[論文メモ] UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
INTERSPEECH 2021
高速・高品質なVocoder、UnivNetを提案
多くのVocoderは帯域制限したメルスペクトログラムから音声波形を生成する。
しかし、一部のモデルでは生成結果のスペクトログラムがオーバースムージングされる問題がある。
これをなんとかしたい。

手法
主にDiscriminatorを使って解決する。
Generator  について
について
は図1(a)でMelGANに倣った形式。
ノイズ を入力、ログメルスペクトログラム
を条件として音声波形
を生成する。
と
は同じ長さ。
生成を高速かつ高品質にするためにlocation-variable convolution (LVC)を導入。
LVCはを入力としたKernel Predictorによって生成されたカーネルを使ってconvolutionを行う。
LVCはによる局所的な情報を適切に扱えるらしい。
residual connectionの前に活性化関数としてgated activation unit(GAU)を追加することでマルチスピーカーの性能が改善。
Discriminator  について
について
図1(b)のようにDiscriminatorは複数ある。
大まかには2つあり、1つ目はmulti-resolution spectrogram discriminator (MRSD)。
個のSTFTのパラメータを用意し、それらでSTFTした結果を各Disciriminatorの入力とする。
既存手法はフィルタバンクを利用して一つのスペクトログラムを分割し識別するが、
提案手法はフルバンドで高解像の音声を生成することを目的としている。
2つ目はHiFiGANで提案されたmulti-period waveform discriminator(MPWD)。
loss
least-squares GANのadversarial lossとauxiliary loss 。
はspectral convergence loss
と log STFT magnitude loss
からなる。これはMulti-band MelGANと同じ。

はフロベニウスノルム、
はL1ノルム。
全体として以下のlossになる。

は
番目のMRSDとMPWDで
はDiscriminatorの合計、
はハイパラ。
実験・結果
データセットはLibriTTSデータセット。
の中間のチャンネルサイズ違いで2つモデルを用意(UnivNet-c16とUnivNet-c32)
評価指標はPESQ(高いほど良い)、スペクトログラムでのRMSE(小さいほどいい)、MOSの3つ。
結果が表2で、既存手法より優れていそう。速度もそれなり。

ablations。
各コンポーネントの有無での性能を評価(MOS)。

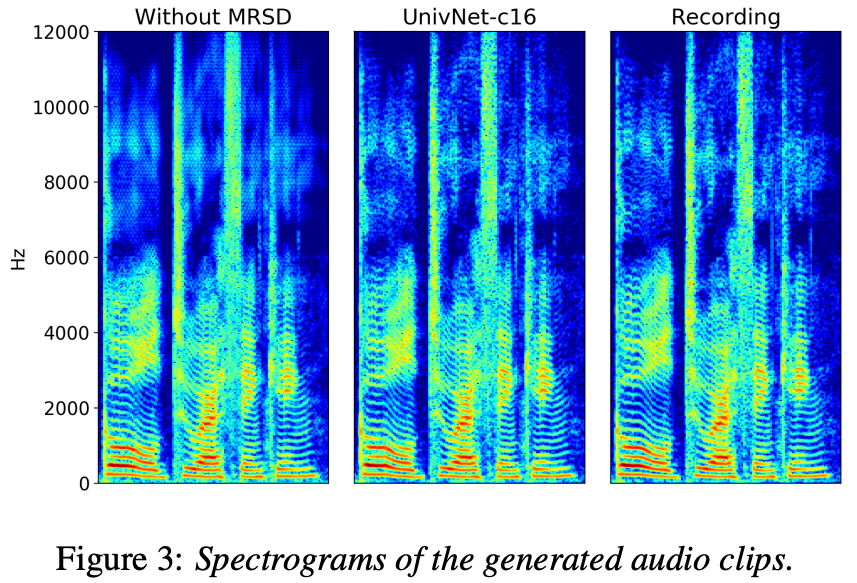
MRSDの効果。より細かいスペクトログラムになっていそう。
所感
TorToiSe TTSに採用されていたので読んだ。
個人的にHiFiGANがベースラインなのでそれより高速かつ高精度そうなので良さそう。
ただ、HiFiGANはどうやら自前で学習したっぽいので比較の信頼度は微妙かも。
また、個人的にVocGANもかなり良かったので、VocGANとも比較して欲しかった(あとBDDM)。