SPEARは“speak, read and prompt”から(最近のGoogleの略名意味がわからん)
SPEAR-TTSはAudioLMの拡張
AudioLMは言語モデルと音声デコーダからなるモデルで
という形。
SPEAR-TTSの大まか仕組みとしては以下の2つのステージからなる
ステージ1) 入力されたテキストをセマンティックトークンに変換
ステージ2) セマンティックトークンを音響トークンに変換
各トークンの意味は以下
セマンティックトークン
テキストよりは音声的な特徴を捉えたもので、コンテンツを提供するトークン(音素等に近い?)。
話者情報等の音響の詳細情報は取り除かれている。
w2v-BERTにを学習して得られた特徴をk-meansでクラスタリングし、それらのセントロイドを利用することで離散的なトークンとする。
ステージ1
Transformerを使ってテキストをセマンティックトークンに変換するseq2seqタスクを学習する。
利用するのはテキストと音声のペアデータ。セマンティックトークンは音声から抽出するのでテキストとセマンティックトークンのペアデータになる。
Transformerの学習には大量のデータが必要で通常のテキスト音声ペアデータではデータ不足である。
そこでpretrainingとbacktranslationを導入し解決する。
Pretraining
既存研究に基づいて、デノイジングを行う(一部欠けたトークン列を入力して元のトークン列を予測するタスク)。
ノイズの方法はいくつかあるが、個々のトークンを一定の確率で独立に削除するのが効果的だった。
入出力はセマンティックトークン。
これで事前学習したものをステージ1の学習で利用する。このときデコーダとエンコーダの上位層を固定してfine tuning。
ステージ1で学習したいのはテキスト2セマンティックで、Pretrainingではセマンティック2セマンティックなのでこういう固定の仕方かと。
Backtranslation
テキストから音声を生成する場合、生成されるパターンはアクセントや声質など複数存在するため難しい。
そこで音声からテキストを生成するBacktranslationモデルを学習する。
これにより大量の音声のみのデータからテキストを生成しパラレルデータを生成できる。
Backtranslationモデルの学習はPretrainingで学習したのモデルのエンコーダを固定して行う。
ステージ1の学習の全体像
全体像は図2参照

- まずPretrainingにより図下部のモデルPを得る
- モデルPをコピーしてエンコーダを固定する
- 音声からテキストを生成するBacktranslationモデルを学習する
- Backtranslationモデルを使って音声のみのデータから擬似的なテキスト音声ペアデータを作成する
- このテキスト音声ペアデータを使ってテキストを使ってモデルPをfine tuningする
ステージ2
ステージ2ではセマンティックトークンを音響トークンに変換する。
主に音声のみの巨大なデータセットを利用する。
ここではセマンティックトークンで表現されていない音響情報をデータの分布から学習することになる。
ステージ1と分離したことでステージ1が単一話者で学習していたとしても、ステージ2で多様な音声を生成できるらしい。
AudioLMには以下の2つの特性がある
この特性を利用して音声の制御を行う。
ステージ2の学習プロセスは以下の図3を参照

- 学習サンプルを選び、そこからオーバーラップなしで2区間を取り出す
- 各区間についてセマンティックトークンと音響トークンを計算する
- 2区間のうち片方をプロンプト、もう片方をターゲットとする
- プロンプトのセマンティックトークンと音響トークン、ターゲットのセマンティックトークントークンを入力としてターゲットの音響トークンを出力するように学習
入力の各トークン集合との間には特別なセパレーション(図3の灰色の四角)を入れないと境界部分にアーティファクトが出る。
図だと入力が少々わかりにくいが論文ではそう書いてあった。
実験
詳しくは論文を参照。
セマンティックトークンと音響トークンを作るための自己教師あり学習のモデル(SoundStreamとw2v-BERT)はLibriLight を利用。
ステージ1のPretrainingはLibriLight、BacktranslationではLibriTTSを利用。
ステージ1のfine tuningではLJSpeechを利用。単一話者の24時間のパラレルデータセット。
ステージ2はLibriLightを利用。
各モデルの事前学習ありなしによる明瞭度の変化。事前学習は効果あり。

ステージ1の学習に使うパラレルデータの話者数が、マルチスピーカー出力に与える影響。
ステージ1は単一話者でも問題はない。

話者の正確性。15分と少ないデータ量で他手法にさほど劣らない。

MOS評価


所感
ちょっとVALL-EっぽいTTS。やはり音声合成はARのほうがよいのかな?(VITSとかはfeedforwardだったが)。
いきなりテキストから音声にせずセマンティックトークンという中間表現にするのは、メルスペクトログラムをセマンティックトークンとみなせばFastSpeech + HifiGANとかに近そうではある。
セマンティックトークンのほうがメルスペクトログラムよりも音響情報はだいぶ少なそうだが。
Tortoise TTSでも述べられていたが直接音声波形生成よりVocoderを挟んだほうがよいとのことで直接波形生成は最近少ない?
TTS等音声合成系は画像系と異なりアーキテクチャ設計よりもいかにデータを集めるかが現状重要視されてそうな印象。
そのためにラベル無しのデータをいかにうまく使うかという意味でVALL-EよりもSPEAR-TTSのほうが使い勝手は良さそう。
事前に量子化した特徴をトークンとみなしてシーケンス生成するtaming transformer系の生成が流行りか。
[論文メモ] FREEVC: TOWARDS HIGH-QUALITY TEXT-FREE ONE-SHOT VOICE CONVERSION
テキストを利用しないone-shot可能なVITSベースのVoice Conversion(VC)
arxiv.org
github.com
よくVCではコンテンツとスタイル(話者情報)を分離して再合成するという形式が多い。しかしその多くはコンテンツ情報にスタイルがリークしていたり大量のアノテーション付きデータを必要としたりと問題がある。
またメルスペクトログラムなどの中間特徴を介したvocoderを用いて波形に再構成する(2ステージモデル)のでモデル不一致による劣化もある。
既存手法のVITSは1ステージモデルでvocoderの不一致が起きにくい。
しかし、VITSはコンテンツとスタイルの分離のためにテキストアノテーションのある大量の音声データを必要とするのと、many2manyなVCに限られる問題がある。
これをなんとかしたいというお気持ち
手法
テキストフリーかつone-shotでVCのできるFreeVCを提案。
ベースとなるモデルはVITS。モデルの全体像は図1参照

テキストの代わりとしてここでは自己教師あり学習、WavLMによる特徴を利用する。
WavLMは音声波形を1024次元の特徴に変換する。
にはまだ話者情報が入っているのでInformation Bottleneck(IB)を用いてこれを排除する。
IBはを次元
にしたあとで
と
に変換し
を出力する。
VITSで本来はテキストから得る特徴をこのに置き換える。これによりテキストアノテーションが不要になる。
many2manyを解消するために固定の話者埋め込みを利用するのをやめ話者エンコーダを利用する。
話者エンコーダとしては学習済みモデルを固定で利用するのと、スクラッチで一緒に学習するのを試す。
なおエンコーダはLSTMベースのシンプルなものを利用。
学習
AutoVCでもbottleneckは利用されていて、bottleneckサイズのチューニングが重要と言われていた(大きすぎても小さすぎてもだめ)。
ここではvertical spectrogram-resize(SR)-basedなaugmentationを利用することでコンテンツ抽出を安定させる(図2)。

ランダムなについて、
のときはメルスペクトログラムを周波数方向について縮小し、縮小した部分をパディングする、
のときは周波数方向について拡大し、もとのサイズからはみ出た部分をカットする。
lossについてはVITSからテキストアライメントを取り除くだけ。
予測
VITSによるVCではPosterior EncoderとFlowを用いてコンテンツ情報を生成していたがFreeVCではWavLMから生成する(図2(b)参照)。
実験・結果
データセットはVCTKとLibriTTS。
細かい設定は論文参照。
提案手法としては
- FreeVC-s:事前学習しない話者エンコーダを利用
- FreeVC:学習済み話者エンコーダを利用
- FreeVC(w/o SR):学習済み話者エンコーダを利用しつつSR-basedなaugmentationをしない
を比較。
実験結果は表1

全体的に提案手法が良い結果。
話者エンコーダが学習済みかどうかはあまり影響がなさそう。
SR-based augmentationの効果はそれなりにありそう。
WER、CER、F0-PCCの比較結果が表2。

提案手法が全体に優れている。とくにF0-PCCが高い。
所感
VITSベースのVCで、以前似たようなことをやってみたがうまくいかなかった。information bottleneckの効果が大きそうな気がする。
予測時にposterior encoderを利用しないというのは少々面白い構造。どちらも入力はもと音声で話者情報が入り込んでしまう可能性があり、どちらがより話者情報が少ないかというかんじか?せっかくならposterior encoderからのVCも比較してほしかった。
[論文メモ] Simple Open-Vocabulary Object Detection with Vision Transformers
ECCV2022
検出するオブジェクトの指定に自然言語を使ったend-to-endなobject detectionモデルの提案
既存のobject detectionの多くはスケーリングできず、検出可能なオブジェクトが固定されているクローズドボキャブラリーの問題がある。
近年ではCLIPのようなimageとtextの関係を学習できるモデルも発展してzero shotタスクに応用されてきている。
このようなimage-textモデルを使ってzero shotのオープンボキャブラリーなobject detectionが実現できないか?というお気持ち。
オープンボキャブラリーな検出モデル、 OWL-ViTを提案(Vision Transformer for Open-World Localization)。
手法

まず大量の画像とテキストペアで学習したimage-textモデルを作成する。CLIPと同じ感じ。
画像のエンコーダとしてVision Transformer(ViT)を、テキストのエンコーダとしても似たようなアーキテクチャを採用する。
テキストエンコーダはCLIPと同じくEOSトークンを代表のトークンとして利用。
画像エンコーダはCLIPと異なり、各パッチから生成された最終的なトークンをmultihead attention pooling(MAP)で集約しprojectionしたものを代表のトークンとする。
学習はCLIPと同じくペア同士を近づけ、ペア出ないもの同士は遠ざけるcontrastive learning。
次にdetectorの学習。
上記で作ったimage-textモデルを使ってオープンボキャブラリーなobject detectionモデルを構築する。
まずは画像エンコーダ側の処理。
画像エンコーダの出力からMAPを取り除きクラス分類とBounding Box(BBox)のためのヘッドを追加する。
MAPを取り除いたのでパッチ(トークン)の数だけ出力が得られることに注意。
クラス分類のヘッドは各トークンをテキストエンコーダの次元に変換する。
BBoxのヘッドは各トークンにおけるオブジェクトの位置情報(x,y,w,h)を出力。
次にテキストエンコーダ側の処理
まず検出したいオブジェクトをカテゴリ名や説明文で指定し、それをテキストエンコーダで埋め込んだものをクエリとする。
これらのクエリと各トークンのクラス予測の類似度から、各トークンのクラス確率を計算する。
BBoxは対応するトークンのものを利用する。
学習はDERTのbipartite matching lossをロングテール・オープンボキャブラリーに対適応させたものを利用。
巨大なデータセットではラベル付けの問題で各オブジェクトに複数ラベルがついている事がある。
そこでsoftmax cross entropyではなくfocal sigmoid cross entropyを採用。
また各画像がすべてのカテゴリについてにラベルがあるわけでは無く、positive(存在する)とnegative(存在しない)の両方が提供されている。
学習時はこの2つを利用しつつ、データ中の頻度に比例してランダムにカテゴリを抽出し疑似的なnegativeラベルを追加しnegativeラベルが1枚の画像に最低50のnegativeラベルが含まれるようにする。
実験・結果
画像エンコーダとしてはViTはスタンダードなものを利用。
テキストエンコーダは基本的に12層、512次元の中間特徴、2048のMLP、8ヘッドのものを利用。
image-textモデルは3.6Bの画像テキストペアで事前学習。
detectionの学習は2M程度の画像。
その他の細かい設定は論文参照。
zero-shotの結果。提案手法はOWL-ViT

one-shotの結果。
必ずしもテキストをクエリにする必要はなく、画像を埋め込んで、それをクエリとすればone-, few-shotが実現できる。


CLIP部分(Image-Level)の精度とobject detectionへtransfer後の精度の関係。
object detectionでよい結果を出したモデルはImage-Levelでも良い結果だが、逆は必ずしもそうではない。

[論文メモ] ControlVC: Zero-Shot Voice Conversion with Time-Varying Controls on Pitch and Rhythm
時間レベルでピッチやリズムの調整ができるZero-Shot Voice Conversionの提案
既存のVoice Conversion(VC)システムはピッチシフトを提供していても発話レベルのため時間レベルのピッチシフトができないのでなんとかしたいというお気持ち。
手法
目的は時間レベルでのピッチ・リズムの調整ができるノンパラレルのzero-shot VC。
システム全体像は図1参照。

VCシステムは以下の3つのステージからなる。
- TD-PSOLAによる前処理
- 前処理結果からの特徴抽出
- HiFi-GANによる音声合成
前処理ではピッチの埋め込み、コンテンツ情報の抽出、話者埋め込みの抽出の3つを行う。
ピッチ埋め込み
ピッチ情報はYAAPT アルゴリズムというものを利用する。
リズム変更した音声にYAAPTを適用することでピッチシーケンスが得られる。
ピッチシーケンスはVQ-VAEにより埋め込み表現になる。
VQ-VAEはピッチの再構成で学習しておく。
コンテンツ情報
コンテンツ情報はパブリックに利用可能なLibriSpeechで学習済みのHuBERTモデルを利用する。
HuBERTに音声を入力することでフレームレベルの中間特徴のシーケンスが得られる
しかしこの中間特徴には話者情報が含まれている可能性があるのでそのまま使えない。
そこで予めHuBERTにLibriSpeechのデータを入力した抽出特徴に対してmini-batch K-meansを適用してセントロイドを取得しておく。
直接中間特徴を利用するのではなくセントロイドに置き換えることで話者情報を排除する。
なおセントロイドはK=100。
話者埋め込み
zero-shotで話者変換するために話者埋め込みのネットワークを作成する。
アーキテクチャは既存手法を参考にしたLSTM x 2 + FCのシンプルな構造。
VoxCelebとLibrispeechデータセットをGE2E lossで学習し、これを利用する。
HiFi-GAN
ピッチ埋め込み、コンテンツ情報、話者埋め込みの3つを入力として音声を合成する。
話者埋め込みに関してはフレームサイズ分のコピーを行う。
アーキテクチャに関しては、入力がメルスペクトログラムから上記の3つに変更しただけで基本そのまま。
リズム・ピッチ変更
まずリズムの変更。
ピッチ等を保ったままリズム変更をするためにtime-domain pitch synchronous overlap and add (TD-PSOLA)を利用する。
PD-PSOLAによりリズム変更された音声が得られる。
次にリズム変更された音声からYAAPTを利用してピッチ情報を得る。
あとはこのピッチ情報からピッチ埋め込み、リズム変更した音声からコンテンツ情報、ターゲット話者から話者埋め込みをそれぞれ抽出してHiFi-GANで音声合成するだけ。
実験・結果
データセットはCSTR VCTK。110人の話者のうち、100人を学習に10人(男5女5)をテストに利用。
ベースラインが存在しないのでTD-PSOLAにlinear predictive coding (LPC)とAutoVCを用いた2つの変換方法を作成し評価。



所管
正直ほとんど想像通りの手法であまり目新しさはなかった。
時間レベルのピッチ・リズム変更の既存手法がないからとはいえ比較対象がひどすぎるのでは?
発話レベルでのピッチシフトをしての既存手法と比較もすべきな気がする。
HuBERTの中間特徴をK-meansでクラスタリングし、事前にセントロイドを用意して埋め込むのは使えそう。
[論文メモ] Hydra Attention: Efficient Attention with Many Heads
CADL2022
効率的なmulti-head attentionの提案

transformerのattentionはトークンの数の2乗オーダーの計算コストを必要とする。
そのためVision Transformer(ViT)などで高解像度の画像を扱うとトークン数が膨大になり、計算のほとんどをattention matrixの生成と適用に費やすことになる。
これをなんとかしたいというお気持ち。
提案手法
一般的なsoftmax self-attentionは以下の式(1)

トークン数を、特徴量の次元数を
とすると計算量は
。
softmaxをと
の類似度を図る関数
として一般化したのが以下の式
非線形関数で
を分解する。
を先に計算することで、計算量は
になる。
これが1つのヘッドに相当。計算量はTについて線形になったが一般になのでまだ高コスト。
基本self-attentionはmulti-headで扱われる(MSA)。
ヘッド数をは大体6~16で、
の特徴量を
に分割して行う。
コレがmulti-head linear attention(MLA)
multi-headはもとのattentionと計算量は変わらないが、先程のように非線形関数で分解することで計算量をに抑えられる。
なのでヘッド数を増やすと高速化できるが精度とのトレードオフで、実際いくつくらいまで増やしていいのか。
調査のためImageNet-1kをDeiT-Bで学習した結果が以下の図2。横軸が。

MSAはで、MLAは
でメモリ不足。
MLAはでもある程度精度を保っているが、これは
でただのスカラ特徴。
類似度関数としてsoftmaxを使わなければをスケールアップできそう(ここではcosine similarityを採用)。
そこでとした hydra trick を導入する。
なお、
をアダマール積として
は
全体に適用することに注意(
は列ベクトルなので)。
HydraはMSAとは全く異なる動作で、すべてのトークンを集約したグローバルな特徴ベクトルに対して
でゲーティングしている。
計算量は。
その他のの手法でAttention-Free TransformerやPloyNLなどがあるが、Hydra Attentionはこれらの一般化と捉えることができる(論文参照)。
実験・結果
アーキテクチャは基本的にDeiT-B、データセットはImageNet-1k。
としてcosine similarityを採用(
はL2 normになる)。
cosine similarity以外について調査した結果が表1。

cosine similarityが最もよく、MSAのそもそもの性質を変化させてるのが原因と考えられる。
MSAは重みの和が1になるようになっているがそれらがそもそも望ましい性質では無いのかもしれない。
Hydra Attentionでの置き換え位置の調査。
すべてを置き換えるのではなく一部を置き換えた方がいいのではというお気持ち(よくあるグローバルを扱うAttention系は後半の層を置き換えると良い的なのが多い)。
Hydra Attentionはグローバルな情報を扱うためその可能性は高い。
実験結果が図4。

はじめの層の置き換え(forward)は精度が低下しているが、後ろの層の置き換え(Backward)は精度が1%近い改善もあった。
既存手法との比較

他のの手法に比べ精度低下が少ない。
後半2層の置き換えは速度向上は少ないが精度が向上。
所感
ヒドラという名前がセンスがある。
すべてを置き換えると精度に影響が出るが、少し利用するなら精度・速度両方に恩恵があるそうなので良さそう。
実装も手軽そうなのも良い。
ただViTによる画像分類の結果だけなので他のタスクでうまくいくのかは気になるところ。
[論文メモ] DeID-VC: Speaker De-identification via Zero-shot Pseudo Voice Conversion
Interspeech 2022
架空の話者へのzero-shot Voice Conversion
音声を使ったサービスというのが増えてくると、音声のセキュリティやプライバシーの問題が出てくる(攻撃者によって音声が盗まれ音声認証等に利用される可能性等)。
こういったことを低減するために、発話の中身を変えず話者情報を削除・難読化したいというお気持ち。
手法
ベースはAutoVCで、そこに疑似話者を追加する。
AutoVC
AutoVCは主に3つのモジュールからなる。
1つ目がコンテンツエンコーダ でメルスペクトログラムを入力としコンテンツ特徴に埋め込む。
2つ目が話者エンコーダ で、メルスペクトログラムを入力して話者特徴を出力するD-Vectorをベースのもの。
3つ目はデコーダ でエンコーダによるコンテンツ特徴と話者特徴を元にターゲットのメルスペクトログラムを出力する。
目的関数は以下
:メルスペクトログラム
:
で埋め込んだコンテンツ特徴
:話者aの発話を話者bに変換したメルスペクトログラム
:

AutoVCのパイプラインは以下の図1。

提案手法
提案手法名はDeID-VC(de-identificationのDeIDと思われ)。
一般的にVoice Conversion(VC)はコンテンツ情報と話者情報
を分離することが重要とされる。
AutoVCではの出力部分を適切なサイズのボトルネックにすることでCとSに分離させている。
だが、適切なボトルネックサイズというのはデータセットに依存するためデータセットによっては分離がうまくいかない。
その結果Cに話者情報も残り、再構成lossについてもSを利用せずCからの生成になりVCとして機能しなくなる。
そこでCとSの分離を促すために以下の2つのloss追加する。

言ってしまうとVCした音声はそれぞれもととのなったCとSを保存していてほしいという制約。
ということで総合的なlossとパイプラインは以下。


ここまではAutoVCの改善で次は疑似話者生成について。
D-Vectorを用いてのVCなので実際発話を利用し、その話者に似せることになる。疑似話者のベクトルを作るにしても実際に存在しうる話者っぽくなってほしい。
そこで話者特徴を使ったVAEを学習する。
図3がパイプライン

VAEの目的関数は以下。
:再構成loss
:コサイン類似度
:KLダイバージェンス

D-Vectorの出力である話者情報をを入出力としてVAEを学習する。そしてデコーダ部分を利用することでガウシアンから疑似話者ベクトルを生成できる。
実験・結果
データセットはWSJコーパス。VAEに関してはVoxCeleb1と2で学習しVCTKとWSJで評価。
DeID-VCの学習はAutoVC部分とVAE部分の2つに分けて行う。
評価指標はWord Error Rate (WER)、Equal Error Rate (EER)と30人によるMOS。
実験結果が表1。SxUのSとUはSeenとUnseen。PはPseudo Target。

VAEの再構成のloss。

所感
AutoVCにcycle consistency的なものの追加とVAEによる話者生成。
cycle consistency的なものは誰もやってこなかったのか?論文のメインの主張は疑似話者生成なので別によいが。
VAEで話者ベクトルを再構成するのは少々強引な気もする。理屈はわかるけどうーん。